
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 3.09B | node_id stringlengths 18 24 | number int64 2 7.59k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 1
value | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC]date 2020-04-14 18:18:51 2025-05-27 13:46:05 | updated_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2025-06-09 22:00:16 | closed_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2025-06-06 16:12:36 | author_association stringclasses 4
values | type float64 | active_lock_reason float64 | sub_issues_summary dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | draft float64 | pull_request null | time_to_close_hours float64 0.01 28.8k | __index_level_0__ int64 18 7.53k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5645/comments | https://api.github.com/repos/huggingface/datasets/issues/5645/events | https://github.com/huggingface/datasets/issues/5645 | 1,627,108,278 | I_kwDODunzps5g-7O2 | 5,645 | Datasets map and select(range()) is giving dill error | {
"avatar_url": "https://avatars.githubusercontent.com/u/90728105?v=4",
"events_url": "https://api.github.com/users/Tanya-11/events{/privacy}",
"followers_url": "https://api.github.com/users/Tanya-11/followers",
"following_url": "https://api.github.com/users/Tanya-11/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"It looks like an error that we observed once in https://github.com/huggingface/datasets/pull/5166\r\n\r\nCan you try to update `datasets` ?\r\n\r\n```\r\npip install -U datasets\r\n```\r\n\r\nif it doesn't work, can you make sure you don't have packages installed that may modify `dill`'s behavior, such as `apache-... | 2023-03-16T10:01:28Z | 2023-03-17T04:24:51Z | 2023-03-17T04:24:51Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I'm using Huggingface Datasets library to load the dataset in google colab
When I do,
> data = train_dataset.select(range(10))
or
> train_datasets = train_dataset.map(
> process_data_to_model_inputs,
> batched=True,
> batch_size=batch_size,
> remove_columns... | {
"avatar_url": "https://avatars.githubusercontent.com/u/90728105?v=4",
"events_url": "https://api.github.com/users/Tanya-11/events{/privacy}",
"followers_url": "https://api.github.com/users/Tanya-11/followers",
"following_url": "https://api.github.com/users/Tanya-11/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5645/timeline | null | completed | null | null | 18.389722 | 1,985 |
https://api.github.com/repos/huggingface/datasets/issues/5641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5641/comments | https://api.github.com/repos/huggingface/datasets/issues/5641/events | https://github.com/huggingface/datasets/issues/5641 | 1,625,942,730 | I_kwDODunzps5g6erK | 5,641 | Features cannot be named "self" | {
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"events_url": "https://api.github.com/users/alialamiidrissi/events{/privacy}",
"followers_url": "https://api.github.com/users/alialamiidrissi/followers",
"following_url": "https://api.github.com/users/alialamiidrissi/following{/other_user}"... | [] | closed | false | null | [] | null | [] | 2023-03-15T17:16:40Z | 2023-03-16T17:14:51Z | 2023-03-16T17:14:51Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi,
I noticed that we cannot create a HuggingFace dataset from Pandas DataFrame with a column named `self`.
The error seems to be coming from arguments validation in the `Features.from_dict` function.
### Steps to reproduce the bug
```python
import datasets
dummy_pandas = pd.DataFrame([0... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5641/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5641/timeline | null | completed | null | null | 23.969722 | 1,989 |
https://api.github.com/repos/huggingface/datasets/issues/5639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5639/comments | https://api.github.com/repos/huggingface/datasets/issues/5639/events | https://github.com/huggingface/datasets/issues/5639 | 1,625,737,098 | I_kwDODunzps5g5seK | 5,639 | Parquet file wrongly recognized as zip prevents loading a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2023-03-15T15:20:45Z | 2023-03-16T13:40:14Z | 2023-03-16T13:40:14Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When trying to `load_dataset_builder` for `HuggingFaceGECLM/StackExchange_Mar2023`, extraction fails, because parquet file [devops-00000-of-00001-22fe902fd8702892.parquet](https://huggingface.co/datasets/HuggingFaceGECLM/StackExchange_Mar2023/resolve/1f8c9a2ab6f7d0f9ae904b8b922e4384592ae1a5/data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5639/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5639/timeline | null | completed | null | null | 22.324722 | 1,991 |
https://api.github.com/repos/huggingface/datasets/issues/5638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5638/comments | https://api.github.com/repos/huggingface/datasets/issues/5638/events | https://github.com/huggingface/datasets/issues/5638 | 1,625,564,471 | I_kwDODunzps5g5CU3 | 5,638 | xPath to implement all operations for Path | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
" I think https://github.com/fsspec/universal_pathlib is the project you are looking for.\r\n\r\n`xPath` has the methods often used in dataset scripts, and `mkdir` is not one of them (`dl_manager`'s role is to \"interact\" with the file system, so using `mkdir` is discouraged).",
"Right is there a difference betw... | 2023-03-15T13:47:11Z | 2023-03-17T13:21:12Z | 2023-03-17T13:21:12Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Current xPath implementation is a great extension of Path in order to work with remote objects. However some methods such as `mkdir` are not implemented correctly. It should instead rely on `fsspec` methods, instead of defaulting do `Path` methods which only work locally.
### Motivation
I'm using... | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5638/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5638/timeline | null | completed | null | null | 47.566944 | 1,992 |
https://api.github.com/repos/huggingface/datasets/issues/5634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5634/comments | https://api.github.com/repos/huggingface/datasets/issues/5634/events | https://github.com/huggingface/datasets/issues/5634 | 1,622,424,174 | I_kwDODunzps5gtDpu | 5,634 | Not all progress bars are showing up when they should for downloading dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/110427462?v=4",
"events_url": "https://api.github.com/users/garlandz-db/events{/privacy}",
"followers_url": "https://api.github.com/users/garlandz-db/followers",
"following_url": "https://api.github.com/users/garlandz-db/following{/other_user}",
"gists_... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nBy default, tqdm has `leave=True` to \"keep all traces of the progress bar upon the termination of iteration\". However, we use `leave=False` in some places (as of recently), which removes the bar once the iteration is over.\r\n\r\nI feel like our TQDM bars are noisy, so I think we should always set `l... | 2023-03-13T23:04:18Z | 2023-10-11T16:30:16Z | 2023-10-11T16:30:16Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
During downloading the rotten tomatoes dataset, not all progress bars are displayed properly. This might be related to [this ticket](https://github.com/huggingface/datasets/issues/5117) as it raised the same concern but its not clear if the fix solves this issue too.
ipywidgets
<img width=... | {
"avatar_url": "https://avatars.githubusercontent.com/u/110427462?v=4",
"events_url": "https://api.github.com/users/garlandz-db/events{/privacy}",
"followers_url": "https://api.github.com/users/garlandz-db/followers",
"following_url": "https://api.github.com/users/garlandz-db/following{/other_user}",
"gists_... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5634/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5634/timeline | null | completed | null | null | 5,081.432778 | 1,996 |
https://api.github.com/repos/huggingface/datasets/issues/5633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5633/comments | https://api.github.com/repos/huggingface/datasets/issues/5633/events | https://github.com/huggingface/datasets/issues/5633 | 1,621,469,970 | I_kwDODunzps5gpasS | 5,633 | Cannot import datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/11250555?v=4",
"events_url": "https://api.github.com/users/eerio/events{/privacy}",
"followers_url": "https://api.github.com/users/eerio/followers",
"following_url": "https://api.github.com/users/eerio/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"Okay, the issue was likely caused by mixing `conda` and `pip` usage - I forgot that I have already used `pip` in this environment previously and that it was 'spoiled' because of it. Creating another environment and installing `datasets` by pip with other packages from the `requirements.txt` file solved the problem... | 2023-03-13T13:14:44Z | 2023-03-13T17:54:19Z | 2023-03-13T17:54:19Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi,
I cannot even import the library :( I installed it by running:
```
$ conda install datasets
```
Then I realized I should maybe use the huggingface channel, because I encountered the error below, so I ran:
```
$ conda remove datasets
$ conda install -c huggingface datasets
```
Pl... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5633/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5633/timeline | null | completed | null | null | 4.659722 | 1,997 |
https://api.github.com/repos/huggingface/datasets/issues/5631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5631/comments | https://api.github.com/repos/huggingface/datasets/issues/5631/events | https://github.com/huggingface/datasets/issues/5631 | 1,620,442,854 | I_kwDODunzps5glf7m | 5,631 | Custom split names | {
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"events_url": "https://api.github.com/users/ErfanMoosaviMonazzah/events{/privacy}",
"followers_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followers",
"following_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followin... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi!\r\n\r\nYou can also use names other than \"train\", \"validation\" and \"test\". As an example, check the [script](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/blob/e095840f23f3dffc1056c078c2f9320dad9ca74d/common_voice_11_0.py#L139) of the Common Voice 11 dataset. "
] | 2023-03-12T17:21:43Z | 2023-03-24T14:13:00Z | 2023-03-24T14:13:00Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Hi,
I participated in multiple NLP tasks where there are more than just train, test, validation splits, there could be multiple validation sets or test sets. But it seems currently only those mentioned three splits supported. It would be nice to have the support for more splits on the hub. (curren... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5631/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5631/timeline | null | completed | null | null | 284.854722 | 1,999 |
https://api.github.com/repos/huggingface/datasets/issues/5624 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5624/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5624/comments | https://api.github.com/repos/huggingface/datasets/issues/5624/events | https://github.com/huggingface/datasets/issues/5624 | 1,617,400,192 | I_kwDODunzps5gZ5GA | 5,624 | glue datasets returning -1 for test split | {
"avatar_url": "https://avatars.githubusercontent.com/u/8939967?v=4",
"events_url": "https://api.github.com/users/lithafnium/events{/privacy}",
"followers_url": "https://api.github.com/users/lithafnium/followers",
"following_url": "https://api.github.com/users/lithafnium/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | [
"Hi @lithafnium, thanks for reporting.\r\n\r\nPlease note that you can use the \"Community\" tab in the corresponding dataset page to start any discussion: https://huggingface.co/datasets/glue/discussions\r\n\r\nIndeed this issue was already raised there (https://huggingface.co/datasets/glue/discussions/5) and answ... | 2023-03-09T14:47:18Z | 2023-03-09T16:49:29Z | 2023-03-09T16:49:29Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Downloading any dataset from GLUE has -1 as class labels for test split. Train and validation have regular 0/1 class labels. This is also present in the dataset card online.
### Steps to reproduce the bug
```
dataset = load_dataset("glue", "sst2")
for d in dataset:
# prints out -1
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5624/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5624/timeline | null | completed | null | null | 2.036389 | 2,006 |
https://api.github.com/repos/huggingface/datasets/issues/5618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5618/comments | https://api.github.com/repos/huggingface/datasets/issues/5618/events | https://github.com/huggingface/datasets/issues/5618 | 1,612,977,934 | I_kwDODunzps5gJBcO | 5,618 | Unpin fsspec < 2023.3.0 once issue fixed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2023-03-07T08:41:51Z | 2023-03-07T13:39:03Z | 2023-03-07T13:39:03Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5618/timeline | null | completed | null | null | 4.953333 | 2,012 |
https://api.github.com/repos/huggingface/datasets/issues/5616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5616/comments | https://api.github.com/repos/huggingface/datasets/issues/5616/events | https://github.com/huggingface/datasets/issues/5616 | 1,612,932,508 | I_kwDODunzps5gI2Wc | 5,616 | CI is broken after fsspec-2023.3.0 release | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | 2023-03-07T08:06:39Z | 2023-03-07T08:37:29Z | 2023-03-07T08:37:29Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | As reported by @lhoestq, our CI is broken after `fsspec` 2023.3.0 release:
```
FAILED tests/test_filesystem.py::test_compression_filesystems[Bz2FileSystem] - AssertionError: assert [{'created': ...: False, ...}] == ['file.txt']
At index 0 diff: {'name': 'file.txt', 'size': 70, 'type': 'file', 'created': 1678175677... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5616/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5616/timeline | null | completed | null | null | 0.513889 | 2,014 |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | {
"avatar_url": "https://avatars.githubusercontent.com/u/6466389?v=4",
"events_url": "https://api.github.com/users/zsaladin/events{/privacy}",
"followers_url": "https://api.github.com/users/zsaladin/followers",
"following_url": "https://api.github.com/users/zsaladin/following{/other_user}",
"gists_url": "http... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"Hi! You can use `concatenate_datasets([ids1, ids2], axis=1)` to do this."
] | 2023-03-07T01:52:00Z | 2023-03-09T15:24:05Z | 2023-03-09T15:23:54Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | null | null | 61.531667 | 2,015 |
https://api.github.com/repos/huggingface/datasets/issues/5608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5608/comments | https://api.github.com/repos/huggingface/datasets/issues/5608/events | https://github.com/huggingface/datasets/issues/5608 | 1,609,996,563 | I_kwDODunzps5f9pkT | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | [
"Hi!\r\n\r\n> naming convention of mp3 files\r\n\r\nYes, this could be the problem. MP3 files should end with `.mp3`/`.MP3` to be recognized as audio files.\r\n\r\nIf the file names are not the culprit, can you paste the audio folder's directory structure to help us reproduce the error (e.g., by running the `tree ... | 2023-03-05T00:14:45Z | 2023-03-12T00:02:57Z | 2023-03-12T00:02:57Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the b... | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5608/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5608/timeline | null | completed | null | null | 167.803333 | 2,022 |
https://api.github.com/repos/huggingface/datasets/issues/5606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5606/comments | https://api.github.com/repos/huggingface/datasets/issues/5606/events | https://github.com/huggingface/datasets/issues/5606 | 1,608,911,632 | I_kwDODunzps5f5gsQ | 5,606 | Add `Dataset.to_list` to the API | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"events_url": "https://api.github.com/users/kyoto7250/events{/privacy}",
"followers_url": "https://api.github.com/users/kyoto7250/followers",
"following_url": "https://api.github.com/users/kyoto7250/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"events_url": "https://api.github.com/users/kyoto7250/events{/privacy}",
"followers_url": "https://api.github.com/users/kyoto7250/followers",
"following_url": "https://api.github.com/users/kyoto7250/following{/other_user}",
... | null | [
"Hello, I have an interest in this issue.\r\nIs the `Dataset.to_dict` you are describing correct in the code here?\r\n\r\nhttps://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/arrow_dataset.py#L4633-L4667",
"Yes, this is where `Dataset.to_dict` is defined.",
"#self-a... | 2023-03-03T16:17:10Z | 2023-03-27T13:26:40Z | 2023-03-27T13:26:40Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5606/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5606/timeline | null | completed | null | null | 573.158333 | 2,024 |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"events_url": "https://api.github.com/users/sentialx/events{/privacy}",
"followers_url": "https://api.github.com/users/sentialx/followers",
"following_url": "https://api.github.com/users/sentialx/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n\r\nYou can specify `download_config=DownloadConfig(resume_download=True))` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\da... | 2023-03-03T09:52:08Z | 2023-10-14T02:15:52Z | 2023-03-24T12:44:25Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
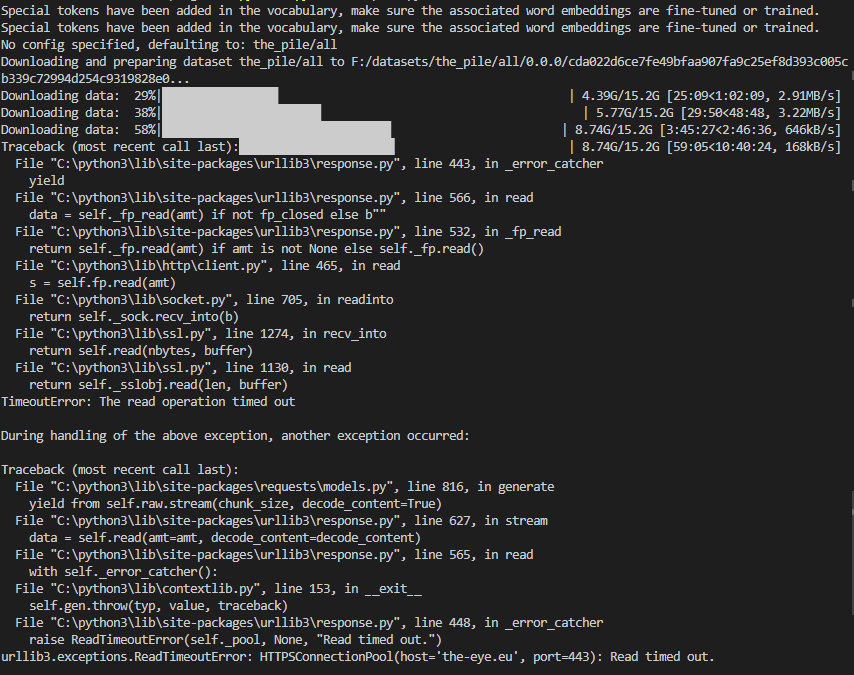
Here are the downloaded files:
`hg_user` but my repo cont... | 2023-03-02T12:08:39Z | 2023-03-14T16:55:35Z | 2023-03-14T16:55:34Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Get `Authorization error` when try to push data into hugginface datasets hub.
### Steps to reproduce the bug
I did all steps in the [tutorial](https://huggingface.co/docs/datasets/share),
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingfa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/107404835?v=4",
"events_url": "https://api.github.com/users/OleksandrKorovii/events{/privacy}",
"followers_url": "https://api.github.com/users/OleksandrKorovii/followers",
"following_url": "https://api.github.com/users/OleksandrKorovii/following{/other_us... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5601/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5601/timeline | null | completed | null | null | 292.781944 | 2,029 |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"events_url": "https://api.github.com/users/salahiguiliz/events{/privacy}",
"followers_url": "https://api.github.com/users/salahiguiliz/followers",
"following_url": "https://api.github.com/users/salahiguiliz/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n> (see example of DreamboothDatasets)\r\n\r\n\r\nCould you please provide a link to it? If you are referring to the example in the `diffusers` repo, your issue is unrelated to `datasets` as that example uses `Dataset` from PyTorch to load data."
] | 2023-03-02T11:00:27Z | 2023-03-13T17:59:35Z | 2023-03-13T17:59:35Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | completed | null | null | 270.985556 | 2,030 |
https://api.github.com/repos/huggingface/datasets/issues/5597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5597/comments | https://api.github.com/repos/huggingface/datasets/issues/5597/events | https://github.com/huggingface/datasets/issues/5597 | 1,604,928,721 | I_kwDODunzps5fqUTR | 5,597 | in-place dataset update | {
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url":... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"We won't support in-place modifications since `datasets` is based on the Apache Arrow format which doesn't support in-place modifications.\r\n\r\nIn your case the old dataset is garbage collected pretty quickly so you won't have memory issues.\r\n\r\nNote that datasets loaded from disk (memory mapped) are not load... | 2023-03-01T12:58:18Z | 2023-03-02T13:30:41Z | 2023-03-02T03:47:00Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Motivation
For the circumstance that I creat an empty `Dataset` and keep appending new rows into it, I found that it leads to creating a new dataset at each call. It looks quite memory-consuming. I just wonder if there is any more efficient way to do this.
```python
from datasets import Dataset
ds = Datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url":... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5597/timeline | null | completed | null | null | 14.811667 | 2,032 |
https://api.github.com/repos/huggingface/datasets/issues/5596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5596/comments | https://api.github.com/repos/huggingface/datasets/issues/5596/events | https://github.com/huggingface/datasets/issues/5596 | 1,604,919,993 | I_kwDODunzps5fqSK5 | 5,596 | [TypeError: Couldn't cast array of type] Can only load a subset of the dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Apparently some JSON objects have a `\"labels\"` field. Since this field is not present in every object, you must specify all the fields types in the README.md\r\n\r\nEDIT: actually specifying the feature types doesn’t solve the issue, it raises an error because “labels” is missing in the data",
"We've updated t... | 2023-03-01T12:53:08Z | 2023-12-05T03:22:00Z | 2023-03-02T11:12:11Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I'm trying to load this [dataset](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues) which consists of jsonl files and I get the following error:
```
casted_values = _c(array.values, feature[0])
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 1839, in wr... | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5596/timeline | null | completed | null | null | 22.3175 | 2,033 |
https://api.github.com/repos/huggingface/datasets/issues/5594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5594/comments | https://api.github.com/repos/huggingface/datasets/issues/5594/events | https://github.com/huggingface/datasets/issues/5594 | 1,603,980,995 | I_kwDODunzps5fms7D | 5,594 | Error while downloading the xtreme udpos dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/24687672?v=4",
"events_url": "https://api.github.com/users/simran-khanuja/events{/privacy}",
"followers_url": "https://api.github.com/users/simran-khanuja/followers",
"following_url": "https://api.github.com/users/simran-khanuja/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Hi! I cannot reproduce this error on my machine.\r\n\r\nThe raised error could mean that one of the downloaded files is corrupted. To verify this is not the case, you can run `load_dataset` as follows:\r\n```python\r\ntrain_dataset = load_dataset('xtreme', 'udpos.English', split=\"train\", cache_dir=args.cache_dir... | 2023-02-28T23:40:53Z | 2023-11-04T20:45:56Z | 2023-07-24T14:22:18Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi,
I am facing an error while downloading the xtreme udpos dataset using load_dataset. I have datasets 2.10.1 installed
```Downloading and preparing dataset xtreme/udpos.Arabic to /compute/tir-1-18/skhanuja/multilingual_ft/cache/data/xtreme/udpos.Arabic/1.0.0/29f5d57a48779f37ccb75cb8708d1... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5594/timeline | null | completed | null | null | 3,494.690278 | 2,035 |
https://api.github.com/repos/huggingface/datasets/issues/5586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5586/comments | https://api.github.com/repos/huggingface/datasets/issues/5586/events | https://github.com/huggingface/datasets/issues/5586 | 1,602,961,544 | I_kwDODunzps5fi0CI | 5,586 | .sort() is broken when used after .filter(), only in 2.10.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/57797966?v=4",
"events_url": "https://api.github.com/users/MattYoon/events{/privacy}",
"followers_url": "https://api.github.com/users/MattYoon/followers",
"following_url": "https://api.github.com/users/MattYoon/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Thanks for reporting and thanks @mariosasko for fixing ! We just did a patch release `2.10.1` with the fix"
] | 2023-02-28T12:18:09Z | 2023-02-28T18:17:26Z | 2023-02-28T17:21:59Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi, thank you for your support!
It seems like the addition of multiple key sort (#5502) in 2.10.0 broke the `.sort()` method.
After filtering a dataset with `.filter()`, the `.sort()` seems to refer to the query_table index of the previous unfiltered dataset, resulting in an IndexError.
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5586/timeline | null | completed | null | null | 5.063889 | 2,042 |
https://api.github.com/repos/huggingface/datasets/issues/5585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5585/comments | https://api.github.com/repos/huggingface/datasets/issues/5585/events | https://github.com/huggingface/datasets/issues/5585 | 1,602,190,030 | I_kwDODunzps5ff3rO | 5,585 | Cache is not transportable | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | closed | false | null | [] | null | [
"Hi ! No the cache is not transportable in general. It will work on a shared filesystem if you use the same python environment, but not across machines/os/environments.\r\n\r\nIn particular, reloading cached datasets does work, but reloading cached processed datasets (e.g. from `map`) may not work. This is because ... | 2023-02-28T00:53:06Z | 2023-02-28T21:26:52Z | 2023-02-28T21:26:52Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5585/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5585/timeline | null | completed | null | null | 20.562778 | 2,043 |
https://api.github.com/repos/huggingface/datasets/issues/5584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5584/comments | https://api.github.com/repos/huggingface/datasets/issues/5584/events | https://github.com/huggingface/datasets/issues/5584 | 1,601,821,808 | I_kwDODunzps5fedxw | 5,584 | Unable to load coyo700M dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3059998?v=4",
"events_url": "https://api.github.com/users/manuaero/events{/privacy}",
"followers_url": "https://api.github.com/users/manuaero/followers",
"following_url": "https://api.github.com/users/manuaero/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"Hi @manuaero \r\n\r\nThank you for your interest in the COYO dataset.\r\n\r\nOur dataset provides the img-url and alt-text in the form of a parquet, so to utilize the coyo dataset you will need to download it directly.\r\n\r\nWe provide a [guide](https://github.com/kakaobrain/coyo-dataset/blob/main/download/README... | 2023-02-27T19:35:03Z | 2023-02-28T07:27:59Z | 2023-02-28T07:27:58Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Seeing this error when downloading https://huggingface.co/datasets/kakaobrain/coyo-700m:
```ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.```
Full stack trace
```Downloading and preparing dataset parquet/kakaobrain--coy... | {
"avatar_url": "https://avatars.githubusercontent.com/u/3059998?v=4",
"events_url": "https://api.github.com/users/manuaero/events{/privacy}",
"followers_url": "https://api.github.com/users/manuaero/followers",
"following_url": "https://api.github.com/users/manuaero/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5584/timeline | null | completed | null | null | 11.881944 | 2,044 |
https://api.github.com/repos/huggingface/datasets/issues/5581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5581/comments | https://api.github.com/repos/huggingface/datasets/issues/5581/events | https://github.com/huggingface/datasets/issues/5581 | 1,600,675,489 | I_kwDODunzps5faF6h | 5,581 | [DOC] Mistaken docs on set_format | {
"avatar_url": "https://avatars.githubusercontent.com/u/36224762?v=4",
"events_url": "https://api.github.com/users/NightMachinery/events{/privacy}",
"followers_url": "https://api.github.com/users/NightMachinery/followers",
"following_url": "https://api.github.com/users/NightMachinery/following{/other_user}",
... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | [
"Thanks for reporting!"
] | 2023-02-27T08:03:09Z | 2023-02-28T19:19:17Z | 2023-02-28T19:19:17Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
https://huggingface.co/docs/datasets/v2.10.0/en/package_reference/main_classes#datasets.Dataset.set_format
<img width="700" alt="image" src="https://user-images.githubusercontent.com/36224762/221506973-ae2e3991-60a7-4d4e-99f8-965c6eb61e59.png">
While actually running it will result in:
<img w... | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5581/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5581/timeline | null | completed | null | null | 35.268889 | 2,047 |
https://api.github.com/repos/huggingface/datasets/issues/5577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5577/comments | https://api.github.com/repos/huggingface/datasets/issues/5577/events | https://github.com/huggingface/datasets/issues/5577 | 1,598,587,665 | I_kwDODunzps5fSIMR | 5,577 | Cannot load `the_pile_openwebtext2` | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Hi! I've merged a PR to use `int32` instead of `int8` for `reddit_scores`, so it should work now.\r\n\r\n"
] | 2023-02-24T13:01:48Z | 2023-02-24T14:01:09Z | 2023-02-24T14:01:09Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I met the same bug mentioned in #3053 which is never fixed. Because several `reddit_scores` are larger than `int8` even `int16`. https://huggingface.co/datasets/the_pile_openwebtext2/blob/main/the_pile_openwebtext2.py#L62
### Steps to reproduce the bug
```python3
from datasets import load... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5577/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5577/timeline | null | completed | null | null | 0.989167 | 2,051 |
https://api.github.com/repos/huggingface/datasets/issues/5576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5576/comments | https://api.github.com/repos/huggingface/datasets/issues/5576/events | https://github.com/huggingface/datasets/issues/5576 | 1,598,582,744 | I_kwDODunzps5fSG_Y | 5,576 | I was getting a similar error `pyarrow.lib.ArrowInvalid: Integer value 528 not in range: -128 to 127` - AFAICT, this is because the type specified for `reddit_scores` is `datasets.Sequence(datasets.Value("int8"))`, but the actual values can be well outside the max range for 8-bit integers. | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Duplicated issue."
] | 2023-02-24T12:57:49Z | 2023-02-24T12:58:31Z | 2023-02-24T12:58:18Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I was getting a similar error `pyarrow.lib.ArrowInvalid: Integer value 528 not in range: -128 to 127` - AFAICT, this is because the type specified for `reddit_scores` is `datasets.Sequence(datasets.Value("int8"))`, but the actual values can be well outside the max range for 8-bit integers.
I worked aro... | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5576/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5576/timeline | null | not_planned | null | null | 0.008056 | 2,052 |
https://api.github.com/repos/huggingface/datasets/issues/5574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5574/comments | https://api.github.com/repos/huggingface/datasets/issues/5574/events | https://github.com/huggingface/datasets/issues/5574 | 1,598,104,691 | I_kwDODunzps5fQSRz | 5,574 | c4 dataset streaming fails with `FileNotFoundError` | {
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"events_url": "https://api.github.com/users/krasserm/events{/privacy}",
"followers_url": "https://api.github.com/users/krasserm/followers",
"following_url": "https://api.github.com/users/krasserm/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"Also encountering this issue for every dataset I try to stream! Installed datasets from main:\r\n```\r\n- `datasets` version: 2.10.1.dev0\r\n- Platform: macOS-13.1-arm64-arm-64bit\r\n- Python version: 3.9.13\r\n- PyArrow version: 10.0.1\r\n- Pandas version: 1.5.2\r\n```\r\n\r\nRepro:\r\n```python\r\nfrom datasets ... | 2023-02-24T07:57:32Z | 2023-12-18T07:32:32Z | 2023-02-27T04:03:38Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Loading the `c4` dataset in streaming mode with `load_dataset("c4", "en", split="validation", streaming=True)` and then using it fails with a `FileNotFoundException`.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("c4", "en", split="train", ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"events_url": "https://api.github.com/users/krasserm/events{/privacy}",
"followers_url": "https://api.github.com/users/krasserm/followers",
"following_url": "https://api.github.com/users/krasserm/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5574/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5574/timeline | null | completed | null | null | 68.101667 | 2,054 |
https://api.github.com/repos/huggingface/datasets/issues/5572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5572/comments | https://api.github.com/repos/huggingface/datasets/issues/5572/events | https://github.com/huggingface/datasets/issues/5572 | 1,597,257,624 | I_kwDODunzps5fNDeY | 5,572 | Datasets 2.10.0 does not reuse the dataset cache | {
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"events_url": "https://api.github.com/users/lsb/events{/privacy}",
"followers_url": "https://api.github.com/users/lsb/followers",
"following_url": "https://api.github.com/users/lsb/following{/other_user}",
"gists_url": "https://api.github.co... | [] | closed | false | null | [] | null | [] | 2023-02-23T17:28:11Z | 2023-02-23T18:03:55Z | 2023-02-23T18:03:55Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
download_mode="reuse_dataset_if_exists" will always consider that a dataset doesn't exist.
Specifically, upon losing an internet connection trying to load a dataset for a second time in ten seconds, a connection error results, showing a breakpoint of:
```
File ~/jupyterlab/.direnv/python-... | {
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"events_url": "https://api.github.com/users/lsb/events{/privacy}",
"followers_url": "https://api.github.com/users/lsb/followers",
"following_url": "https://api.github.com/users/lsb/following{/other_user}",
"gists_url": "https://api.github.co... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5572/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5572/timeline | null | completed | null | null | 0.595556 | 2,056 |
https://api.github.com/repos/huggingface/datasets/issues/5571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5571/comments | https://api.github.com/repos/huggingface/datasets/issues/5571/events | https://github.com/huggingface/datasets/issues/5571 | 1,597,198,953 | I_kwDODunzps5fM1Jp | 5,571 | load_dataset fails for JSON in windows | {
"avatar_url": "https://avatars.githubusercontent.com/u/11876897?v=4",
"events_url": "https://api.github.com/users/abinashsahu/events{/privacy}",
"followers_url": "https://api.github.com/users/abinashsahu/followers",
"following_url": "https://api.github.com/users/abinashsahu/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou need to pass an input json file explicitly as `data_files` to `load_dataset` to avoid this error:\r\n```python\r\n ds = load_dataset(\"json\", data_files=args.input_json)\r\n```\r\n\r\n",
"Thanks it worked!"
] | 2023-02-23T16:50:11Z | 2023-02-24T13:21:47Z | 2023-02-24T13:21:47Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Steps:
1. Created a dataset in a Linux VM and created a small sample using dataset.to_json() method.
2. Downloaded the JSON file to my local Windows machine for working and saved in say - r"C:\Users\name\file.json"
3. I am reading the file in my local PyCharm - the location of python file is di... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5571/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5571/timeline | null | completed | null | null | 20.526667 | 2,057 |
https://api.github.com/repos/huggingface/datasets/issues/5570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5570/comments | https://api.github.com/repos/huggingface/datasets/issues/5570/events | https://github.com/huggingface/datasets/issues/5570 | 1,597,190,926 | I_kwDODunzps5fMzMO | 5,570 | load_dataset gives FileNotFoundError on imagenet-1k if license is not accepted on the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/38630200?v=4",
"events_url": "https://api.github.com/users/buoi/events{/privacy}",
"followers_url": "https://api.github.com/users/buoi/followers",
"following_url": "https://api.github.com/users/buoi/following{/other_user}",
"gists_url": "https://api.git... | [] | closed | false | null | [] | null | [
"Hi, thanks for the feedback! Would it help to add a tip or note saying the dataset is gated and you need to accept the license before downloading it?",
"The error is now more informative:\r\n```\r\nFileNotFoundError: Couldn't find a dataset script at /content/imagenet-1k/imagenet-1k.py or any data file in the sa... | 2023-02-23T16:44:32Z | 2023-07-24T15:18:50Z | 2023-07-24T15:18:50Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When calling ```load_dataset('imagenet-1k')``` FileNotFoundError is raised, if not logged in and if logged in with huggingface-cli but not having accepted the licence on the hub. There is no error once accepting.
### Steps to reproduce the bug
```
from datasets import load_dataset
imagenet =... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5570/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5570/timeline | null | completed | null | null | 3,622.571667 | 2,058 |
https://api.github.com/repos/huggingface/datasets/issues/5568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5568/comments | https://api.github.com/repos/huggingface/datasets/issues/5568/events | https://github.com/huggingface/datasets/issues/5568 | 1,596,900,532 | I_kwDODunzps5fLsS0 | 5,568 | dataset.to_iterable_dataset() loses useful info like dataset features | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
... | null | [
"Hi ! Oh good catch. I think the features should be passed to `IterableDataset.from_generator()` in `to_iterable_dataset()` indeed.\r\n\r\nSetting this as a good first issue if someone would like to contribute, otherwise we can take care of it :)",
"#self-assign",
"seems like the feature parameter is missing fr... | 2023-02-23T13:45:33Z | 2023-02-24T13:22:36Z | 2023-02-24T13:22:36Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hello,
I like the new `to_iterable_dataset` feature but I noticed something that seems to be missing.
When using `to_iterable_dataset` to transform your map style dataset into iterable dataset, you lose valuable metadata like the features.
These metadata are useful if you want to interleav... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5568/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5568/timeline | null | completed | null | null | 23.6175 | 2,060 |
https://api.github.com/repos/huggingface/datasets/issues/5548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5548/comments | https://api.github.com/repos/huggingface/datasets/issues/5548/events | https://github.com/huggingface/datasets/issues/5548 | 1,590,835,479 | I_kwDODunzps5e0jkX | 5,548 | Apply flake8-comprehensions to codebase | {
"avatar_url": "https://avatars.githubusercontent.com/u/2053727?v=4",
"events_url": "https://api.github.com/users/Skylion007/events{/privacy}",
"followers_url": "https://api.github.com/users/Skylion007/followers",
"following_url": "https://api.github.com/users/Skylion007/following{/other_user}",
"gists_url":... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | 2023-02-19T20:05:38Z | 2023-02-23T13:59:41Z | 2023-02-23T13:59:41Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Apply ruff flake8 comprehension checks to codebase.
### Motivation
This should strictly improve the performance / readability of the codebase by removing unnecessary iteration, function calls, etc. This should generate better Python bytecode which should strictly improve performance.
I alread... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5548/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5548/timeline | null | completed | null | null | 89.900833 | 2,079 |
https://api.github.com/repos/huggingface/datasets/issues/5546 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5546/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5546/comments | https://api.github.com/repos/huggingface/datasets/issues/5546/events | https://github.com/huggingface/datasets/issues/5546 | 1,590,346,349 | I_kwDODunzps5eysJt | 5,546 | Downloaded datasets do not cache at $HF_HOME | {
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"events_url": "https://api.github.com/users/ErfanMoosaviMonazzah/events{/privacy}",
"followers_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followers",
"following_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followin... | [] | closed | false | null | [] | null | [
"Hi ! Can you make sure you set `HF_HOME` before importing `datasets` ?\r\n\r\nThen you can print\r\n```python\r\nprint(datasets.config.HF_CACHE_HOME)\r\nprint(datasets.config.HF_DATASETS_CACHE)\r\n```"
] | 2023-02-18T13:30:35Z | 2023-07-24T14:22:43Z | 2023-07-24T14:22:43Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
In the huggingface course (https://huggingface.co/course/chapter3/2?fw=pt) it said that if we set HF_HOME, downloaded datasets would be cached at specified address but it does not. downloaded models from checkpoint names are downloaded and cached at HF_HOME but this is not the case for datasets, t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5546/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5546/timeline | null | completed | null | null | 3,744.868889 | 2,081 |
https://api.github.com/repos/huggingface/datasets/issues/5543 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5543/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5543/comments | https://api.github.com/repos/huggingface/datasets/issues/5543/events | https://github.com/huggingface/datasets/issues/5543 | 1,588,951,379 | I_kwDODunzps5etXlT | 5,543 | the pile datasets url seems to change back | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @wjfwzzc.\r\n\r\nI am transferring this issue to the corresponding dataset on the Hub: https://huggingface.co/datasets/bookcorpusopen/discussions/1",
"Thank you. All fixes are done:\r\n- [x] https://huggingface.co/datasets/bookcorpusopen/discussions/2\r\n- [x] https://huggingface.co/dataset... | 2023-02-17T08:40:11Z | 2023-02-21T06:37:00Z | 2023-02-20T08:41:33Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
in #3627, the host url of the pile dataset became `https://mystic.the-eye.eu`. Now the new url is broken, but `https://the-eye.eu` seems to work again.
### Steps to reproduce the bug
```python3
from datasets import load_dataset
dataset = load_dataset("bookcorpusopen")
```
shows
```python3
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5543/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5543/timeline | null | completed | null | null | 72.022778 | 2,083 |
https://api.github.com/repos/huggingface/datasets/issues/5541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5541/comments | https://api.github.com/repos/huggingface/datasets/issues/5541/events | https://github.com/huggingface/datasets/issues/5541 | 1,588,633,555 | I_kwDODunzps5esJ_T | 5,541 | Flattening indices in selected datasets is extremely inefficient | {
"avatar_url": "https://avatars.githubusercontent.com/u/6591505?v=4",
"events_url": "https://api.github.com/users/marioga/events{/privacy}",
"followers_url": "https://api.github.com/users/marioga/followers",
"following_url": "https://api.github.com/users/marioga/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Running the script above on the branch https://github.com/huggingface/datasets/pull/5542 results in the expected behaviour:\r\n```\r\nNum chunks for original ds: 1\r\nOriginal ds save/load\r\nsave_to_disk -- RAM memory used: 0.671875 MB -- Total time: 0.255265 s\r\nload_from_disk -- RAM memory used: 42.796875 MB -... | 2023-02-17T01:52:24Z | 2023-02-22T13:15:20Z | 2023-02-17T11:12:33Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
If we perform a `select` (or `shuffle`, `train_test_split`, etc.) operation on a dataset , we end up with a dataset with an `indices_table`. Currently, flattening such dataset consumes a lot of memory and the resulting flat dataset contains ChunkedArrays with as many chunks as there are rows. Thi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5541/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5541/timeline | null | completed | null | null | 9.335833 | 2,085 |
https://api.github.com/repos/huggingface/datasets/issues/5539 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5539/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5539/comments | https://api.github.com/repos/huggingface/datasets/issues/5539/events | https://github.com/huggingface/datasets/issues/5539 | 1,587,970,083 | I_kwDODunzps5epoAj | 5,539 | IndexError: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number | {
"avatar_url": "https://avatars.githubusercontent.com/u/41912135?v=4",
"events_url": "https://api.github.com/users/aalbersk/events{/privacy}",
"followers_url": "https://api.github.com/users/aalbersk/followers",
"following_url": "https://api.github.com/users/aalbersk/following{/other_user}",
"gists_url": "htt... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | [
"Hi! The `set_transform` does not apply a custom formatting transform on a single example but the entire batch, so the fixed version of your transform would look as follows:\r\n```python\r\nfrom datasets import load_dataset\r\nimport torch\r\n\r\ndataset = load_dataset(\"lambdalabs/pokemon-blip-captions\", split='t... | 2023-02-16T16:08:51Z | 2023-02-22T10:30:30Z | 2023-02-21T13:03:57Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When dataset contains a 0-dim tensor, formatting.py raises a following error and fails.
```bash
Traceback (most recent call last):
File "<path>/lib/python3.8/site-packages/datasets/formatting/formatting.py", line 501, in format_row
return _unnest(formatted_batch)
File "<path>/lib/py... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5539/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5539/timeline | null | completed | null | null | 116.918333 | 2,087 |
https://api.github.com/repos/huggingface/datasets/issues/5538 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5538/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5538/comments | https://api.github.com/repos/huggingface/datasets/issues/5538/events | https://github.com/huggingface/datasets/issues/5538 | 1,587,732,596 | I_kwDODunzps5eouB0 | 5,538 | load_dataset in seaborn is not working for me. getting this error. | {
"avatar_url": "https://avatars.githubusercontent.com/u/125575109?v=4",
"events_url": "https://api.github.com/users/reemaranibarik/events{/privacy}",
"followers_url": "https://api.github.com/users/reemaranibarik/followers",
"following_url": "https://api.github.com/users/reemaranibarik/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Hi! `seaborn`'s `load_dataset` pulls datasets from [here](https://github.com/mwaskom/seaborn-data) and not from our Hub, so this issue is not related to our library in any way and should be reported in their repo instead."
] | 2023-02-16T14:01:58Z | 2023-02-16T14:44:36Z | 2023-02-16T14:44:36Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | TimeoutError Traceback (most recent call last)
~\anaconda3\lib\urllib\request.py in do_open(self, http_class, req, **http_conn_args)
1345 try:
-> 1346 h.request(req.get_method(), req.selector, req.data, headers,
1347 encode_chu... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5538/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5538/timeline | null | completed | null | null | 0.710556 | 2,088 |
https://api.github.com/repos/huggingface/datasets/issues/5537 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5537/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5537/comments | https://api.github.com/repos/huggingface/datasets/issues/5537/events | https://github.com/huggingface/datasets/issues/5537 | 1,587,567,464 | I_kwDODunzps5eoFto | 5,537 | Increase speed of data files resolution | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": fals... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/35013374?v=4",
"events_url": "https://api.github.com/users/semajyllek/events{/privacy}",
"followers_url": "https://api.github.com/users/semajyllek/followers",
"following_url": "https://api.github.com/users/semajyllek/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/35013374?v=4",
"events_url": "https://api.github.com/users/semajyllek/events{/privacy}",
"followers_url": "https://api.github.com/users/semajyllek/followers",
"following_url": "https://api.github.com/users/semajyllek/following{/other_user}",
... | null | [
"#self-assign",
"You were right, if `self.dir_cache` is not None in glob, it is exactly the same as what is returned by find, at least for all the tests we have, and some extended evaluation I did across a random sample of about 1000 datasets. \r\n\r\nThanks for the nice hints, and let me know if this is not exac... | 2023-02-16T12:11:45Z | 2023-12-15T13:12:31Z | 2023-12-15T13:12:31Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Certain datasets like `bigcode/the-stack-dedup` have so many files that loading them takes forever right from the data files resolution step.
`datasets` uses file patterns to check the structure of the repository but it takes too much time to iterate over and over again on all the data files.
This comes from `res... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5537/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5537/timeline | null | completed | null | null | 7,249.012778 | 2,089 |
https://api.github.com/repos/huggingface/datasets/issues/5536 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5536/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5536/comments | https://api.github.com/repos/huggingface/datasets/issues/5536/events | https://github.com/huggingface/datasets/issues/5536 | 1,586,930,643 | I_kwDODunzps5elqPT | 5,536 | Failure to hash function when using .map() | {
"avatar_url": "https://avatars.githubusercontent.com/u/6916056?v=4",
"events_url": "https://api.github.com/users/venzen/events{/privacy}",
"followers_url": "https://api.github.com/users/venzen/followers",
"following_url": "https://api.github.com/users/venzen/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Hi ! `enc` is not hashable:\r\n```python\r\nimport tiktoken\r\nfrom datasets.fingerprint import Hasher\r\n\r\nenc = tiktoken.get_encoding(\"gpt2\")\r\nHasher.hash(enc)\r\n# raises TypeError: cannot pickle 'builtins.CoreBPE' object\r\n```\r\nIt happens because it's not picklable, and because of that it's not possib... | 2023-02-16T03:12:07Z | 2023-09-08T21:06:01Z | 2023-02-16T14:56:41Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
_Parameter 'function'=<function process at 0x7f1ec4388af0> of the transform datasets.arrow_dataset.Dataset.\_map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and ca... | {
"avatar_url": "https://avatars.githubusercontent.com/u/6916056?v=4",
"events_url": "https://api.github.com/users/venzen/events{/privacy}",
"followers_url": "https://api.github.com/users/venzen/followers",
"following_url": "https://api.github.com/users/venzen/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5536/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5536/timeline | null | completed | null | null | 11.742778 | 2,090 |
https://api.github.com/repos/huggingface/datasets/issues/5532 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5532/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5532/comments | https://api.github.com/repos/huggingface/datasets/issues/5532/events | https://github.com/huggingface/datasets/issues/5532 | 1,584,505,128 | I_kwDODunzps5ecaEo | 5,532 | train_test_split in arrow_dataset does not ensure to keep single classes in test set | {
"avatar_url": "https://avatars.githubusercontent.com/u/37191008?v=4",
"events_url": "https://api.github.com/users/Ulipenitz/events{/privacy}",
"followers_url": "https://api.github.com/users/Ulipenitz/followers",
"following_url": "https://api.github.com/users/Ulipenitz/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hi! You can get this behavior by specifying `stratify_by_column=\"label\"` in `train_test_split`.\r\n\r\nThis is the full example:\r\n```python\r\nimport numpy as np\r\nfrom datasets import Dataset, ClassLabel\r\n\r\ndata = [\r\n {'label': 0, 'text': \"example1\"},\r\n {'label': 1, 'text': \"example2\"},\r\n... | 2023-02-14T16:52:29Z | 2023-02-15T16:09:19Z | 2023-02-15T16:09:19Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When I have a dataset with very few (e.g. 1) examples per class and I call the train_test_split function on it, sometimes the single class will be in the test set. thus will never be considered for training.
### Steps to reproduce the bug
```
import numpy as np
from datasets import Dataset
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5532/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5532/timeline | null | completed | null | null | 23.280556 | 2,094 |
https://api.github.com/repos/huggingface/datasets/issues/5525 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5525/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5525/comments | https://api.github.com/repos/huggingface/datasets/issues/5525/events | https://github.com/huggingface/datasets/issues/5525 | 1,580,342,729 | I_kwDODunzps5eMh3J | 5,525 | TypeError: Couldn't cast array of type string to null | {
"avatar_url": "https://avatars.githubusercontent.com/u/74564958?v=4",
"events_url": "https://api.github.com/users/TJ-Solergibert/events{/privacy}",
"followers_url": "https://api.github.com/users/TJ-Solergibert/followers",
"following_url": "https://api.github.com/users/TJ-Solergibert/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Thanks for reporting, @TJ-Solergibert.\r\n\r\nWe cannot access your Colab notebook: `There was an error loading this notebook. Ensure that the file is accessible and try again.`\r\nCould you please make it publicly accessible?\r\n",
"I swear it's public, I've checked the settings and I've been able to open it in... | 2023-02-10T21:12:36Z | 2023-02-14T17:41:08Z | 2023-02-14T09:35:49Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Processing a dataset I alredy uploaded to the Hub (https://huggingface.co/datasets/tj-solergibert/Europarl-ST) I found that for some splits and some languages (test split, source_lang = "nl") after applying a map function I get the mentioned error.
I alredy tried reseting the shorter strings... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5525/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5525/timeline | null | completed | null | null | 84.386944 | 2,101 |
https://api.github.com/repos/huggingface/datasets/issues/5520 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5520/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5520/comments | https://api.github.com/repos/huggingface/datasets/issues/5520/events | https://github.com/huggingface/datasets/issues/5520 | 1,578,417,074 | I_kwDODunzps5eFLuy | 5,520 | ClassLabel.cast_storage raises TypeError when called on an empty IntegerArray | {
"avatar_url": "https://avatars.githubusercontent.com/u/6591505?v=4",
"events_url": "https://api.github.com/users/marioga/events{/privacy}",
"followers_url": "https://api.github.com/users/marioga/followers",
"following_url": "https://api.github.com/users/marioga/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [] | 2023-02-09T18:46:52Z | 2023-02-12T11:17:18Z | 2023-02-12T11:17:18Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
`ClassLabel.cast_storage` raises `TypeError` when called on an empty `IntegerArray`.
### Steps to reproduce the bug
Minimal steps:
```python
import pyarrow as pa
from datasets import ClassLabel
ClassLabel(names=['foo', 'bar']).cast_storage(pa.array([], pa.int64()))
```
In practice, thi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5520/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5520/timeline | null | completed | null | null | 64.507222 | 2,106 |
https://api.github.com/repos/huggingface/datasets/issues/5514 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5514/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5514/comments | https://api.github.com/repos/huggingface/datasets/issues/5514/events | https://github.com/huggingface/datasets/issues/5514 | 1,576,453,837 | I_kwDODunzps5d9sbN | 5,514 | Improve inconsistency of `Dataset.map` interface for `load_from_cache_file` | {
"avatar_url": "https://avatars.githubusercontent.com/u/22773355?v=4",
"events_url": "https://api.github.com/users/HallerPatrick/events{/privacy}",
"followers_url": "https://api.github.com/users/HallerPatrick/followers",
"following_url": "https://api.github.com/users/HallerPatrick/following{/other_user}",
"g... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi, thanks for noticing this! We can't just remove the cache control as this allows us to control where the arrow files generated by the ops are written (cached on disk if enabled or a temporary directory if disabled). The right way to address this inconsistency would be by having `load_from_cache_file=None` by de... | 2023-02-08T16:40:44Z | 2023-02-14T14:26:44Z | 2023-02-14T14:26:44Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
1. Replace the `load_from_cache_file` default value to `True`.
2. Remove or alter checks from `is_caching_enabled` logic.
### Motivation
I stumbled over an inconsistency in the `Dataset.map` interface. The documentation (and source) states for the parameter `load_from_cache_file`:
```
load_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5514/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5514/timeline | null | completed | null | null | 141.766667 | 2,112 |
https://api.github.com/repos/huggingface/datasets/issues/5513 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5513/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5513/comments | https://api.github.com/repos/huggingface/datasets/issues/5513/events | https://github.com/huggingface/datasets/issues/5513 | 1,576,300,803 | I_kwDODunzps5d9HED | 5,513 | Some functions use a param named `type` shouldn't that be avoided since it's a Python reserved name? | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Hi! Let's not do this - renaming it would be a breaking change, and going through the deprecation cycle is only worth it if it improves user experience.",
"Hi @mariosasko, ok it makes sense. Anyway, don't you think it's worth it at some point to start a deprecation cycle e.g. `fs` in `load_from_disk`? It doesn't... | 2023-02-08T15:13:46Z | 2023-07-24T16:02:18Z | 2023-07-24T14:27:59Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hi @mariosasko, @lhoestq, or whoever reads this! :)
After going through `ArrowDataset.set_format` I found out that the `type` param is actually named `type` which is a Python reserved name as you may already know, shouldn't that be renamed to `format_type` before the 3.0.0 is released?
Just wanted to get your inp... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5513/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5513/timeline | null | completed | null | null | 3,983.236944 | 2,113 |
https://api.github.com/repos/huggingface/datasets/issues/5511 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5511/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5511/comments | https://api.github.com/repos/huggingface/datasets/issues/5511/events | https://github.com/huggingface/datasets/issues/5511 | 1,575,851,768 | I_kwDODunzps5d7Zb4 | 5,511 | Creating a dummy dataset from a bigger one | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [
"Update `datasets` or downgrade `huggingface-hub` ;)\r\n\r\nThe `huggingface-hub` lib did a breaking change a few months ago, and you're using an old version of `datasets` that does't support it",
"Awesome thanks a lot! Everything works just fine with `datasets==2.9.0` :-) ",
"Getting same error with latest ver... | 2023-02-08T10:18:41Z | 2023-12-28T18:21:01Z | 2023-02-08T10:35:48Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I often want to create a dummy dataset from a bigger dataset for fast iteration when training. However, I'm having a hard time doing this especially when trying to upload the dataset to the Hub.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset... | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5511/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5511/timeline | null | completed | null | null | 0.285278 | 2,115 |
https://api.github.com/repos/huggingface/datasets/issues/5508 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5508/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5508/comments | https://api.github.com/repos/huggingface/datasets/issues/5508/events | https://github.com/huggingface/datasets/issues/5508 | 1,573,290,359 | I_kwDODunzps5dxoF3 | 5,508 | Saving a dataset after setting format to torch doesn't work, but only if filtering | {
"avatar_url": "https://avatars.githubusercontent.com/u/13984157?v=4",
"events_url": "https://api.github.com/users/joebhakim/events{/privacy}",
"followers_url": "https://api.github.com/users/joebhakim/followers",
"following_url": "https://api.github.com/users/joebhakim/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hey, I'm a research engineer working on language modelling wanting to contribute to open source. I was wondering if I could give it a shot?",
"Hi! This issue was fixed in https://github.com/huggingface/datasets/pull/4972, so please install `datasets>=2.5.0` to avoid it."
] | 2023-02-06T21:08:58Z | 2023-02-09T14:55:26Z | 2023-02-09T14:55:26Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Saving a dataset after setting format to torch doesn't work, but only if filtering
### Steps to reproduce the bug
```
a = Dataset.from_dict({"b": [1, 2]})
a.set_format('torch')
a.save_to_disk("test_save") # saves successfully
a.filter(None).save_to_disk("test_save_filter") # does not
>> [..... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5508/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5508/timeline | null | completed | null | null | 65.774444 | 2,118 |
https://api.github.com/repos/huggingface/datasets/issues/5506 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5506/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5506/comments | https://api.github.com/repos/huggingface/datasets/issues/5506/events | https://github.com/huggingface/datasets/issues/5506 | 1,571,838,641 | I_kwDODunzps5dsFqx | 5,506 | IterableDataset and Dataset return different batch sizes when using Trainer with multiple GPUs | {
"avatar_url": "https://avatars.githubusercontent.com/u/38166299?v=4",
"events_url": "https://api.github.com/users/kheyer/events{/privacy}",
"followers_url": "https://api.github.com/users/kheyer/followers",
"following_url": "https://api.github.com/users/kheyer/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Hi ! `datasets` doesn't do batching - the PyTorch DataLoader does and is created by the `Trainer`. Do you pass other arguments to training_args with respect to data loading ?\r\n\r\nAlso we recently released `.to_iterable_dataset` that does pretty much what you implemented, but using contiguous shards to get a bet... | 2023-02-06T03:26:03Z | 2023-02-08T18:30:08Z | 2023-02-08T18:30:07Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I am training a Roberta model using 2 GPUs and the `Trainer` API with a batch size of 256.
Initially I used a standard `Dataset`, but had issues with slow data loading. After reading [this issue](https://github.com/huggingface/datasets/issues/2252), I swapped to loading my dataset as contiguous... | {
"avatar_url": "https://avatars.githubusercontent.com/u/38166299?v=4",
"events_url": "https://api.github.com/users/kheyer/events{/privacy}",
"followers_url": "https://api.github.com/users/kheyer/followers",
"following_url": "https://api.github.com/users/kheyer/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5506/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5506/timeline | null | completed | null | null | 63.067778 | 2,120 |
https://api.github.com/repos/huggingface/datasets/issues/5505 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5505/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5505/comments | https://api.github.com/repos/huggingface/datasets/issues/5505/events | https://github.com/huggingface/datasets/issues/5505 | 1,571,720,814 | I_kwDODunzps5dro5u | 5,505 | PyTorch BatchSampler still loads from Dataset one-by-one | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | closed | false | null | [] | null | [
"This change seems to come from a few months ago in the PyTorch side. That's good news and it means we may not need to pass a batch_sampler as soon as we add `Dataset.__getitems__` to get the optimal speed :)\r\n\r\nThanks for reporting ! Would you like to open a PR to add `__getitems__` and remove this outdated do... | 2023-02-06T01:14:55Z | 2023-02-19T18:27:30Z | 2023-02-19T18:27:30Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
In [the docs here](https://huggingface.co/docs/datasets/use_with_pytorch#use-a-batchsampler), it mentions the issue of the Dataset being read one-by-one, then states that using a BatchSampler resolves the issue.
I'm not sure if this is a mistake in the docs or the code, but it seems that the on... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5505/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5505/timeline | null | completed | null | null | 329.209722 | 2,121 |
https://api.github.com/repos/huggingface/datasets/issues/5500 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5500/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5500/comments | https://api.github.com/repos/huggingface/datasets/issues/5500/events | https://github.com/huggingface/datasets/issues/5500 | 1,569,257,240 | I_kwDODunzps5diPcY | 5,500 | WMT19 custom download checksum error | {
"avatar_url": "https://avatars.githubusercontent.com/u/38466901?v=4",
"events_url": "https://api.github.com/users/Hannibal046/events{/privacy}",
"followers_url": "https://api.github.com/users/Hannibal046/followers",
"following_url": "https://api.github.com/users/Hannibal046/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"I update the `datatsets` version and it works."
] | 2023-02-03T05:45:37Z | 2023-02-03T05:52:56Z | 2023-02-03T05:52:56Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I use the following scripts to download data from WMT19:
```python
import datasets
from datasets import inspect_dataset, load_dataset_builder
from wmt19.wmt_utils import _TRAIN_SUBSETS,_DEV_SUBSETS
## this is a must due to: https://discuss.huggingface.co/t/load-dataset-hangs-with-local-fi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/38466901?v=4",
"events_url": "https://api.github.com/users/Hannibal046/events{/privacy}",
"followers_url": "https://api.github.com/users/Hannibal046/followers",
"following_url": "https://api.github.com/users/Hannibal046/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5500/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5500/timeline | null | completed | null | null | 0.121944 | 2,125 |
https://api.github.com/repos/huggingface/datasets/issues/5498 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5498/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5498/comments | https://api.github.com/repos/huggingface/datasets/issues/5498/events | https://github.com/huggingface/datasets/issues/5498 | 1,568,190,529 | I_kwDODunzps5deLBB | 5,498 | TypeError: 'bool' object is not iterable when filtering a datasets.arrow_dataset.Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/91255010?v=4",
"events_url": "https://api.github.com/users/vmuel/events{/privacy}",
"followers_url": "https://api.github.com/users/vmuel/followers",
"following_url": "https://api.github.com/users/vmuel/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"Hi! Instead of a single boolean, your filter function should return an iterable (of booleans) in the batched mode like so:\r\n```python\r\ntrain_dataset = train_dataset.filter(\r\n function=lambda batch: [image is not None for image in batch[\"image\"]], \r\n batched=True,\r\n batc... | 2023-02-02T14:46:49Z | 2023-10-08T06:12:47Z | 2023-02-04T17:19:36Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi,
Thanks for the amazing work on the library!
**Describe the bug**
I think I might have noticed a small bug in the filter method.
Having loaded a dataset using `load_dataset`, when I try to filter out empty entries with `batched=True`, I get a TypeError.
### Steps to reproduce the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/91255010?v=4",
"events_url": "https://api.github.com/users/vmuel/events{/privacy}",
"followers_url": "https://api.github.com/users/vmuel/followers",
"following_url": "https://api.github.com/users/vmuel/following{/other_user}",
"gists_url": "https://api.... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5498/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5498/timeline | null | completed | null | null | 50.546389 | 2,127 |
https://api.github.com/repos/huggingface/datasets/issues/5496 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5496/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5496/comments | https://api.github.com/repos/huggingface/datasets/issues/5496/events | https://github.com/huggingface/datasets/issues/5496 | 1,567,301,765 | I_kwDODunzps5dayCF | 5,496 | Add a `reduce` method | {
"avatar_url": "https://avatars.githubusercontent.com/u/59542043?v=4",
"events_url": "https://api.github.com/users/zhangir-azerbayev/events{/privacy}",
"followers_url": "https://api.github.com/users/zhangir-azerbayev/followers",
"following_url": "https://api.github.com/users/zhangir-azerbayev/following{/other_... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! Sure, feel free to open a PR, so we can see the API you have in mind.",
"I would like to give it a go! #self-assign",
"Closing as `Dataset.map` can be used instead (see https://github.com/huggingface/datasets/pull/5533#issuecomment-1440571658 and https://github.com/huggingface/datasets/pull/5533#issuecomme... | 2023-02-02T04:30:22Z | 2024-11-12T05:58:14Z | 2023-07-21T14:24:32Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Right now the `Dataset` class implements `map()` and `filter()`, but leaves out the third functional idiom popular among Python users: `reduce`.
### Motivation
A `reduce` method is often useful when calculating dataset statistics, for example, the occurrence of a particular n-gram or the average... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5496/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5496/timeline | null | completed | null | null | 4,065.902778 | 2,129 |
https://api.github.com/repos/huggingface/datasets/issues/5495 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5495/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5495/comments | https://api.github.com/repos/huggingface/datasets/issues/5495/events | https://github.com/huggingface/datasets/issues/5495 | 1,566,803,452 | I_kwDODunzps5dY4X8 | 5,495 | to_tf_dataset fails with datetime UTC columns even if not included in columns argument | {
"avatar_url": "https://avatars.githubusercontent.com/u/2512762?v=4",
"events_url": "https://api.github.com/users/dwyatte/events{/privacy}",
"followers_url": "https://api.github.com/users/dwyatte/followers",
"following_url": "https://api.github.com/users/dwyatte/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"descript... | closed | false | null | [] | null | [
"Hi! This is indeed a bug in our zero-copy logic.\r\n\r\nTo fix it, instead of the line:\r\nhttps://github.com/huggingface/datasets/blob/7cfac43b980ab9e4a69c2328f085770996323005/src/datasets/features/features.py#L702\r\n\r\nwe should have:\r\n```python\r\nreturn pa.types.is_primitive(pa_type) and not (pa.types.is_b... | 2023-02-01T20:47:33Z | 2023-02-08T14:33:19Z | 2023-02-08T14:33:19Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
There appears to be some eager behavior in `to_tf_dataset` that runs against every column in a dataset even if they aren't included in the columns argument. This is problematic with datetime UTC columns due to them not working with zero copy. If I don't have UTC information in my datetime column... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5495/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5495/timeline | null | completed | null | null | 161.762778 | 2,130 |
https://api.github.com/repos/huggingface/datasets/issues/5494 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5494/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5494/comments | https://api.github.com/repos/huggingface/datasets/issues/5494/events | https://github.com/huggingface/datasets/issues/5494 | 1,566,655,348 | I_kwDODunzps5dYUN0 | 5,494 | Update audio installation doc page | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"Totally agree, the docs should be in sync with our code.\r\n\r\nIndeed to avoid confusing users, I think we should have updated the docs at the same time as this PR:\r\n- #5167",
"@albertvillanova yeah sure I should have, but I forgot back then, sorry for that 😶",
"No, @polinaeterna, nothing to be sorry about... | 2023-02-01T19:07:50Z | 2023-03-02T16:08:17Z | 2023-03-02T16:08:17Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Our [installation documentation page](https://huggingface.co/docs/datasets/installation#audio) says that one can use Datasets for mp3 only with `torchaudio<0.12`. `torchaudio>0.12` is actually supported too but requires a specific version of ffmpeg which is not easily installed on all linux versions but there is a cust... | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5494/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5494/timeline | null | completed | null | null | 693.0075 | 2,131 |
https://api.github.com/repos/huggingface/datasets/issues/5492 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5492/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5492/comments | https://api.github.com/repos/huggingface/datasets/issues/5492/events | https://github.com/huggingface/datasets/issues/5492 | 1,566,604,216 | I_kwDODunzps5dYHu4 | 5,492 | Push_to_hub in a pull request | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists... | null | [
"Assigned to myself and will get to it in the next week, but if someone finds this issue annoying and wants to submit a PR before I do, just ping me here and I'll reassign :). ",
"I would like to be assigned to this issue, @nateraw . #self-assign"
] | 2023-02-01T18:32:14Z | 2023-10-16T13:30:48Z | 2023-10-16T13:30:48Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Right now `ds.push_to_hub()` can push a dataset on `main` or on a new branch with `branch=`, but there is no way to open a pull request. Even passing `branch=refs/pr/x` doesn't seem to work: it tries to create a branch with that name
cc @nateraw
It should be possible to tweak the use of `huggingface_hub` in `pus... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5492/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5492/timeline | null | completed | null | null | 6,162.976111 | 2,133 |
https://api.github.com/repos/huggingface/datasets/issues/5488 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5488/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5488/comments | https://api.github.com/repos/huggingface/datasets/issues/5488/events | https://github.com/huggingface/datasets/issues/5488 | 1,565,025,262 | I_kwDODunzps5dSGPu | 5,488 | Error loading MP3 files from CommonVoice | {
"avatar_url": "https://avatars.githubusercontent.com/u/110259722?v=4",
"events_url": "https://api.github.com/users/kradonneoh/events{/privacy}",
"followers_url": "https://api.github.com/users/kradonneoh/followers",
"following_url": "https://api.github.com/users/kradonneoh/following{/other_user}",
"gists_url... | [] | closed | false | null | [] | null | [
"Hi @kradonneoh, thanks for reporting.\r\n\r\nPlease note that to work with audio datasets (and specifically with MP3 files) we have detailed installation instructions in our docs: https://huggingface.co/docs/datasets/installation#audio\r\n- one of the requirements is torchaudio<0.12.0\r\n\r\nLet us know if the pro... | 2023-01-31T21:25:33Z | 2023-03-02T16:25:14Z | 2023-03-02T16:25:13Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When loading a CommonVoice dataset with `datasets==2.9.0` and `torchaudio>=0.12.0`, I get an error reading the audio arrays:
```python
---------------------------------------------------------------------------
LibsndfileError Traceback (most recent call last)
~/.l... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5488/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5488/timeline | null | completed | null | null | 714.994444 | 2,137 |
https://api.github.com/repos/huggingface/datasets/issues/5487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5487/comments | https://api.github.com/repos/huggingface/datasets/issues/5487/events | https://github.com/huggingface/datasets/issues/5487 | 1,564,480,121 | I_kwDODunzps5dQBJ5 | 5,487 | Incorrect filepath for dill module | {
"avatar_url": "https://avatars.githubusercontent.com/u/35349273?v=4",
"events_url": "https://api.github.com/users/avivbrokman/events{/privacy}",
"followers_url": "https://api.github.com/users/avivbrokman/followers",
"following_url": "https://api.github.com/users/avivbrokman/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Hi! The correct path is still `dill._dill.XXXX` in the latest release. What do you get when you run `python -c \"import dill; print(dill.__version__)\"` in your environment?",
"`0.3.6` I feel like that's bad news, because it's probably not the issue.\r\n\r\nMy mistake, about the wrong path guess. I think I did... | 2023-01-31T15:01:08Z | 2023-02-24T16:18:36Z | 2023-02-24T16:18:36Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I installed the `datasets` package and when I try to `import` it, I get the following error:
```
Traceback (most recent call last):
File "/var/folders/jt/zw5g74ln6tqfdzsl8tx378j00000gn/T/ipykernel_3805/3458380017.py", line 1, in <module>
import datasets
File "/Users/avivbrokman/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5487/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5487/timeline | null | completed | null | null | 577.291111 | 2,138 |
https://api.github.com/repos/huggingface/datasets/issues/5483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5483/comments | https://api.github.com/repos/huggingface/datasets/issues/5483/events | https://github.com/huggingface/datasets/issues/5483 | 1,560,894,690 | I_kwDODunzps5dCVzi | 5,483 | Unable to upload dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Seems to work now, perhaps it was something internal with our university's network."
] | 2023-01-28T15:18:26Z | 2023-01-29T08:09:49Z | 2023-01-29T08:09:49Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Uploading a simple dataset ends with an exception
### Steps to reproduce the bug
I created a new conda env with python 3.10, pip installed datasets and:
```python
>>> from datasets import load_dataset, load_from_disk, Dataset
>>> d = Dataset.from_dict({"text": ["hello"] * 2})
>>> d.pus... | {
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5483/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5483/timeline | null | completed | null | null | 16.856389 | 2,142 |
https://api.github.com/repos/huggingface/datasets/issues/5482 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5482/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5482/comments | https://api.github.com/repos/huggingface/datasets/issues/5482/events | https://github.com/huggingface/datasets/issues/5482 | 1,560,853,137 | I_kwDODunzps5dCLqR | 5,482 | Reload features from Parquet metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": fals... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/6368040?v=4",
"events_url": "https://api.github.com/users/MFreidank/events{/privacy}",
"followers_url": "https://api.github.com/users/MFreidank/followers",
"following_url": "https://api.github.com/users/MFreidank/following{/other_user}",
"gists_url": "h... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/6368040?v=4",
"events_url": "https://api.github.com/users/MFreidank/events{/privacy}",
"followers_url": "https://api.github.com/users/MFreidank/followers",
"following_url": "https://api.github.com/users/MFreidank/following{/other_user}",
"... | null | [
"I'd be happy to have a look, if nobody else has started working on this yet @lhoestq. \r\n\r\nIt seems to me that for the `arrow` format features are currently attached as metadata [in `datasets.arrow_writer`](https://github.com/huggingface/datasets/blob/5f810b7011a8a4ab077a1847c024d2d9e267b065/src/datasets/arrow_... | 2023-01-28T13:12:31Z | 2023-02-12T15:57:02Z | 2023-02-12T15:57:02Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | The idea would be to allow this :
```python
ds.to_parquet("my_dataset/ds.parquet")
reloaded = load_dataset("my_dataset")
assert ds.features == reloaded.features
```
And it should also work with Image and Audio types (right now they're reloaded as a dict type)
This can be implemented by storing and reading th... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5482/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5482/timeline | null | completed | null | null | 362.741944 | 2,143 |
https://api.github.com/repos/huggingface/datasets/issues/5479 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5479/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5479/comments | https://api.github.com/repos/huggingface/datasets/issues/5479/events | https://github.com/huggingface/datasets/issues/5479 | 1,560,357,590 | I_kwDODunzps5dASrW | 5,479 | audiofolder works on local env, but creates empty dataset in a remote one, what dependencies could I be missing/outdated | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | [] | 2023-01-27T20:01:22Z | 2023-01-29T05:23:14Z | 2023-01-29T05:23:14Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I'm using a custom audio dataset (400+ audio files) in the correct format for audiofolder. Although loading the dataset with audiofolder works in one local setup, it doesn't in a remote one (it just creates an empty dataset). I have both ffmpeg and libndfile installed on both computers, what cou... | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5479/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5479/timeline | null | completed | null | null | 33.364444 | 2,146 |
https://api.github.com/repos/huggingface/datasets/issues/5477 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5477/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5477/comments | https://api.github.com/repos/huggingface/datasets/issues/5477/events | https://github.com/huggingface/datasets/issues/5477 | 1,559,909,892 | I_kwDODunzps5c-lYE | 5,477 | Unpin sqlalchemy once issue is fixed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"@albertvillanova It looks like that issue has been fixed so I made a PR to unpin sqlalchemy! ",
"The source issue:\r\n- https://github.com/pandas-dev/pandas/issues/40686\r\n\r\nhas been fixed:\r\n- https://github.com/pandas-dev/pandas/pull/48576\r\n\r\nThe fix was released yesterday (2023-04-03) only in `pandas-... | 2023-01-27T15:01:55Z | 2024-01-26T14:50:45Z | 2024-01-26T14:50:45Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Once the source issue is fixed:
- pandas-dev/pandas#51015
we should revert the pin introduced in:
- #5476 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5477/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5477/timeline | null | completed | null | null | 8,735.813889 | 2,148 |
https://api.github.com/repos/huggingface/datasets/issues/5475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5475/comments | https://api.github.com/repos/huggingface/datasets/issues/5475/events | https://github.com/huggingface/datasets/issues/5475 | 1,559,030,149 | I_kwDODunzps5c7OmF | 5,475 | Dataset scan time is much slower than using native arrow | {
"avatar_url": "https://avatars.githubusercontent.com/u/121845112?v=4",
"events_url": "https://api.github.com/users/jonny-cyberhaven/events{/privacy}",
"followers_url": "https://api.github.com/users/jonny-cyberhaven/followers",
"following_url": "https://api.github.com/users/jonny-cyberhaven/following{/other_us... | [] | closed | false | null | [] | null | [
"Hi ! In your code you only iterate on the Arrow buffers - you don't actually load the data as python objects. For a fair comparison, you can modify your code using:\r\n```diff\r\n- for _ in range(0, len(table), bsz):\r\n- _ = {k:table[k][_ : _ + bsz] for k in cols}\r\n+ for _ in range(0, len(table)... | 2023-01-27T01:32:25Z | 2023-01-30T16:17:11Z | 2023-01-30T16:17:11Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I'm basically running the same scanning experiment from the tutorials https://huggingface.co/course/chapter5/4?fw=pt except now I'm comparing to a native pyarrow version.
I'm finding that the native pyarrow approach is much faster (2 orders of magnitude). Is there something I'm missing that exp... | {
"avatar_url": "https://avatars.githubusercontent.com/u/121845112?v=4",
"events_url": "https://api.github.com/users/jonny-cyberhaven/events{/privacy}",
"followers_url": "https://api.github.com/users/jonny-cyberhaven/followers",
"following_url": "https://api.github.com/users/jonny-cyberhaven/following{/other_us... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5475/timeline | null | completed | null | null | 86.746111 | 2,150 |
https://api.github.com/repos/huggingface/datasets/issues/5474 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5474/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5474/comments | https://api.github.com/repos/huggingface/datasets/issues/5474/events | https://github.com/huggingface/datasets/issues/5474 | 1,558,827,155 | I_kwDODunzps5c6dCT | 5,474 | Column project operation on `datasets.Dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/9336514?v=4",
"events_url": "https://api.github.com/users/daskol/events{/privacy}",
"followers_url": "https://api.github.com/users/daskol/followers",
"following_url": "https://api.github.com/users/daskol/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
},
{
"color": "a2eeef",
... | closed | false | null | [] | null | [
"Hi ! This would be a nice addition indeed :) This sounds like a duplicate of https://github.com/huggingface/datasets/issues/5468\r\n\r\n> Not sure. Some of my PRs are still open and some do not have any discussions.\r\n\r\nSorry to hear that, feel free to ping me on those PRs"
] | 2023-01-26T21:47:53Z | 2023-02-13T09:59:37Z | 2023-02-13T09:59:37Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
There is no operation to select a subset of columns of original dataset. Expected API follows.
```python
a = Dataset.from_dict({
'int': [0, 1, 2]
'char': ['a', 'b', 'c'],
'none': [None] * 3,
})
b = a.project('int', 'char') # usually, .select()
print(a.column_names) # std... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5474/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5474/timeline | null | completed | null | null | 420.195556 | 2,151 |
https://api.github.com/repos/huggingface/datasets/issues/5468 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5468/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5468/comments | https://api.github.com/repos/huggingface/datasets/issues/5468/events | https://github.com/huggingface/datasets/issues/5468 | 1,558,066,625 | I_kwDODunzps5c3jXB | 5,468 | Allow opposite of remove_columns on Dataset and DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/346853?v=4",
"events_url": "https://api.github.com/users/hollance/events{/privacy}",
"followers_url": "https://api.github.com/users/hollance/followers",
"following_url": "https://api.github.com/users/hollance/following{/other_user}",
"gists_url": "https... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | null | [] | null | [
"Hi! I agree it would be nice to have a method like that. Instead of `keep_columns`, we can name it `select_columns` to be more aligned with PyArrow's naming convention (`pa.Table.select`).",
"Hi, I am a newbie to open source and would like to contribute. @mariosasko can I take up this issue ?",
"Hey, I also wa... | 2023-01-26T12:28:09Z | 2023-02-13T09:59:38Z | 2023-02-13T09:59:38Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
In this blog post https://huggingface.co/blog/audio-datasets, I noticed the following code:
```python
COLUMNS_TO_KEEP = ["text", "audio"]
all_columns = gigaspeech["train"].column_names
columns_to_remove = set(all_columns) - set(COLUMNS_TO_KEEP)
gigaspeech = gigaspeech.remove_columns(column... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5468/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5468/timeline | null | completed | null | null | 429.524722 | 2,157 |
https://api.github.com/repos/huggingface/datasets/issues/5465 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5465/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5465/comments | https://api.github.com/repos/huggingface/datasets/issues/5465/events | https://github.com/huggingface/datasets/issues/5465 | 1,557,510,618 | I_kwDODunzps5c1bna | 5,465 | audiofolder creates empty dataset even though the dataset passed in follows the correct structure | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | [] | 2023-01-26T01:45:45Z | 2023-01-26T08:48:45Z | 2023-01-26T08:48:45Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
The structure of my dataset folder called "my_dataset" is : data metadata.csv
The data folder consists of all mp3 files and metadata.csv consist of file locations like 'data/...mp3 and transcriptions. There's 400+ mp3 files and corresponding transcriptions for my dataset.
When I run the follo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5465/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5465/timeline | null | completed | null | null | 7.05 | 2,160 |
https://api.github.com/repos/huggingface/datasets/issues/5464 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5464/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5464/comments | https://api.github.com/repos/huggingface/datasets/issues/5464/events | https://github.com/huggingface/datasets/issues/5464 | 1,557,462,104 | I_kwDODunzps5c1PxY | 5,464 | NonMatchingChecksumError for hendrycks_test | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"Thanks for reporting, @sarahwie.\r\n\r\nPlease note this issue was already fixed in `datasets` 2.6.0 version:\r\n- #5040\r\n\r\nIf you update your `datasets` version, you will be able to load the dataset:\r\n```\r\npip install -U datasets\r\n```",
"Oops, missed that I needed to upgrade. Thanks!"
] | 2023-01-26T00:43:23Z | 2023-01-27T05:44:31Z | 2023-01-26T07:41:58Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
The checksum of the file has likely changed on the remote host.
### Steps to reproduce the bug
`dataset = nlp.load_dataset("hendrycks_test", "anatomy")`
### Expected behavior
no error thrown
### Environment info
- `datasets` version: 2.2.1
- Platform: macOS-13.1-arm64-arm-64bit
- Pyt... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5464/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5464/timeline | null | completed | null | null | 6.976389 | 2,161 |
https://api.github.com/repos/huggingface/datasets/issues/5458 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5458/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5458/comments | https://api.github.com/repos/huggingface/datasets/issues/5458/events | https://github.com/huggingface/datasets/issues/5458 | 1,555,054,737 | I_kwDODunzps5csECR | 5,458 | slice split while streaming | {
"avatar_url": "https://avatars.githubusercontent.com/u/122370631?v=4",
"events_url": "https://api.github.com/users/SvenDS9/events{/privacy}",
"followers_url": "https://api.github.com/users/SvenDS9/followers",
"following_url": "https://api.github.com/users/SvenDS9/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"Hi! Yes, that's correct. When `streaming` is `True`, only split names can be specified as `split`, and for slicing, you have to use `.skip`/`.take` instead.\r\n\r\nE.g. \r\n`load_dataset(\"lhoestq/demo1\",revision=None, streaming=True, split=\"train[:3]\")`\r\n\r\nrewritten with `.skip`/`.take`:\r\n`load_dataset(\... | 2023-01-24T14:08:17Z | 2023-01-24T15:11:47Z | 2023-01-24T15:11:47Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When using the `load_dataset` function with streaming set to True, slicing splits is apparently not supported.
Did I miss this in the documentation?
### Steps to reproduce the bug
`load_dataset("lhoestq/demo1",revision=None, streaming=True, split="train[:3]")`
causes ValueError: Bad split:... | {
"avatar_url": "https://avatars.githubusercontent.com/u/122370631?v=4",
"events_url": "https://api.github.com/users/SvenDS9/events{/privacy}",
"followers_url": "https://api.github.com/users/SvenDS9/followers",
"following_url": "https://api.github.com/users/SvenDS9/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5458/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5458/timeline | null | completed | null | null | 1.058333 | 2,167 |
https://api.github.com/repos/huggingface/datasets/issues/5451 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5451/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5451/comments | https://api.github.com/repos/huggingface/datasets/issues/5451/events | https://github.com/huggingface/datasets/issues/5451 | 1,552,336,300 | I_kwDODunzps5chsWs | 5,451 | ImageFolder BadZipFile: Bad offset for central directory | {
"avatar_url": "https://avatars.githubusercontent.com/u/1524208?v=4",
"events_url": "https://api.github.com/users/hmartiro/events{/privacy}",
"followers_url": "https://api.github.com/users/hmartiro/followers",
"following_url": "https://api.github.com/users/hmartiro/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"Hi ! Could you share the full stack trace ? Which dataset did you try to load ?\r\n\r\nit may be related to https://github.com/huggingface/datasets/pull/5640",
"The `BadZipFile` error means the ZIP file is corrupted, so I'm closing this issue as it's not directly related to `datasets`.",
"For others that find ... | 2023-01-22T23:50:12Z | 2023-05-23T10:35:48Z | 2023-02-10T16:31:36Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I'm getting the following exception:
```
lib/python3.10/zipfile.py:1353 in _RealGetContents │
│ │
│ 1350 │ │ # self.start_dir: Position of start of central directory ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5451/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5451/timeline | null | completed | null | null | 448.69 | 2,174 |
https://api.github.com/repos/huggingface/datasets/issues/5450 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5450/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5450/comments | https://api.github.com/repos/huggingface/datasets/issues/5450/events | https://github.com/huggingface/datasets/issues/5450 | 1,551,109,365 | I_kwDODunzps5cdAz1 | 5,450 | to_tf_dataset with a TF collator causes bizarrely persistent slowdown | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"wtf",
"Couldn't find what's causing this, this will need more investigation",
"A possible hint: The function it seems to be spending a lot of time in (when iterating over the original dataset) is `_get_mp` in the PIL JPEG decoder: \r\n
Briefly, there are several datasets that, when you iterate over them with `to_tf_dataset` **and** a data colla... | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5450/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5450/timeline | null | completed | null | null | 574.0825 | 2,175 |
https://api.github.com/repos/huggingface/datasets/issues/5448 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5448/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5448/comments | https://api.github.com/repos/huggingface/datasets/issues/5448/events | https://github.com/huggingface/datasets/issues/5448 | 1,550,618,514 | I_kwDODunzps5cbI-S | 5,448 | Support fsspec 2023.1.0 in CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-01-20T10:26:31Z | 2023-01-20T13:26:05Z | 2023-01-20T13:26:05Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Once we find out the root cause of:
- #5445
we should revert the temporary pin on fsspec introduced by:
- #5447 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5448/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5448/timeline | null | completed | null | null | 2.992778 | 2,177 |
https://api.github.com/repos/huggingface/datasets/issues/5445 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5445/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5445/comments | https://api.github.com/repos/huggingface/datasets/issues/5445/events | https://github.com/huggingface/datasets/issues/5445 | 1,550,588,703 | I_kwDODunzps5cbBsf | 5,445 | CI tests are broken: AttributeError: 'mappingproxy' object has no attribute 'target' | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-01-20T10:03:10Z | 2023-01-20T10:28:44Z | 2023-01-20T10:28:44Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | CI tests are broken, raising `AttributeError: 'mappingproxy' object has no attribute 'target'`. See: https://github.com/huggingface/datasets/actions/runs/3966497597/jobs/6797384185
```
...
ERROR tests/test_streaming_download_manager.py::TestxPath::test_xpath_rglob[mock://top_level-date=2019-10-0[1-4]/*-expected_path... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5445/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5445/timeline | null | completed | null | null | 0.426111 | 2,180 |
https://api.github.com/repos/huggingface/datasets/issues/5444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5444/comments | https://api.github.com/repos/huggingface/datasets/issues/5444/events | https://github.com/huggingface/datasets/issues/5444 | 1,550,185,071 | I_kwDODunzps5cZfJv | 5,444 | info messages logged as warnings | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | closed | false | null | [] | null | [
"Looks like a duplicate of https://github.com/huggingface/datasets/issues/1948. \r\n\r\nI also think these should be logged as INFO messages, but let's see what @lhoestq thinks.",
"It can be considered unexpected to see a `map` function return instantaneously. The warning is here to explain this case by mentionin... | 2023-01-20T01:19:18Z | 2023-07-12T17:19:31Z | 2023-07-12T17:19:31Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Code in `datasets` is using `logger.warning` when it should be using `logger.info`.
Some of these are probably a matter of opinion, but I think anything starting with `logger.warning(f"Loading chached` clearly falls into the info category.
Definitions from the Python docs for reference:
* I... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5444/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5444/timeline | null | completed | null | null | 4,168.003611 | 2,181 |
https://api.github.com/repos/huggingface/datasets/issues/5442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5442/comments | https://api.github.com/repos/huggingface/datasets/issues/5442/events | https://github.com/huggingface/datasets/issues/5442 | 1,550,084,450 | I_kwDODunzps5cZGli | 5,442 | OneDrive Integrations with HF Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/59222637?v=4",
"events_url": "https://api.github.com/users/Mohammed20201991/events{/privacy}",
"followers_url": "https://api.github.com/users/Mohammed20201991/followers",
"following_url": "https://api.github.com/users/Mohammed20201991/following{/other_use... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! \r\n\r\nWe use [`fsspec`](https://github.com/fsspec/filesystem_spec) to integrate with storage providers. You can find more info (and the usage examples) in [our docs](https://huggingface.co/docs/datasets/v2.8.0/filesystems#download-and-prepare-a-dataset-into-a-cloud-storage).\r\n\r\n[`gdrivefs`](https://githu... | 2023-01-19T23:12:08Z | 2023-02-24T16:17:51Z | 2023-02-24T16:17:51Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
First of all , I would like to thank all community who are developed DataSet storage and make it free available
How to integrate our Onedrive account or any other possible storage clouds (like google drive,...) with the **HF** datasets section.
For example, if I have **50GB** on my **Onedrive*... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5442/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5442/timeline | null | completed | null | null | 857.095278 | 2,183 |
https://api.github.com/repos/huggingface/datasets/issues/5439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5439/comments | https://api.github.com/repos/huggingface/datasets/issues/5439/events | https://github.com/huggingface/datasets/issues/5439 | 1,537,973,564 | I_kwDODunzps5bq508 | 5,439 | [dataset request] Add Common Voice 12.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/31034499?v=4",
"events_url": "https://api.github.com/users/MohammedRakib/events{/privacy}",
"followers_url": "https://api.github.com/users/MohammedRakib/followers",
"following_url": "https://api.github.com/users/MohammedRakib/following{/other_user}",
"g... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_use... | null | [
"@polinaeterna any tentative date on when the Common Voice 12.0 dataset will be added ?",
"This dataset is now hosted on the Hub here: https://huggingface.co/datasets/mozilla-foundation/common_voice_12_0"
] | 2023-01-18T13:07:05Z | 2023-07-21T14:26:10Z | 2023-07-21T14:26:09Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Please add the common voice 12_0 datasets. Apart from English, a significant amount of audio-data has been added to the other minor-language datasets.
### Motivation
The dataset link:
https://commonvoice.mozilla.org/en/datasets
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5439/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5439/timeline | null | completed | null | null | 4,417.317778 | 2,186 |
https://api.github.com/repos/huggingface/datasets/issues/5437 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5437/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5437/comments | https://api.github.com/repos/huggingface/datasets/issues/5437/events | https://github.com/huggingface/datasets/issues/5437 | 1,536,837,144 | I_kwDODunzps5bmkYY | 5,437 | Can't load png dataset with 4 channel (RGBA) | {
"avatar_url": "https://avatars.githubusercontent.com/u/41611046?v=4",
"events_url": "https://api.github.com/users/WiNE-iNEFF/events{/privacy}",
"followers_url": "https://api.github.com/users/WiNE-iNEFF/followers",
"following_url": "https://api.github.com/users/WiNE-iNEFF/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi! Can you please share the directory structure of your image folder and the `load_dataset` call? We decode images with Pillow, and Pillow supports RGBA PNGs, so this shouldn't be a problem.\r\n\r\n",
"> Hi! Can you please share the directory structure of your image folder and the `load_dataset` call? We decode... | 2023-01-17T18:22:27Z | 2023-01-18T20:20:15Z | 2023-01-18T20:20:15Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand.",
"Thanks for reporting, @HaoyuYang59.\r\n\r\nPlease note that these are different \"dataset\" objects: our docs refer to Hugging Face `datasets.Dataset` and not to TensorFlow `tf.data.Datase... | 2023-01-17T10:04:16Z | 2023-01-19T09:56:03Z | 2023-01-19T09:56:03Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shuffle from shuffling the dataset shards order, otherwise the taken examples cou... | {
"avatar_url": "https://avatars.githubusercontent.com/u/80093591?v=4",
"events_url": "https://api.github.com/users/DanielYang59/events{/privacy}",
"followers_url": "https://api.github.com/users/DanielYang59/followers",
"following_url": "https://api.github.com/users/DanielYang59/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5435/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5435/timeline | null | completed | null | null | 47.863056 | 2,190 |
https://api.github.com/repos/huggingface/datasets/issues/5434 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5434/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5434/comments | https://api.github.com/repos/huggingface/datasets/issues/5434/events | https://github.com/huggingface/datasets/issues/5434 | 1,536,090,042 | I_kwDODunzps5bjt-6 | 5,434 | sample_dataset module not found | {
"avatar_url": "https://avatars.githubusercontent.com/u/15816213?v=4",
"events_url": "https://api.github.com/users/nickums/events{/privacy}",
"followers_url": "https://api.github.com/users/nickums/followers",
"following_url": "https://api.github.com/users/nickums/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Hi! Can you describe what the actual error is?",
"working on the setfit example script\r\n\r\n from setfit import SetFitModel, SetFitTrainer, sample_dataset\r\n\r\nImportError: cannot import name 'sample_dataset' from 'setfit' (C:\\Python\\Python38\\lib\\site-packages\\setfit\\__init__.py)\r\n\r\n apart from t... | 2023-01-17T09:57:54Z | 2023-01-19T13:52:12Z | 2023-01-19T07:55:11Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5434/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5434/timeline | null | completed | null | null | 45.954722 | 2,191 |
https://api.github.com/repos/huggingface/datasets/issues/5433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5433/comments | https://api.github.com/repos/huggingface/datasets/issues/5433/events | https://github.com/huggingface/datasets/issues/5433 | 1,536,017,901 | I_kwDODunzps5bjcXt | 5,433 | Support latest Docker image in CI benchmarks | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Sorry, it was us:[^1] https://github.com/iterative/cml/pull/1317 & https://github.com/iterative/cml/issues/1319#issuecomment-1385599559; should be fixed with [v0.18.17](https://github.com/iterative/cml/releases/tag/v0.18.17).\r\n\r\n[^1]: More or less, see https://github.com/yargs/yargs/issues/873.",
"Opened htt... | 2023-01-17T09:06:08Z | 2023-01-18T06:29:08Z | 2023-01-18T06:29:08Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5433/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5433/timeline | null | completed | null | null | 21.383333 | 2,192 |
https://api.github.com/repos/huggingface/datasets/issues/5431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5431/comments | https://api.github.com/repos/huggingface/datasets/issues/5431/events | https://github.com/huggingface/datasets/issues/5431 | 1,535,862,621 | I_kwDODunzps5bi2dd | 5,431 | CI benchmarks are broken: Unknown arguments: runnerPath, path | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-01-17T06:49:57Z | 2023-01-18T06:33:24Z | 2023-01-17T08:51:18Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Our CI benchmarks are broken, raising `Unknown arguments` error: https://github.com/huggingface/datasets/actions/runs/3932397079/jobs/6724905161
```
Unknown arguments: runnerPath, path
```
Stack trace:
```
100%|██████████| 500/500 [00:01<00:00, 338.98ba/s]
Updating lock file 'dvc.lock'
To track the changes ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5431/timeline | null | completed | null | null | 2.0225 | 2,194 |
https://api.github.com/repos/huggingface/datasets/issues/5430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5430/comments | https://api.github.com/repos/huggingface/datasets/issues/5430/events | https://github.com/huggingface/datasets/issues/5430 | 1,535,856,503 | I_kwDODunzps5bi093 | 5,430 | Support Apache Beam >= 2.44.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Some of the shard files now have 0 number of rows.\r\n\r\nWe have opened an issue in the Apache Beam repo:\r\n- https://github.com/apache/beam/issues/25041"
] | 2023-01-17T06:42:12Z | 2024-02-06T19:24:21Z | 2024-02-06T19:24:21Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429 | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5430/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5430/timeline | null | completed | null | null | 9,252.7025 | 2,195 |
https://api.github.com/repos/huggingface/datasets/issues/5428 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5428/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5428/comments | https://api.github.com/repos/huggingface/datasets/issues/5428/events | https://github.com/huggingface/datasets/issues/5428 | 1,535,166,139 | I_kwDODunzps5bgMa7 | 5,428 | Load/Save FAISS index using fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! Sure, feel free to submit a PR. Maybe if we want to be consistent with the existing API, it would be cleaner to directly add support for `fsspec` paths in `Dataset.load_faiss_index`/`Dataset.save_faiss_index` in the same manner as it was done in `Dataset.load_from_disk`/`Dataset.save_to_disk`.",
"That's a gr... | 2023-01-16T16:08:12Z | 2023-03-27T15:18:22Z | 2023-03-27T15:18:22Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
From what I understand `faiss` already support this [link](https://github.com/facebookresearch/faiss/wiki/Index-IO,-cloning-and-hyper-parameter-tuning#generic-io-support)
I would like to use a stream as input to `Dataset.load_faiss_index` and `Dataset.save_faiss_index`.
### Motivation
In... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5428/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5428/timeline | null | completed | null | null | 1,679.169444 | 2,197 |
https://api.github.com/repos/huggingface/datasets/issues/5427 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5427/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5427/comments | https://api.github.com/repos/huggingface/datasets/issues/5427/events | https://github.com/huggingface/datasets/issues/5427 | 1,535,162,889 | I_kwDODunzps5bgLoJ | 5,427 | Unable to download dataset id_clickbait | {
"avatar_url": "https://avatars.githubusercontent.com/u/45941585?v=4",
"events_url": "https://api.github.com/users/ilos-vigil/events{/privacy}",
"followers_url": "https://api.github.com/users/ilos-vigil/followers",
"following_url": "https://api.github.com/users/ilos-vigil/following{/other_user}",
"gists_url"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @ilos-vigil.\r\n\r\nWe have transferred this issue to the corresponding dataset on the Hugging Face Hub: https://huggingface.co/datasets/id_clickbait/discussions/1 "
] | 2023-01-16T16:05:36Z | 2023-01-18T09:51:28Z | 2023-01-18T09:25:19Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I tried to download dataset `id_clickbait`, but receive this error message.
```
FileNotFoundError: Couldn't find file at https://md-datasets-cache-zipfiles-prod.s3.eu-west-1.amazonaws.com/k42j7x2kpn-1.zip
```
When i open the link using browser, i got this XML data.
```xml
<?xml versi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5427/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5427/timeline | null | completed | null | null | 41.328611 | 2,198 |
https://api.github.com/repos/huggingface/datasets/issues/5426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5426/comments | https://api.github.com/repos/huggingface/datasets/issues/5426/events | https://github.com/huggingface/datasets/issues/5426 | 1,535,158,555 | I_kwDODunzps5bgKkb | 5,426 | CI tests are broken: SchemaInferenceError | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-01-16T16:02:07Z | 2023-06-02T06:40:32Z | 2023-01-16T16:49:04Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | CI test (unit, ubuntu-latest, deps-minimum) is broken, raising a `SchemaInferenceError`: see https://github.com/huggingface/datasets/actions/runs/3930901593/jobs/6721492004
```
FAILED tests/test_beam.py::BeamBuilderTest::test_download_and_prepare_sharded - datasets.arrow_writer.SchemaInferenceError: Please pass `feat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5426/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5426/timeline | null | completed | null | null | 0.7825 | 2,199 |
https://api.github.com/repos/huggingface/datasets/issues/5425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5425/comments | https://api.github.com/repos/huggingface/datasets/issues/5425/events | https://github.com/huggingface/datasets/issues/5425 | 1,534,581,850 | I_kwDODunzps5bd9xa | 5,425 | Sort on multiple keys with datasets.Dataset.sort() | {
"avatar_url": "https://avatars.githubusercontent.com/u/101344863?v=4",
"events_url": "https://api.github.com/users/rocco-fortuna/events{/privacy}",
"followers_url": "https://api.github.com/users/rocco-fortuna/followers",
"following_url": "https://api.github.com/users/rocco-fortuna/following{/other_user}",
"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | null | [] | null | [
"Hi! \r\n\r\n`Dataset.sort` calls `df.sort_values` internally, and `df.sort_values` brings all the \"sort\" columns in memory, so sorting on multiple keys could be very expensive. This makes me think that maybe we can replace `df.sort_values` with `pyarrow.compute.sort_indices` - the latter can also sort on multipl... | 2023-01-16T09:22:26Z | 2023-02-24T16:15:11Z | 2023-02-24T16:15:11Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5425/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5425/timeline | null | completed | null | null | 942.879167 | 2,200 |
https://api.github.com/repos/huggingface/datasets/issues/5424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5424/comments | https://api.github.com/repos/huggingface/datasets/issues/5424/events | https://github.com/huggingface/datasets/issues/5424 | 1,534,394,756 | I_kwDODunzps5bdQGE | 5,424 | When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/25720695?v=4",
"events_url": "https://api.github.com/users/macabdul9/events{/privacy}",
"followers_url": "https://api.github.com/users/macabdul9/followers",
"following_url": "https://api.github.com/users/macabdul9/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hi! You can get a `DatasetDict` if you pass a dictionary with read instructions as follows:\r\n```python\r\ninstructions = [\r\n ReadInstruction(split_name=\"train\", from_=0, to=10, unit='%', rounding='closest'),\r\n ReadInstruction(split_name=\"dev\", from_=0, to=10, unit='%', rounding='closest'),\r\n R... | 2023-01-16T06:54:28Z | 2023-02-24T16:19:00Z | 2023-02-24T16:19:00Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict` but instead it is a list of `Dataset`.
### Steps to reproduce the bug
Steps to reproduc... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5424/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5424/timeline | null | completed | null | null | 945.408889 | 2,201 |
https://api.github.com/repos/huggingface/datasets/issues/5421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5421/comments | https://api.github.com/repos/huggingface/datasets/issues/5421/events | https://github.com/huggingface/datasets/issues/5421 | 1,532,278,307 | I_kwDODunzps5bVLYj | 5,421 | Support case-insensitive Hub dataset name in load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Closing as case-insensitivity should be only for URL redirection on the Hub. In the APIs, we will only support the canonical name (https://github.com/huggingface/moon-landing/pull/2399#issuecomment-1382085611)"
] | 2023-01-13T13:07:07Z | 2023-01-13T20:12:32Z | 2023-01-13T20:12:32Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
The dataset name on the Hub is case-insensitive (see https://github.com/huggingface/moon-landing/pull/2399, internal issue), i.e., https://huggingface.co/datasets/GLUE redirects to https://huggingface.co/datasets/glue.
Ideally, we could load the glue dataset using the following:
```
from d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5421/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5421/timeline | null | completed | null | null | 7.090278 | 2,203 |
https://api.github.com/repos/huggingface/datasets/issues/5419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5419/comments | https://api.github.com/repos/huggingface/datasets/issues/5419/events | https://github.com/huggingface/datasets/issues/5419 | 1,531,999,850 | I_kwDODunzps5bUHZq | 5,419 | label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator | {
"avatar_url": "https://avatars.githubusercontent.com/u/172385?v=4",
"events_url": "https://api.github.com/users/CreatixEA/events{/privacy}",
"followers_url": "https://api.github.com/users/CreatixEA/followers",
"following_url": "https://api.github.com/users/CreatixEA/following{/other_user}",
"gists_url": "ht... | [] | closed | false | null | [] | null | [
"Hi! Thanks for pointing out this inconsistency. Changing the default value at this point is probably not worth it, considering we've started discussing the state of the task API internally - we will most likely deprecate the current one and replace it with a more robust solution that relies on the `train_eval_inde... | 2023-01-13T09:40:07Z | 2023-07-21T14:27:08Z | 2023-07-21T14:27:08Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default column name is `label` if binary or `label_ids` if multi-class problem.
It is required to rename the column... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5419/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5419/timeline | null | completed | null | null | 4,540.783611 | 2,205 |
https://api.github.com/repos/huggingface/datasets/issues/5418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5418/comments | https://api.github.com/repos/huggingface/datasets/issues/5418/events | https://github.com/huggingface/datasets/issues/5418 | 1,530,111,184 | I_kwDODunzps5bM6TQ | 5,418 | Add ProgressBar for `to_parquet` | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
... | null | [
"Thanks for your proposal, @zanussbaum. Yes, I agree that would definitely be a nice feature to have!",
"@albertvillanova I’m happy to make a quick PR for the feature! let me know ",
"That would be awesome ! You can comment `#self-assign` to assign you to this issue and open a PR :) Will be happy to review",
... | 2023-01-12T05:06:20Z | 2023-01-24T18:18:24Z | 2023-01-24T18:18:24Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5418/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5418/timeline | null | completed | null | null | 301.201111 | 2,206 |
https://api.github.com/repos/huggingface/datasets/issues/5415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5415/comments | https://api.github.com/repos/huggingface/datasets/issues/5415/events | https://github.com/huggingface/datasets/issues/5415 | 1,526,904,861 | I_kwDODunzps5bArgd | 5,415 | RuntimeError: Sharding is ambiguous for this dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-01-10T07:36:11Z | 2023-01-18T14:09:04Z | 2023-01-18T14:09:03Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When loading some datasets, a RuntimeError is raised.
For example, for "ami" dataset: https://huggingface.co/datasets/ami/discussions/3
```
.../huggingface/datasets/src/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5415/timeline | null | completed | null | null | 198.547778 | 2,208 |
https://api.github.com/repos/huggingface/datasets/issues/5414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5414/comments | https://api.github.com/repos/huggingface/datasets/issues/5414/events | https://github.com/huggingface/datasets/issues/5414 | 1,525,733,818 | I_kwDODunzps5a8Nm6 | 5,414 | Sharding error with Multilingual LibriSpeech | {
"avatar_url": "https://avatars.githubusercontent.com/u/19574344?v=4",
"events_url": "https://api.github.com/users/Nithin-Holla/events{/privacy}",
"followers_url": "https://api.github.com/users/Nithin-Holla/followers",
"following_url": "https://api.github.com/users/Nithin-Holla/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @Nithin-Holla.\r\n\r\nThis is a known issue for multiple datasets and we are investigating it:\r\n- See e.g.: https://huggingface.co/datasets/ami/discussions/3",
"Main issue:\r\n- #5415",
"@albertvillanova Thanks! As a workaround for now, can I use the dataset in streaming mode?",
"Yes,... | 2023-01-09T14:45:31Z | 2023-01-18T14:09:04Z | 2023-01-18T14:09:04Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Loading the German Multilingual LibriSpeech dataset results in a RuntimeError regarding sharding with the following stacktrace:
```
Downloading and preparing dataset multilingual_librispeech/german to /home/nithin/datadrive/cache/huggingface/datasets/facebook___multilingual_librispeech/german/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5414/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5414/timeline | null | completed | null | null | 215.3925 | 2,209 |
https://api.github.com/repos/huggingface/datasets/issues/5413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5413/comments | https://api.github.com/repos/huggingface/datasets/issues/5413/events | https://github.com/huggingface/datasets/issues/5413 | 1,524,591,837 | I_kwDODunzps5a32zd | 5,413 | concatenate_datasets fails when two dataset with shards > 1 and unequal shard numbers | {
"avatar_url": "https://avatars.githubusercontent.com/u/38279341?v=4",
"events_url": "https://api.github.com/users/ZeguanXiao/events{/privacy}",
"followers_url": "https://api.github.com/users/ZeguanXiao/followers",
"following_url": "https://api.github.com/users/ZeguanXiao/following{/other_user}",
"gists_url"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi ! Thanks for reporting :)\r\n\r\nI managed to reproduce the hub using\r\n```python\r\n\r\nfrom datasets import concatenate_datasets, Dataset, load_from_disk\r\n\r\nDataset.from_dict({\"a\": range(9)}).save_to_disk(\"tmp/ds1\")\r\nds1 = load_from_disk(\"tmp/ds1\")\r\nds1 = concatenate_datasets([ds1, ds1])\r\n\r\... | 2023-01-08T17:01:52Z | 2023-01-26T09:27:21Z | 2023-01-26T09:27:21Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When using `concatenate_datasets([dataset1, dataset2], axis = 1)` to concatenate two datasets with shards > 1, it fails:
```
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/combine.py", line 182, in concatenate_datasets
return _concatenate_map_style_data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5413/timeline | null | completed | null | null | 424.424722 | 2,210 |
https://api.github.com/repos/huggingface/datasets/issues/5412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5412/comments | https://api.github.com/repos/huggingface/datasets/issues/5412/events | https://github.com/huggingface/datasets/issues/5412 | 1,524,250,269 | I_kwDODunzps5a2jad | 5,412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | {
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"events_url": "https://api.github.com/users/mtoles/events{/privacy}",
"followers_url": "https://api.github.com/users/mtoles/followers",
"following_url": "https://api.github.com/users/mtoles/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Hi ! It fails because the dataset is already being prepared by your first run. I'd encourage you to prepare your dataset before using it for multiple trainings.\r\n\r\nYou can also specify another cache directory by passing `cache_dir=` to `load_dataset()`.",
"Thank you! What do you mean by prepare it beforehand... | 2023-01-08T00:44:32Z | 2023-01-19T20:28:43Z | 2023-01-19T20:28:43Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"events_url": "https://api.github.com/users/mtoles/events{/privacy}",
"followers_url": "https://api.github.com/users/mtoles/followers",
"following_url": "https://api.github.com/users/mtoles/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5412/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5412/timeline | null | completed | null | null | 283.736389 | 2,211 |
https://api.github.com/repos/huggingface/datasets/issues/5408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5408/comments | https://api.github.com/repos/huggingface/datasets/issues/5408/events | https://github.com/huggingface/datasets/issues/5408 | 1,519,890,752 | I_kwDODunzps5al7FA | 5,408 | dataset map function could not be hash properly | {
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"events_url": "https://api.github.com/users/Tungway1990/events{/privacy}",
"followers_url": "https://api.github.com/users/Tungway1990/followers",
"following_url": "https://api.github.com/users/Tungway1990/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Hi ! On macos I tried with\r\n- py 3.9.11\r\n- datasets 2.8.0\r\n- transformers 4.25.1\r\n- dill 0.3.4\r\n\r\nand I was able to hash `prepare_dataset` correctly:\r\n```python\r\nfrom datasets.fingerprint import Hasher\r\nHasher.hash(prepare_dataset)\r\n```\r\n\r\nWhat version of transformers do you have ? Can you ... | 2023-01-05T01:59:59Z | 2023-01-06T13:22:19Z | 2023-01-06T13:22:18Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"events_url": "https://api.github.com/users/Tungway1990/events{/privacy}",
"followers_url": "https://api.github.com/users/Tungway1990/followers",
"following_url": "https://api.github.com/users/Tungway1990/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5408/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5408/timeline | null | completed | null | null | 35.371944 | 2,215 |
https://api.github.com/repos/huggingface/datasets/issues/5407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5407/comments | https://api.github.com/repos/huggingface/datasets/issues/5407/events | https://github.com/huggingface/datasets/issues/5407 | 1,519,797,345 | I_kwDODunzps5alkRh | 5,407 | Datasets.from_sql() generates deprecation warning | {
"avatar_url": "https://avatars.githubusercontent.com/u/21002157?v=4",
"events_url": "https://api.github.com/users/msummerfield/events{/privacy}",
"followers_url": "https://api.github.com/users/msummerfield/followers",
"following_url": "https://api.github.com/users/msummerfield/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting @msummerfield. We are fixing it."
] | 2023-01-05T00:43:17Z | 2023-01-06T10:59:14Z | 2023-01-06T10:59:14Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5407/timeline | null | completed | null | null | 34.265833 | 2,216 |
https://api.github.com/repos/huggingface/datasets/issues/5399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5399/comments | https://api.github.com/repos/huggingface/datasets/issues/5399/events | https://github.com/huggingface/datasets/issues/5399 | 1,515,548,427 | I_kwDODunzps5aVW8L | 5,399 | Got disconnected from remote data host. Retrying in 5sec [2/20] | {
"avatar_url": "https://avatars.githubusercontent.com/u/46427957?v=4",
"events_url": "https://api.github.com/users/alhuri/events{/privacy}",
"followers_url": "https://api.github.com/users/alhuri/followers",
"following_url": "https://api.github.com/users/alhuri/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [] | 2023-01-01T13:00:11Z | 2023-01-02T07:21:52Z | 2023-01-02T07:21:52Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
While trying to upload my image dataset of a CSV file type to huggingface by running the below code. The dataset consists of a little over 100k of image-caption pairs
### Steps to reproduce the bug
```
df = pd.read_csv('x.csv', encoding='utf-8-sig')
features = Features({
'link': Ima... | {
"avatar_url": "https://avatars.githubusercontent.com/u/46427957?v=4",
"events_url": "https://api.github.com/users/alhuri/events{/privacy}",
"followers_url": "https://api.github.com/users/alhuri/followers",
"following_url": "https://api.github.com/users/alhuri/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5399/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5399/timeline | null | completed | null | null | 18.361389 | 2,224 |
https://api.github.com/repos/huggingface/datasets/issues/5398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5398/comments | https://api.github.com/repos/huggingface/datasets/issues/5398/events | https://github.com/huggingface/datasets/issues/5398 | 1,514,425,231 | I_kwDODunzps5aREuP | 5,398 | Unpin pydantic | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2022-12-30T10:37:31Z | 2022-12-30T10:43:41Z | 2022-12-30T10:43:41Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Once `pydantic` fixes their issue in their 1.10.3 version, unpin it.
See issue:
- #5394
See temporary fix:
- #5395 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5398/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5398/timeline | null | completed | null | null | 0.102778 | 2,225 |
https://api.github.com/repos/huggingface/datasets/issues/5394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5394/comments | https://api.github.com/repos/huggingface/datasets/issues/5394/events | https://github.com/huggingface/datasets/issues/5394 | 1,513,976,229 | I_kwDODunzps5aPXGl | 5,394 | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers' | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I still getting the same error :\r\n\r\n`python -m spacy download fr_core_news_lg\r\n`.\r\n`import spacy`",
"@MFatnassi, this issue and the corresponding fix only affect our Continuous Integration testing environment.\r\n\r\nNote that `datasets` does not depend on `spacy`."
] | 2022-12-29T18:58:44Z | 2022-12-30T10:40:51Z | 2022-12-29T21:00:27Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/hoste... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5394/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5394/timeline | null | completed | null | null | 2.028611 | 2,229 |
https://api.github.com/repos/huggingface/datasets/issues/5391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5391/comments | https://api.github.com/repos/huggingface/datasets/issues/5391/events | https://github.com/huggingface/datasets/issues/5391 | 1,510,350,400 | I_kwDODunzps5aBh5A | 5,391 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it] | {
"avatar_url": "https://avatars.githubusercontent.com/u/12885107?v=4",
"events_url": "https://api.github.com/users/catswithbats/events{/privacy}",
"followers_url": "https://api.github.com/users/catswithbats/followers",
"following_url": "https://api.github.com/users/catswithbats/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"Hey @catswithbats! Super sorry for the late reply! This is happening because there is data with label length (504) that exceeds the model's max length (448). \r\n\r\nThere are two options here:\r\n1. Increase the model's `max_length` parameter: \r\n```python\r\nmodel.config.max_length = 512\r\n```\r\n2. Filter dat... | 2022-12-25T15:17:14Z | 2023-07-21T14:29:47Z | 2023-07-21T14:29:47Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5391/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5391/timeline | null | completed | null | null | 4,991.209167 | 2,232 |
https://api.github.com/repos/huggingface/datasets/issues/5390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5390/comments | https://api.github.com/repos/huggingface/datasets/issues/5390/events | https://github.com/huggingface/datasets/issues/5390 | 1,509,357,553 | I_kwDODunzps5Z9vfx | 5,390 | Error when pushing to the CI hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Hmmm, git bisect tells me that the behavior is the same since https://github.com/huggingface/datasets/commit/67e65c90e9490810b89ee140da11fdd13c356c9c (3 Oct), i.e. https://github.com/huggingface/datasets/pull/4926",
"Maybe related to the discussions in https://github.com/huggingface/datasets/pull/5196",
"Maybe... | 2022-12-23T13:36:37Z | 2022-12-23T20:29:02Z | 2022-12-23T20:29:02Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5390/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5390/timeline | null | completed | null | null | 6.873611 | 2,233 |
https://api.github.com/repos/huggingface/datasets/issues/5388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5388/comments | https://api.github.com/repos/huggingface/datasets/issues/5388/events | https://github.com/huggingface/datasets/issues/5388 | 1,509,042,348 | I_kwDODunzps5Z8iis | 5,388 | Getting Value Error while loading a dataset.. | {
"avatar_url": "https://avatars.githubusercontent.com/u/51160232?v=4",
"events_url": "https://api.github.com/users/valmetisrinivas/events{/privacy}",
"followers_url": "https://api.github.com/users/valmetisrinivas/followers",
"following_url": "https://api.github.com/users/valmetisrinivas/following{/other_user}"... | [] | closed | false | null | [] | null | [
"Hi! I can't reproduce this error locally (Mac) or in Colab. What version of `datasets` are you using?",
"Hi [mariosasko](https://github.com/mariosasko), the datasets version is '2.8.0'.",
"@valmetisrinivas you get that error because you imported `datasets` (and thus `fsspec`) before installing `zstandard`.\r\n... | 2022-12-23T08:16:43Z | 2022-12-29T08:36:33Z | 2022-12-27T17:59:09Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5388/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5388/timeline | null | completed | null | null | 105.707222 | 2,235 |
https://api.github.com/repos/huggingface/datasets/issues/5387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5387/comments | https://api.github.com/repos/huggingface/datasets/issues/5387/events | https://github.com/huggingface/datasets/issues/5387 | 1,508,740,177 | I_kwDODunzps5Z7YxR | 5,387 | Missing documentation page : improve-performance | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi! Our documentation builder does not support links to sections, hence the bug. This is the link it should point to https://huggingface.co/docs/datasets/v2.8.0/en/cache#improve-performance."
] | 2022-12-23T01:12:57Z | 2023-01-24T16:33:40Z | 2023-01-24T16:33:40Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.load_dataset.keep_in_memory
### Steps to reproduce t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5387/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5387/timeline | null | completed | null | null | 783.345278 | 2,236 |
https://api.github.com/repos/huggingface/datasets/issues/5386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5386/comments | https://api.github.com/repos/huggingface/datasets/issues/5386/events | https://github.com/huggingface/datasets/issues/5386 | 1,508,592,918 | I_kwDODunzps5Z600W | 5,386 | `max_shard_size` in `datasets.push_to_hub()` breaks with large files | {
"avatar_url": "https://avatars.githubusercontent.com/u/1086393?v=4",
"events_url": "https://api.github.com/users/salieri/events{/privacy}",
"followers_url": "https://api.github.com/users/salieri/followers",
"following_url": "https://api.github.com/users/salieri/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nThis behavior stems from the fact that we don't always embed image bytes in the underlying arrow table, which can lead to bad size estimation (we use the first 1000 table rows to [estimate](https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.... | 2022-12-22T21:50:58Z | 2022-12-26T23:45:51Z | 2022-12-26T23:45:51Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (up to `~100MB` per file), I've encountered cases where `max_shard_siz... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1086393?v=4",
"events_url": "https://api.github.com/users/salieri/events{/privacy}",
"followers_url": "https://api.github.com/users/salieri/followers",
"following_url": "https://api.github.com/users/salieri/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5386/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5386/timeline | null | completed | null | null | 97.914722 | 2,237 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.