Learning a Generative Meta-Model of LLM Activations




Abstract
Training diffusion models on neural network activations creates meta-models that learn internal state distributions and improve intervention fidelity without restrictive structural assumptions.
Existing approaches for analyzing neural network activations, such as PCA and sparse autoencoders, rely on strong structural assumptions. Generative models offer an alternative: they can uncover structure without such assumptions and act as priors that improve intervention fidelity. We explore this direction by training diffusion models on one billion residual stream activations, creating "meta-models" that learn the distribution of a network's internal states. We find that diffusion loss decreases smoothly with compute and reliably predicts downstream utility. In particular, applying the meta-model's learned prior to steering interventions improves fluency, with larger gains as loss decreases. Moreover, the meta-model's neurons increasingly isolate concepts into individual units, with sparse probing scores that scale as loss decreases. These results suggest generative meta-models offer a scalable path toward interpretability without restrictive structural assumptions. Project page: https://generative-latent-prior.github.io.
Community
Check out our codebase; everything’s ready to go! The code even runs on Nvidia RTX 4090s.
Page: http://generative-latent-prior.github.io
Code: https://github.com/g-luo/generative_latent_prior
Paper: https://arxiv.org/abs/2602.06964

This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- DLM-Scope: Mechanistic Interpretability of Diffusion Language Models via Sparse Autoencoders (2026)
- Predictive Concept Decoders: Training Scalable End-to-End Interpretability Assistants (2025)
- CASL: Concept-Aligned Sparse Latents for Interpreting Diffusion Models (2026)
- Supervised sparse auto-encoders as unconstrained feature models for semantic composition (2026)
- YaPO: Learnable Sparse Activation Steering Vectors for Domain Adaptation (2026)
- Beyond Activation Patterns: A Weight-Based Out-of-Context Explanation of Sparse Autoencoder Features (2026)
- Sparse CLIP: Co-Optimizing Interpretability and Performance in Contrastive Learning (2026)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend
Here are the main results from the paper "Learning a Generative Meta-Model of LLM Activations," which introduces **GLP (Generative Latent Prior)**—a diffusion model trained on LLM activations.
1. Core Concept: Generative Meta-Modeling
The paper proposes training diffusion models directly on LLM residual stream activations to learn the underlying distribution of internal states without imposing structural assumptions (like linearity or sparsity). This creates a "meta-model" that can serve as a learned prior for downstream interpretability tasks.
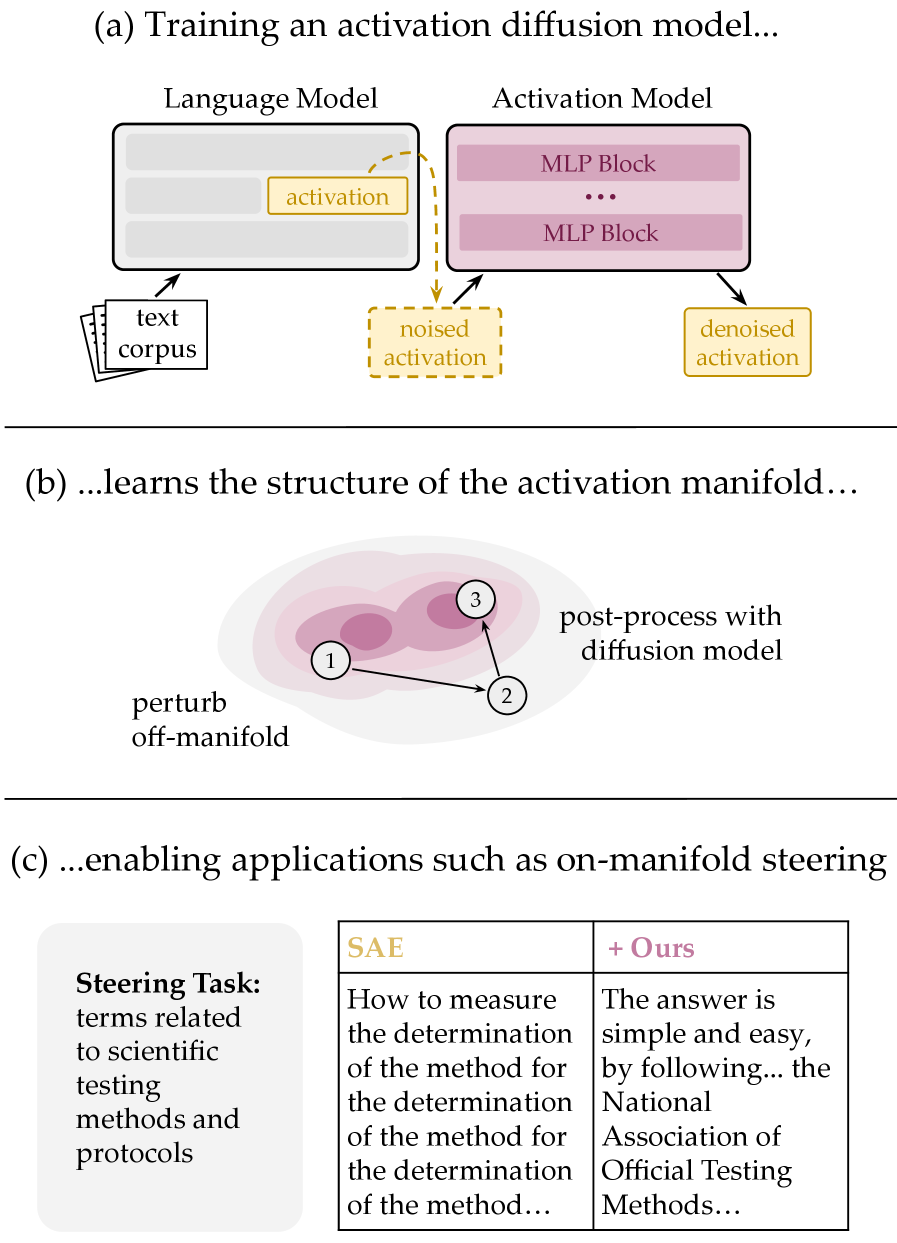
Figure 1: GLP is an activation diffusion model trained on LLM residual streams. It serves as a prior for on-manifold steering and exhibits reliable scaling laws.
2. Scaling Laws: Predictable Improvement with Compute
A key finding is that GLP training follows smooth power-law scaling, and crucially, diffusion loss reliably predicts downstream utility.
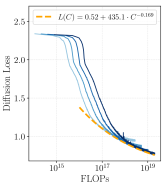
Figure 2: GLP scales predictably with compute. (a) Diffusion loss follows a power law with estimated irreducible error of 0.52. (b) On-manifold sentiment steering performance improves with compute, tracking the loss. (c) 1-D probing performance for 113 binary tasks also improves with compute.
The scaling analysis (models from 0.5B to 3.3B parameters trained on 1B activations) shows:
- Loss follows the form $L(C) = E + A \cdot C^{-\alpha}$ with $E = 0.52$ (irreducible error)
- Each 60× increase in compute halves the gap to the floor
- Both steering and probing performance correlate strongly with diffusion loss
3. On-Manifold Steering: Preserving Fluency During Intervention
Activation steering often pushes activations "off-manifold" (into unrealistic regions of activation space), degrading output fluency. GLP solves this by post-processing steered activations through diffusion sampling (an activation-space analog of SDEdit).
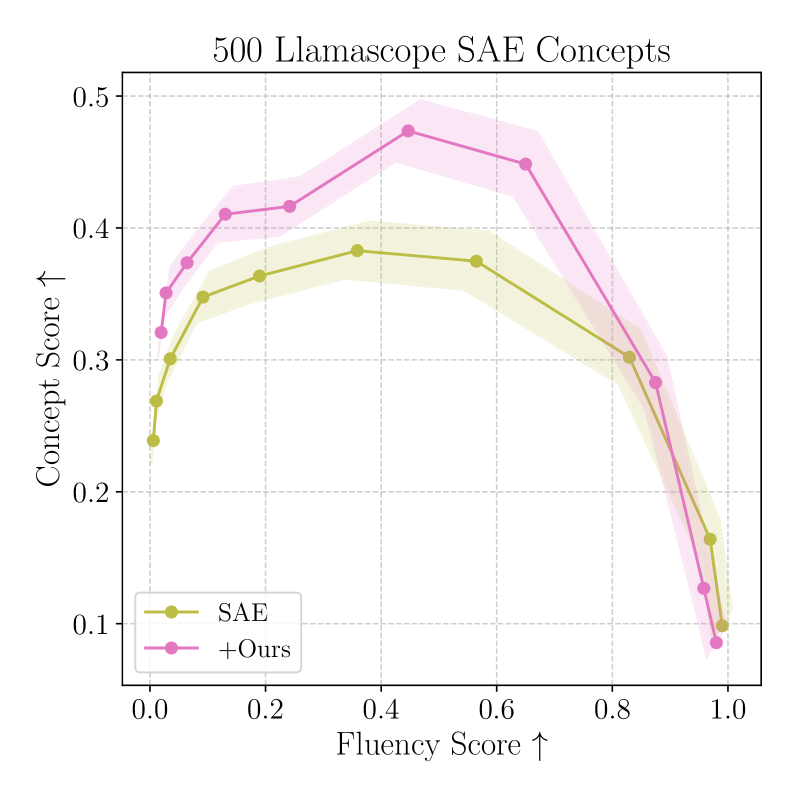
Figure 4: The on-manifold steering algorithm. Given a steered activation, noise is added and then removed via GLP denoising, projecting the activation back onto the learned manifold while preserving semantic content.
Results on Steering Tasks:
Improving SAE Steering: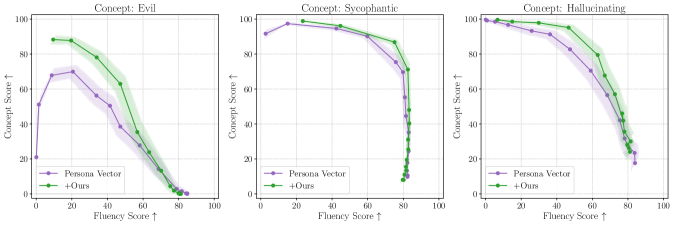
Figure 5: GLP post-processing expands the Pareto frontier of concept strength vs. fluency for SAE feature steering (Llama8B-Base).
Persona Elicitation: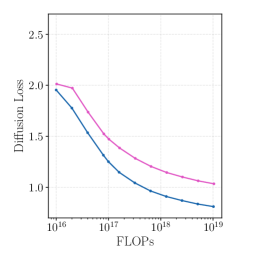
Figure 6: GLP post-processing improves persona vector steering for behavioral traits (evil, insecure, power-seeking) in Llama8B-Instruct, achieving higher concept scores at the same fluency level.
4. Generation Quality: Near-Indistinguishable Activations
GLP generates activation samples that are statistically nearly identical to real LLM activations, as verified by multiple metrics:
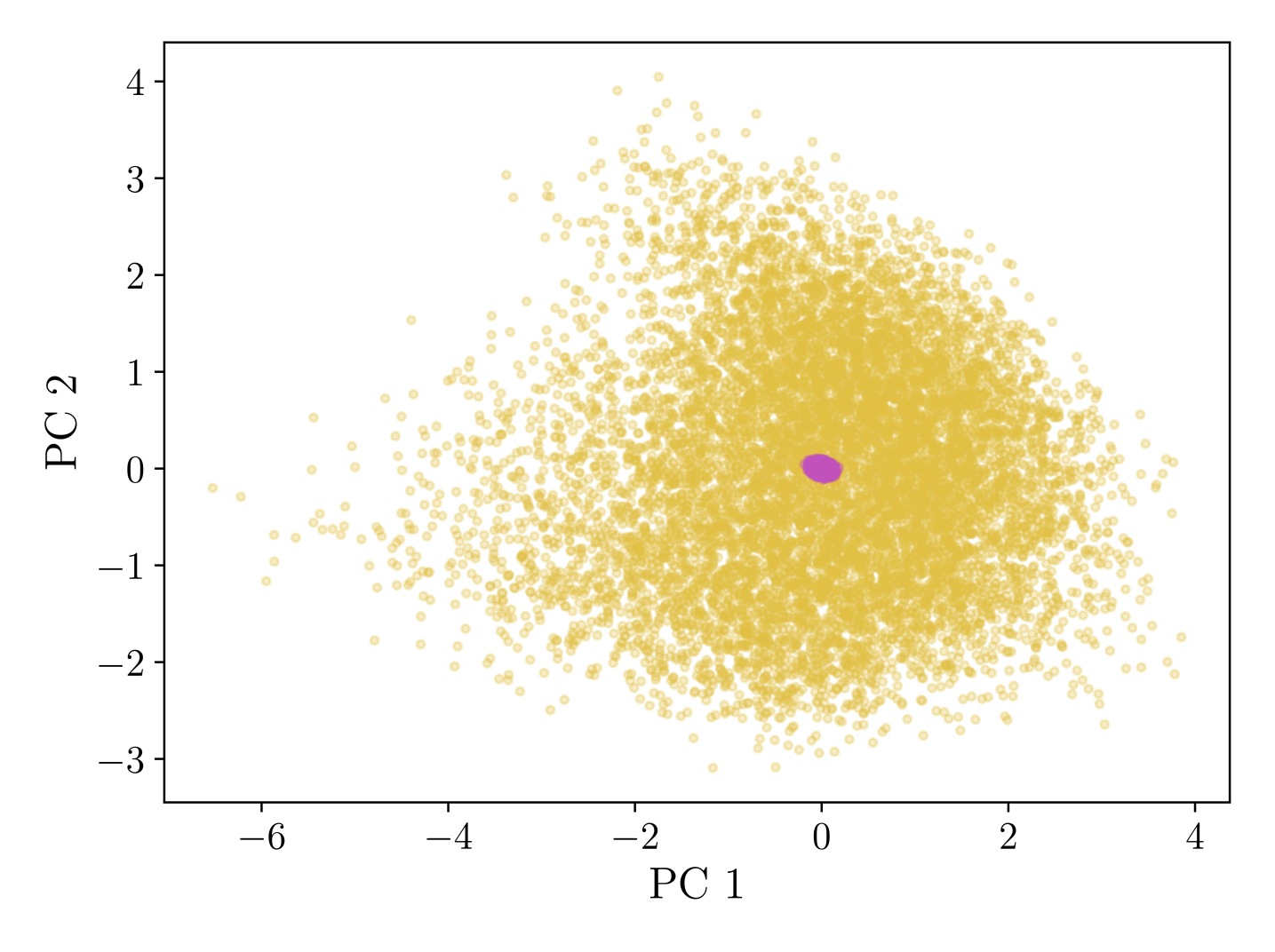
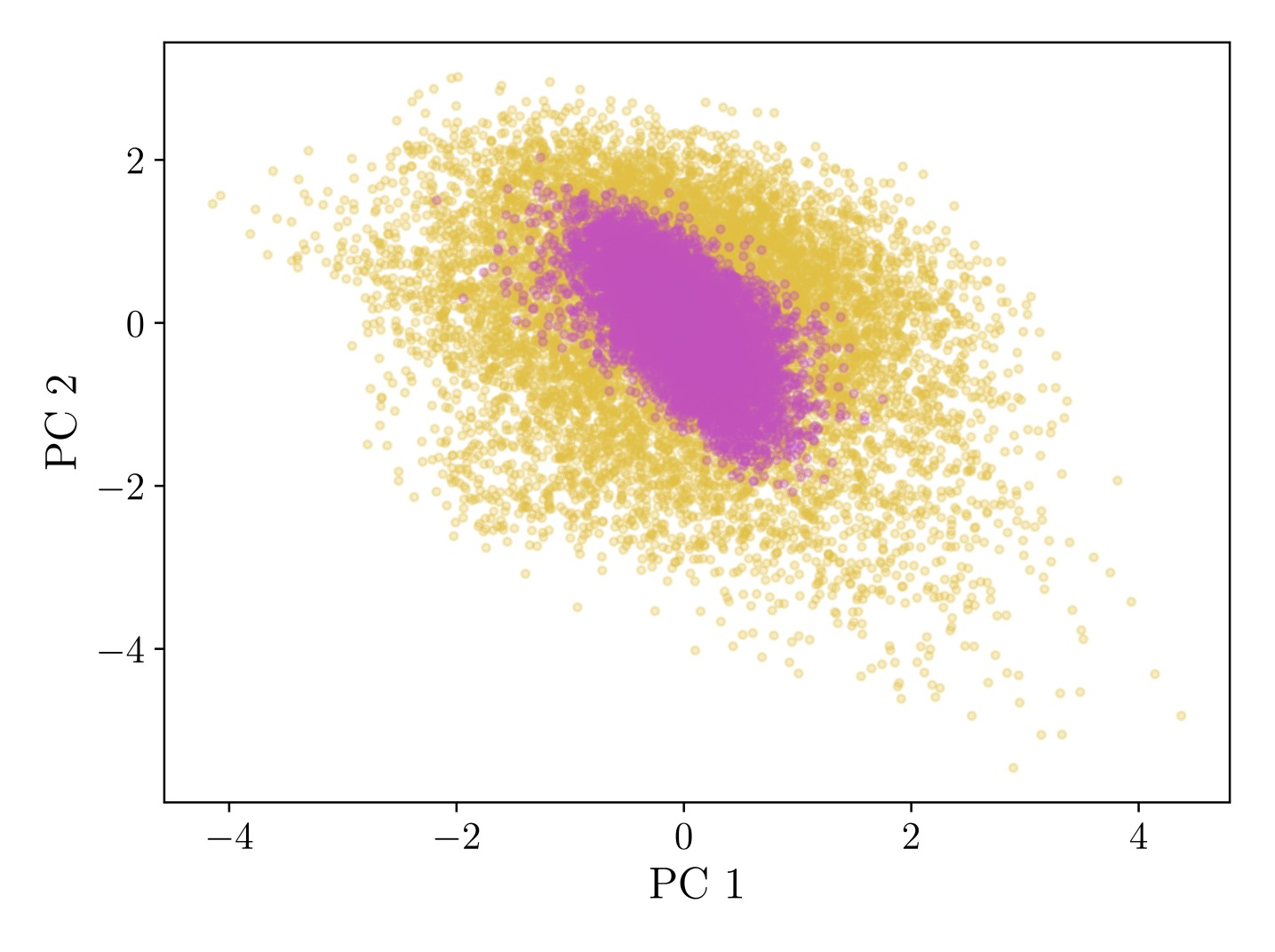
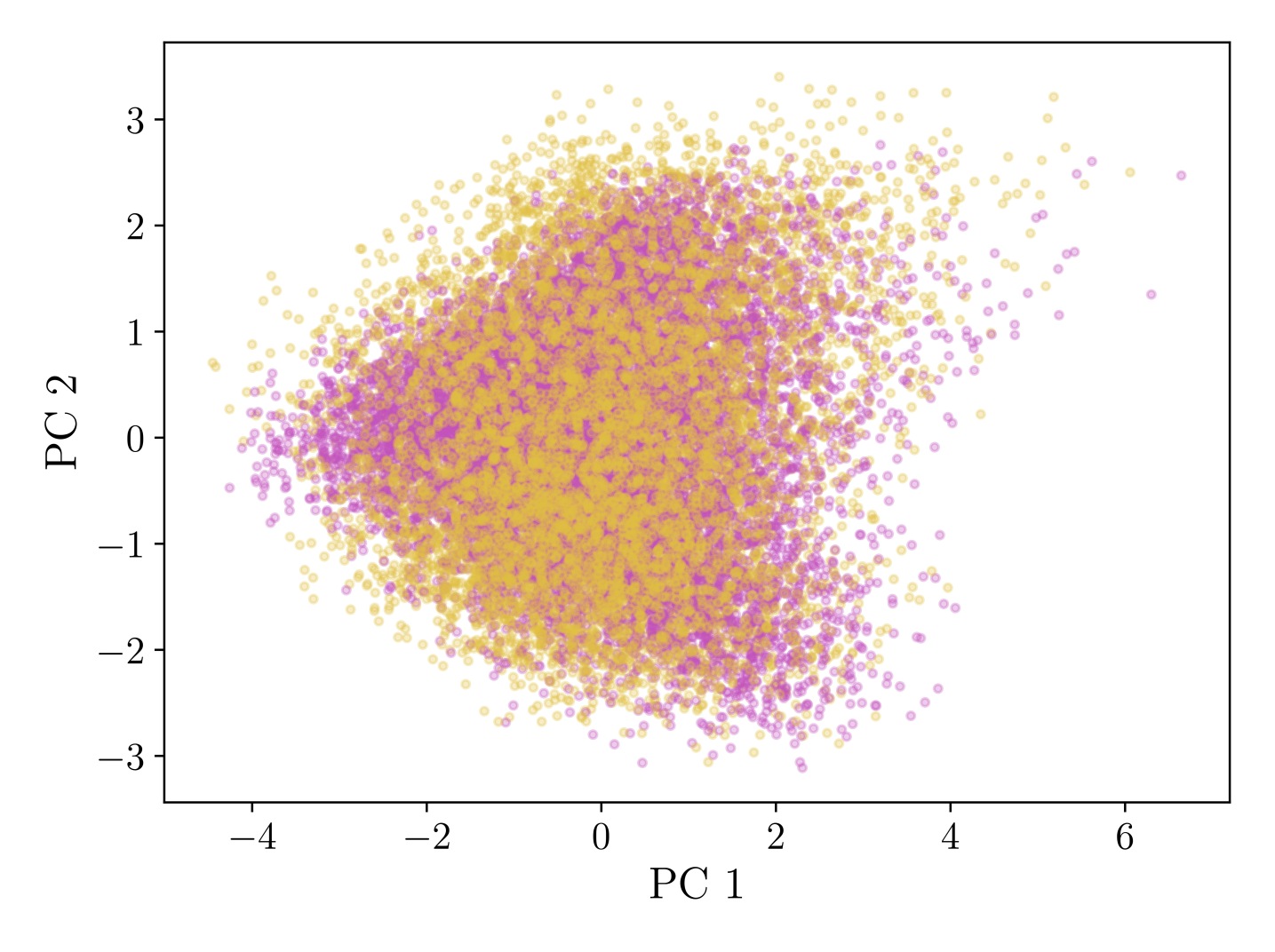
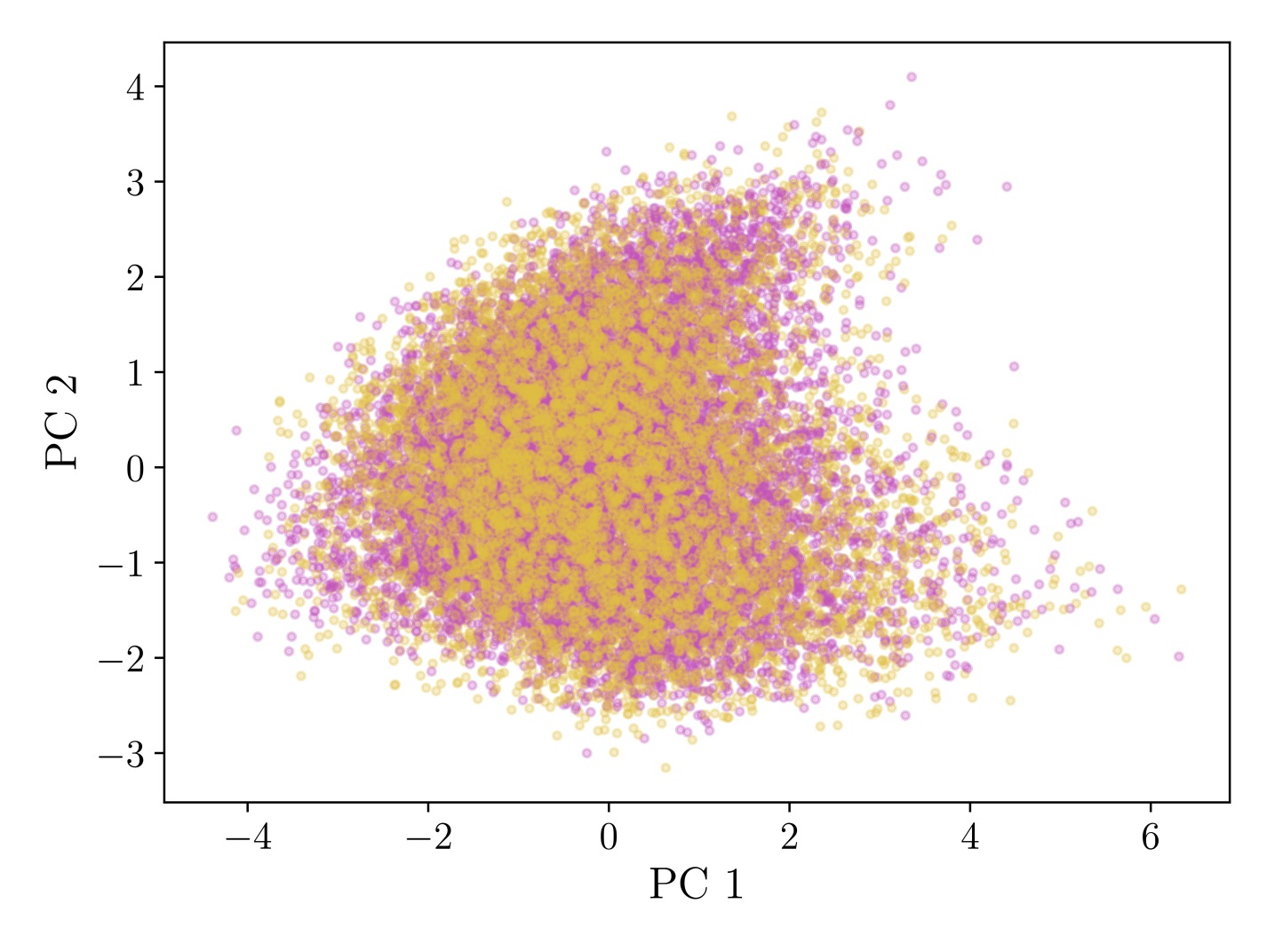
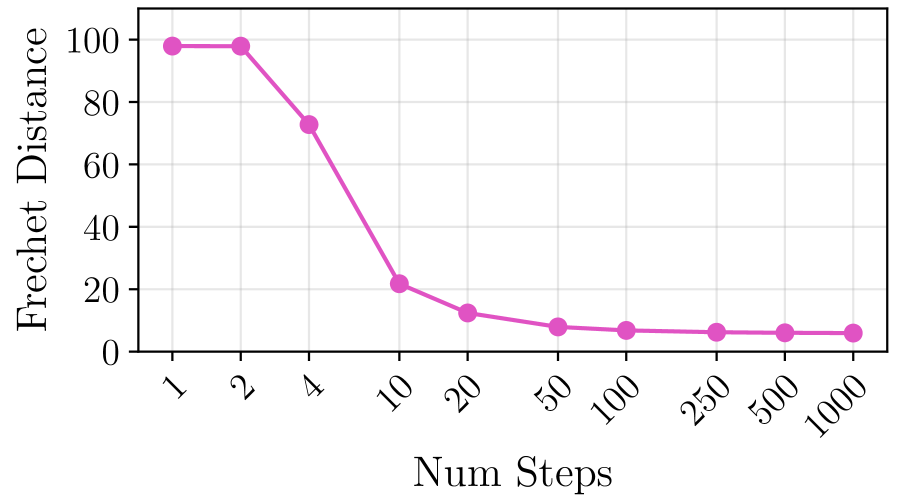
Figure 3: (a-d) PCA visualizations showing convergence of generated (pink) vs. real (yellow) activations as sampling steps increase. (e) Frechet Distance quantitatively confirms generation quality, with ~20 steps needed for convergence.
Key Metrics:
- Frechet Distance: GLP achieves lower FD than SAE reconstructions (despite SAEs having the advantage of being initialized from real activations vs. GLP starting from noise)
- Delta LM Loss: Surprisingly, GLP achieves better reconstruction loss than a comparable SAE (0.21 vs 0.28 for Llama8B), despite not being explicitly trained for reconstruction
5. Interpretability: Superior 1-D Probing via "Meta-Neurons"
GLP's intermediate representations ("meta-neurons") isolate interpretable concepts into individual units more effectively than existing methods.
Table 4: 1-D Probing Performance
| Method | Llama1B AUC | Llama8B AUC |
|---|---|---|
| GLP (Ours) | 0.89 | 0.87 |
| Raw Layer Output | 0.82 | 0.83 |
| SAE Features | 0.80 | 0.82 |
| Raw MLP Neurons | 0.84 | 0.84 |
Table 4: GLP meta-neurons substantially outperform SAE features and raw activations on 1-D probing across 113 binary classification tasks.
Notable finding: The Llama1B GLP (0.5B-3.3B parameters) outperforms all Llama8B raw activation baselines, suggesting that training a GLP can be more effective than scaling the base LLM for achieving interpretable representations.
Qualitative Examples:
Meta-neurons discovered via 1-D probing show consistent activation patterns:
- A "baseball" meta-neuron activates on baseball terms
- A "contradiction" meta-neuron activates on expressions of disagreement
Summary of Key Contributions
- Scalable Alternative to Structural Assumptions: Unlike PCA or SAEs, GLP imposes no linearity/sparsity constraints yet improves with predictable scaling
- Practical Utility: Diffusion loss serves as a reliable proxy for downstream task performance (steering and probing)
- On-Manifold Regularization: Post-processing with GLP improves steering fluency across SAE features, DiffMean, and persona vectors
- Superior Feature Isolation: Meta-neurons outperform SAE features on 1-D probing, suggesting better concept disentanglement
The paper concludes that generative meta-models offer a promising path toward LLM interpretability that improves predictably with compute, without requiring hand-crafted structural assumptions.
Models citing this paper 6
Browse 6 models citing this paperDatasets citing this paper 5
Browse 5 datasets citing this paperSpaces citing this paper 0
No Space linking this paper
Collections including this paper 0
No Collection including this paper