
repo_name stringlengths 9 75 | topic stringclasses 30 values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2 values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
amidaware/tacticalrmm | django | 1,048 | Option to change target for URL Action (including window options) | **Is your feature request related to a problem? Please describe.**
I'm using Guacamole for some of my agents, to allow full RDP into machines. When I use the URL Action to open the link, it always opens in a new tab. I would much prefer if it opened in a new window sans any browser extras (ex. no address bar, bookmarks or tabs)
**Describe the solution you'd like**
Add options to URL Actions which allow you to choose the target of an action (new window/new tab/same tab) and for new window, choose what browser features are available (tab bar, bookmark bar, address bar, etc.)
**Describe alternatives you've considered**
Obviously you can drag the new tab out, but you cant really hide the bars and such. You could potentially use a browser extension, but browser extensions are not always an option. And while I am sure there are third party options, such as "link opening websites" that could handle this, I really do not like the idea of handing potentially sensitive information over to a third party to sell off.
| open | 2022-04-04T20:30:51Z | 2022-04-17T02:32:40Z | https://github.com/amidaware/tacticalrmm/issues/1048 | [
"enhancement"
] | KairuByte | 0 |
autokey/autokey | automation | 201 | Unable to correct problems, you have held broken packages. | ubuntu@ubuntu:/usr/bin$ sudo apt install autokey-gtk
Reading package lists... Done
Building dependency tree
Reading state information... Done
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
autokey-gtk : Depends: autokey-common (= 0.95.1-0ubuntu1) but it is not going to be installed
E: Unable to correct problems, you have held broken packages.
ubuntu@ubuntu:/usr/bin$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04 LTS
Release: 18.04
Codename: bionic
ubuntu@ubuntu:/usr/bin$
| closed | 2018-10-25T19:28:35Z | 2018-10-25T21:18:02Z | https://github.com/autokey/autokey/issues/201 | [] | Smesh292 | 0 |
strawberry-graphql/strawberry-django | graphql | 602 | Test Query Client `asserts_errors` is counter intuitive | N/A (apologies, this should be in strawberry not strawberry-django) | closed | 2024-07-25T15:44:53Z | 2024-07-25T16:07:05Z | https://github.com/strawberry-graphql/strawberry-django/issues/602 | [] | thclark | 2 |
bigscience-workshop/petals | nlp | 522 | Add pre-commit hook | closed | 2023-09-24T14:46:58Z | 2023-09-24T18:35:59Z | https://github.com/bigscience-workshop/petals/issues/522 | [] | mahimairaja | 0 | |
OFA-Sys/Chinese-CLIP | computer-vision | 237 | 训练数据集图文多对多的情况,直接采样分类交叉熵是不是有问题?训练集应该怎么处理? | open | 2023-12-15T07:34:10Z | 2023-12-15T07:34:10Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/237 | [] | FoolishMao | 0 | |
zalandoresearch/fashion-mnist | computer-vision | 25 | Benchmark: ResNet18 and Simple Conv Net | Tried a simple 2-layer conv net and resnet18 on MNIST and Fashion-MNIST. Accuracy is as follows:
|Model|MNIST|Fashion MNIST|
|---|---|---|
|ResNet18| 0.979 | 0.949|
|SimpleNet|0.971|0.919|
#### Preprocessing
Normalization, random horizontal flip, random vertical flip, random translation, random rotation.
You can find the code [here](https://github.com/kefth/fashion-mnist).
| closed | 2017-08-28T21:23:56Z | 2017-08-28T21:50:46Z | https://github.com/zalandoresearch/fashion-mnist/issues/25 | [
"benchmark"
] | kefth | 0 |
slackapi/python-slack-sdk | asyncio | 809 | Setting default filename in web client files_upload causes AttributeError for file being IOBase instance | https://github.com/slackapi/python-slackclient/blob/033fb44f64d5c5f5664a8b6752adf3e4beba7854/slack/web/client.py#L1496
When the input parameter `file` is type `IOBase`, the following attribute error is raised.
```
Traceback (most recent call last):
File "/afs/ThisCell/data/vlsi/eclipz/ct6/verif/p10d2/pscripts/user_modules/change_stats.py", line 456, in <module>
rc = main()
File "/afs/ThisCell/data/vlsi/eclipz/ct6/verif/p10d2/pscripts/user_modules/change_stats.py", line 356, in main
plotter(df)
File "/afs/ThisCell/data/vlsi/eclipz/ct6/verif/p10d2/pscripts/user_modules/change_stats.py", line 286, in plotter
initial_comment='')
File "/afs/ThisCell/func/vlsi/eclipz/ct6/verif/p10d1/.pscripts/pong/user_modules/site-packages/slack/web/client.py", line 1305, in files_upload
kwargs["filename"] = file.split(os.path.sep)[-1]
AttributeError: '_io.BufferedReader' object has no attribute 'split'
```
Since the Slack API [files_upload](https://api.slack.com/methods/files.upload) does not require a filename to upload, I do not believe this method should either.
If this is not acceptable, then at the very least `files_upload` should check for `filename in kwarkgs` to be `True` when `isinstance(file, IOBase) == True`. If the former is false, when the latter is true, it should raise a `SlackRequestError` as it does in the following examples.
https://github.com/slackapi/python-slackclient/blob/033fb44f64d5c5f5664a8b6752adf3e4beba7854/slack/web/client.py#L1487
https://github.com/slackapi/python-slackclient/blob/033fb44f64d5c5f5664a8b6752adf3e4beba7854/slack/web/client.py#L1489 | closed | 2020-09-16T20:14:38Z | 2020-09-17T03:09:12Z | https://github.com/slackapi/python-slack-sdk/issues/809 | [
"Version: 2x",
"bug",
"web-client"
] | csaska | 1 |
pyro-ppl/numpyro | numpy | 1,598 | Clarify how to sample the centered parameter in LocScaleReparam | The documentation for [LocScaleReparam](https://num.pyro.ai/en/stable/reparam.html?highlight=locscalereparam#numpyro.infer.reparam.LocScaleReparam) in case of centeredness mentions that: " If None (default) learn a per-site per-element centering parameter in [0,1]", but upon looking through the implementation of the algorithm, I did not find anything relevant to finding the correct centeredness (as far as I understand the implementation by default it takes the centeredness to be 0.5 and does not optimize it).
Example:
In the case of the eight schools' examples, the ideal centeredness should be close to 0. Still, upon using LocScaleReparam with None as its parameter, we get the centeredness is 0.5, as seen below (which I believe is hard coded in the implementation of LocScaleReparam itself for the case of None).
```
J = 8
y = np.array([28.0, 8.0, -3.0, 7.0, -1.0, 1.0, 18.0, 12.0])
sigma = np.array([15.0, 10.0, 16.0, 11.0, 9.0, 11.0, 10.0, 18.0])
```
```
def eight_schools_noncentered(J, sigma, lambd, y=None):
mu = numpyro.sample('mu', dist.Normal(2, 5))
tau = numpyro.sample('tau', dist.HalfCauchy(5))
with numpyro.plate('J', J):
with numpyro.handlers.reparam(config={'theta': LocScaleReparam(centered=lambd)}):
theta = numpyro.sample('theta', dist.Normal(mu, tau))
numpyro.sample('obs', dist.Normal(theta, sigma), obs=y)
```
```
nuts_kernel = NUTS(eight_schools_noncentered)
mcmc = MCMC(nuts_kernel, num_warmup=1000, num_samples=1000)
rng_key = random.PRNGKey(0)
mcmc.run(rng_key, J, sigma, lambd = None,y=y, extra_fields=('potential_energy',))
mcmc.print_summary()
```
```
mcmc = MCMC(nuts_kernel, num_warmup=1000, num_samples=1000)
mcmc.run(rng_key, J, sigma, lambd = 0.5,y=y, extra_fields=('potential_energy',))
mcmc.print_summary()
```
In the above case both of them provide the same print_summary. Thus, I believe that either the code for the LocScaleReparam should be updated to include SVI for finding the best centeredness or the documentation should be updated accordingly.
| closed | 2023-06-01T12:41:25Z | 2023-06-02T01:34:11Z | https://github.com/pyro-ppl/numpyro/issues/1598 | [
"documentation"
] | Madhav-Kanda | 3 |
gradio-app/gradio | python | 10,363 | Has gr.HTML considered supporting HTML and JavaScript extension page functionality, Or is there any way to support WebSocket/ gr.HTML 是否有考虑支持html与JavaScript扩展页面功能,或是有什么办法支持 websocket | Has gr.HTML considered supporting HTML and JavaScript extension page functionality, Or is there any way to support WebSocket/ gr.HTML 是否有考虑支持html与JavaScript扩展页面功能,或是有什么办法支持 websocket
As follows / 如下:

| closed | 2025-01-15T09:23:32Z | 2025-01-16T00:54:12Z | https://github.com/gradio-app/gradio/issues/10363 | [
"docs/website"
] | gg22mm | 1 |
tqdm/tqdm | pandas | 1,640 | Shouldn't reach 100% when the tasks are not actually finished | - [x] I have marked all applicable categories:
+ [x] exception-raising bug
+ [x] visual output bug
- [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
- [x] I have mentioned version numbers, operating system and
environment, where applicable:
```python
import tqdm, sys
print(tqdm.__version__, sys.version, sys.platform)
4.67.1 3.13.0 (main, Oct 16 2024, 03:23:02) [Clang 18.1.8 ] linux
```
The title should be self-explanatory:
```
100%|███████████████████▍| 5068/5080 [07:28<00:10, 1.15it/s]
```
[source website]: https://github.com/tqdm/tqdm/
[known issues]: https://github.com/tqdm/tqdm/#faq-and-known-issues
[issue tracker]: https://github.com/tqdm/tqdm/issues?q=
| open | 2024-12-10T18:26:07Z | 2025-02-12T22:37:27Z | https://github.com/tqdm/tqdm/issues/1640 | [] | HuStmpHrrr | 3 |
davidsandberg/facenet | tensorflow | 697 | Training a classifier on own images using VGGFace2 model | Hi,
Can we use this script to train our own classifier using the newly released VGGFace2 model i.e.
`python src/classifier.py TRAIN ~/datasets/my_dataset/train/ ~/models/model-20170216-091149.pb ~/models/my_classifier.pkl --batch_size 1000
`
by changing the model dir, do we have to consider any other aspect? | open | 2018-04-14T18:52:34Z | 2018-04-14T18:52:42Z | https://github.com/davidsandberg/facenet/issues/697 | [] | AliAmjad | 0 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 282 | Deprecated dependencies detected | detection.py:25: DeprecationWarning: BICUBIC is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BICUBIC instead.
test.py:18: DeprecationWarning: BILINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.
| open | 2023-09-28T14:37:24Z | 2023-09-28T14:37:24Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/282 | [] | florestankorp | 0 |
deepspeedai/DeepSpeed | pytorch | 5,719 | Issue with LoRA Tuning on llama3-70b using PEFT and TRL's SFTTrainer | We are attempting to perform LoRA tuning on llama3-70b using PEFT with TRL's SFTTrainer. We are using 8 H100 GPUs and distributed training with ZeRO-stage3, but we encounter an error. Could you please provide any solutions?
Here is the error message:
```
Loading checkpoint shards: 77%|███████▋ | 23/30 [00:58<00:25, 3.68s/it]
Loading checkpoint shards: 80%|████████ | 24/30 [00:59<00:17, 2.87s/it]
Loading checkpoint shards: 83%|████████▎ | 25/30 [01:00<00:14, 2.89s/it]
Loading checkpoint shards: 80%|████████ | 24/30 [01:00<00:18, 3.12s/it]
Loading checkpoint shards: 83%|████████▎ | 25/30 [01:01<00:12, 2.47s/it]
Loading checkpoint shards: 87%|████████▋ | 26/30 [01:01<00:09, 2.49s/it]
Loading checkpoint shards: 83%|████████▎ | 25/30 [01:02<00:13, 2.70s/it]
Loading checkpoint shards: 87%|████████▋ | 26/30 [01:02<00:08, 2.18s/it]
Loading checkpoint shards: 90%|█████████ | 27/30 [01:03<00:06, 2.20s/it]
Loading checkpoint shards: 87%|████████▋ | 26/30 [01:03<00:09, 2.36s/it]
Loading checkpoint shards: 90%|█████████ | 27/30 [01:04<00:05, 1.99s/it]
Loading checkpoint shards: 93%|█████████▎| 28/30 [01:04<00:03, 1.99s/it]
Loading checkpoint shards: 90%|█████████ | 27/30 [01:05<00:06, 2.10s/it]
Loading checkpoint shards: 93%|█████████▎| 28/30 [01:05<00:03, 1.85s/it]
Loading checkpoint shards: 97%|█████████▋| 29/30 [01:06<00:01, 1.83s/it]
Loading checkpoint shards: 93%|█████████▎| 28/30 [01:06<00:03, 1.84s/it]
Loading checkpoint shards: 97%|█████████▋| 29/30 [01:06<00:01, 1.65s/it]
Loading checkpoint shards: 100%|██████████| 30/30 [01:06<00:00, 1.50s/it]
Loading checkpoint shards: 100%|██████████| 30/30 [01:06<00:00, 2.23s/it]
Loading checkpoint shards: 100%|██████████| 30/30 [01:07<00:00, 1.37s/it]
Loading checkpoint shards: 100%|██████████| 30/30 [01:07<00:00, 2.26s/it]
[WARNING|logging.py:314] 2024-07-02 18:12:30,312 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 97%|█████████▋| 29/30 [01:07<00:01, 1.59s/it][WARNING|logging.py:314] 2024-07-02 18:12:30,672 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 100%|██████████| 30/30 [01:08<00:00, 1.26s/it]
Loading checkpoint shards: 100%|██████████| 30/30 [01:08<00:00, 2.27s/it]
[WARNING|logging.py:314] 2024-07-02 18:12:31,194 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/trl/trainer/utils.py:116: UserWarning: The pad_token_id and eos_token_id values of this tokenizer are identical. If you are planning for multi-turn training, it can result in the model continuously generating questions and answers without eos token. To avoid this, set the pad_token_id to a different value.
warnings.warn(
/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/trl/trainer/utils.py:116: UserWarning: The pad_token_id and eos_token_id values of this tokenizer are identical. If you are planning for multi-turn training, it can result in the model continuously generating questions and answers without eos token. To avoid this, set the pad_token_id to a different value.
warnings.warn(
/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/trl/trainer/utils.py:116: UserWarning: The pad_token_id and eos_token_id values of this tokenizer are identical. If you are planning for multi-turn training, it can result in the model continuously generating questions and answers without eos token. To avoid this, set the pad_token_id to a different value.
warnings.warn(
[2024-07-02 18:12:37,303] [INFO] [launch.py:319:sigkill_handler] Killing subprocess 14959
[2024-07-02 18:12:37,304] [INFO] [launch.py:319:sigkill_handler] Killing subprocess 14960
Traceback (most recent call last):
File "/work/scripts/train_py/run_clm_sft_update.py", line 686, in <module>
main()
File "/work/scripts/train_py/run_clm_sft_update.py", line 609, in main
trainer = SFTTrainer(
File "/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/trl/trainer/sft_trainer.py", line 278, in __init__
with PartialState().local_main_process_first():
File "/home/user1/.pyenv/versions/3.10.14/lib/python3.10/contextlib.py", line 135, in __enter__
return next(self.gen)
File "/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/accelerate/state.py", line 520, in local_main_process_first
yield from self._goes_first(self.is_local_main_process)
File "/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/accelerate/state.py", line 384, in _goes_first
self.wait_for_everyone()
File "/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/accelerate/state.py", line 378, in wait_for_everyone
torch.distributed.barrier()
File "/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/distributed/c10d_logger.py", line 72, in wrapper
return func(*args, **kwargs)
File "/home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/distributed/distributed_c10d.py", line 3439, in barrier
work = default_pg.barrier(opts=opts)
torch.distributed.DistBackendError: [3] is setting up NCCL communicator and retrieving ncclUniqueId from [0] via c10d key-value store by key '0', but store->get('0') got error: Connection reset by peer
Exception raised from recvBytes at ../torch/csrc/distributed/c10d/Utils.hpp:670 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7fe5eecf4d87 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #1: <unknown function> + 0x5894fde (0x7fe5db5f0fde in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #2: c10d::TCPStore::doWait(c10::ArrayRef<std::string>, std::chrono::duration<long, std::ratio<1l, 1000l> >) + 0x360 (0x7fe5db5eb7f0 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #3: c10d::TCPStore::doGet(std::string const&) + 0x32 (0x7fe5db5ebb32 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #4: c10d::TCPStore::get(std::string const&) + 0xa1 (0x7fe5db5ec961 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #5: c10d::PrefixStore::get(std::string const&) + 0x31 (0x7fe5db5a1dd1 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #6: c10d::PrefixStore::get(std::string const&) + 0x31 (0x7fe5db5a1dd1 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #7: c10d::PrefixStore::get(std::string const&) + 0x31 (0x7fe5db5a1dd1 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #8: c10d::ProcessGroupNCCL::broadcastUniqueNCCLID(ncclUniqueId*, bool, std::string const&, int) + 0xa9 (0x7fe5a47dfc69 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #9: c10d::ProcessGroupNCCL::getNCCLComm(std::string const&, std::vector<c10::Device, std::allocator<c10::Device> > const&, c10d::OpType, int, bool) + 0x22b (0x7fe5a47e6c5b in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #10: <unknown function> + 0x10ad03d (0x7fe5a47f003d in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #11: c10d::ProcessGroupNCCL::allreduce_impl(std::vector<at::Tensor, std::allocator<at::Tensor> >&, c10d::AllreduceOptions const&) + 0x21 (0x7fe5a47f18e1 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #12: c10d::ProcessGroupNCCL::allreduce(std::vector<at::Tensor, std::allocator<at::Tensor> >&, c10d::AllreduceOptions const&) + 0x3bf (0x7fe5a47f38ff in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #13: c10d::ProcessGroupNCCL::barrier(c10d::BarrierOptions const&) + 0xb0e (0x7fe5a4802d4e in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #14: <unknown function> + 0x5838872 (0x7fe5db594872 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #15: <unknown function> + 0x5843590 (0x7fe5db59f590 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #16: <unknown function> + 0x5843695 (0x7fe5db59f695 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #17: <unknown function> + 0x4e8937c (0x7fe5dabe537c in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #18: <unknown function> + 0x1a08a38 (0x7fe5d7764a38 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #19: <unknown function> + 0x584cca4 (0x7fe5db5a8ca4 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #20: <unknown function> + 0x584da55 (0x7fe5db5a9a55 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_cpu.so)
frame #21: <unknown function> + 0xc93e88 (0x7fe5ede1ee88 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_python.so)
frame #22: <unknown function> + 0x413ef4 (0x7fe5ed59eef4 in /home/user1/.pyenv/versions/3.10.14/lib/python3.10/site-packages/torch/lib/libtorch_python.so)
<omitting python frames>
frame #58: <unknown function> + 0x29d90 (0x7fe5ef964d90 in /usr/lib/x86_64-linux-gnu/libc.so.6)
frame #59: __libc_start_main + 0x80 (0x7fe5ef964e40 in /usr/lib/x86_64-linux-gnu/libc.so.6)
frame #60: _start + 0x25 (0x55b3be923095 in /home/user1/.pyenv/versions/3.10.14/bin/python3.10)
. This may indicate a possible application crash on rank 0 or a network set up issue.
```
Additionally, it's very strange because it worked correctly during a previous test run. Below is the log from that run. We haven't changed the code since then, but now we are encountering a new error.
One point of concern is that in the successful run log, there is a message:
```
[INFO|modeling_utils.py:3363] 2024-07-01 15:02:46,215 >> Detected DeepSpeed ZeRO-3: activating zero.init() for this model
```
before loading the model. However, this message is missing in the current log, and it seems the model is loaded into CPU memory first (previously, it was loaded directly into GPU memory).
Training Python Scripts:
```
import logging
import os
from contextlib import nullcontext
TRL_USE_RICH = os.environ.get("TRL_USE_RICH", False)
from trl.commands.cli_utils import init_zero_verbose, SFTScriptArguments, TrlParser
if TRL_USE_RICH:
init_zero_verbose()
FORMAT = "%(message)s"
from rich.console import Console
from rich.logging import RichHandler
import torch
from datasets import load_dataset
from tqdm.rich import tqdm
from transformers import AutoTokenizer
from trl import (
ModelConfig,
RichProgressCallback,
SFTConfig,
SFTTrainer,
get_peft_config,
get_quantization_config,
get_kbit_device_map,
)
tqdm.pandas()
if TRL_USE_RICH:
logging.basicConfig(format=FORMAT, datefmt="[%X]", handlers=[RichHandler()], level=logging.INFO)
if __name__ == "__main__":
parser = TrlParser((SFTScriptArguments, SFTConfig, ModelConfig))
args, training_args, model_config = parser.parse_args_and_config()
# Force use our print callback
if TRL_USE_RICH:
training_args.disable_tqdm = True
console = Console()
################
# Model & Tokenizer
################
torch_dtype = (
model_config.torch_dtype
if model_config.torch_dtype in ["auto", None]
else getattr(torch, model_config.torch_dtype)
)
quantization_config = get_quantization_config(model_config)
model_kwargs = dict(
revision=model_config.model_revision,
trust_remote_code=model_config.trust_remote_code,
attn_implementation=model_config.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_config.model_name_or_path, use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
################
# Dataset
################
raw_datasets = load_dataset(args.dataset_name)
train_dataset = raw_datasets[args.dataset_train_split]
eval_dataset = raw_datasets[args.dataset_test_split]
################
# Optional rich context managers
###############
init_context = nullcontext() if not TRL_USE_RICH else console.status("[bold green]Initializing the SFTTrainer...")
save_context = (
nullcontext()
if not TRL_USE_RICH
else console.status(f"[bold green]Training completed! Saving the model to {training_args.output_dir}")
)
################
# Training
################
with init_context:
trainer = SFTTrainer(
model=model_config.model_name_or_path,
model_init_kwargs=model_kwargs,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
peft_config=get_peft_config(model_config),
callbacks=[RichProgressCallback] if TRL_USE_RICH else None,
)
trainer.train()
with save_context:
trainer.save_model(training_args.output_dir)
```
Training ShellScripts:
```
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
time \
deepspeed \
sft.py \
--deepspeed ds_config_zero3.json \
--dataset_dir mytest \
--model_name_or_path meta-llama/Meta-Llama-3-70B-Instruct \
--tokenizer_name meta-llama/Meta-Llama-3-70B-Instruct \
--num_train_epochs 5 \
--do_train \
--do_eval \
--bf16 \
--output_dir ./lora-test \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--learning_rate=5e-6 \
--lr_scheduler_type "constant" \
--warmup_ratio 0.03 \
--logging_steps 1 \
--evaluation_strategy steps \
--evaluation_steps 100 \
--save_strategy epoch \
--overwrite_output_dir \
--gradient_checkpointing \
--use_peft True \
--lora_r 16 \
--ddp_timeout 72000 \
--lora_alpha 32 \
--lora_dropout 0.05 \
--lora_target_modules q_proj v_proj k_proj o_proj gate_proj down_proj up_proj \
```
DeepSpeed Config:
```
{
"bf16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"reduce_bucket_size": 5e7,
"stage3_prefetch_bucket_size": 5e7,
"stage3_param_persistence_threshold": 0,
"stage3_max_live_parameters": 1e8,
"stage3_max_reuse_distance": 1e8,
"sub_group_size": 5e7,
"stage3_gather_fp16_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
``` | open | 2024-07-02T09:37:29Z | 2024-07-02T16:04:35Z | https://github.com/deepspeedai/DeepSpeed/issues/5719 | [
"training"
] | yutanozaki1 | 0 |
robusta-dev/robusta | automation | 1,057 | globalConfig.prometheus_url dont work with path and trailing slash | **Describe the bug**
When we set the prometheus_url to "http://prometheus-operated.monitor:9090/prometheus/" it's not detected, and don't work
If we instead set it to "http://prometheus-operated.monitor:9090/prometheus" (without the trailing '/') it works just fine,
**To Reproduce**
(see above)
**Expected behavior**
Both values should work, or update documentation
Latest affected version: 0.10.22 | open | 2023-08-25T07:59:19Z | 2023-11-21T11:19:15Z | https://github.com/robusta-dev/robusta/issues/1057 | [
"bug"
] | ninlil | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 964 | Not sure if my Directory is wrong or i'm missing something but i get hit by this.What am i doing wrong? Thanks in advance :) | ERROR: Command errored out with exit status 1:
command: 'D:\python\python.exe' 'D:\python\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py' prepare_metadata_for_build_wheel 'C:\Users\yasin\AppData\Local\Temp\tmp3hdlg1od'
cwd: C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4
Complete output (135 lines):
setup.py:66: RuntimeWarning: NumPy 1.20.3 may not yet support Python 3.10.
warnings.warn(
Running from numpy source directory.
setup.py:485: UserWarning: Unrecognized setuptools command, proceeding with generating Cython sources and expanding templates
run_build = parse_setuppy_commands()
Processing numpy/random\_bounded_integers.pxd.in
Processing numpy/random\bit_generator.pyx
Processing numpy/random\mtrand.pyx
Processing numpy/random\_bounded_integers.pyx.in
Processing numpy/random\_common.pyx
Processing numpy/random\_generator.pyx
Processing numpy/random\_mt19937.pyx
Processing numpy/random\_pcg64.pyx
Processing numpy/random\_philox.pyx
Processing numpy/random\_sfc64.pyx
Cythonizing sources
Could not locate executable g77
Could not locate executable f77
Could not locate executable ifort
Could not locate executable ifl
Could not locate executable f90
Could not locate executable DF
Could not locate executable efl
Could not locate executable gfortran
Could not locate executable f95
Could not locate executable g95
Could not locate executable efort
Could not locate executable efc
Could not locate executable flang
don't know how to compile Fortran code on platform 'nt'
C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\system_info.py:1989: UserWarning:
Optimized (vendor) Blas libraries are not found.
Falls back to netlib Blas library which has worse performance.
A better performance should be easily gained by switching
Blas library.
if self._calc_info(blas):
C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\system_info.py:1989: UserWarning:
Blas (http://www.netlib.org/blas/) libraries not found.
Directories to search for the libraries can be specified in the
numpy/distutils/site.cfg file (section [blas]) or by setting
the BLAS environment variable.
if self._calc_info(blas):
C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\system_info.py:1989: UserWarning:
Blas (http://www.netlib.org/blas/) sources not found.
Directories to search for the sources can be specified in the
numpy/distutils/site.cfg file (section [blas_src]) or by setting
the BLAS_SRC environment variable.
if self._calc_info(blas):
C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\system_info.py:1849: UserWarning:
Lapack (http://www.netlib.org/lapack/) libraries not found.
Directories to search for the libraries can be specified in the
numpy/distutils/site.cfg file (section [lapack]) or by setting
the LAPACK environment variable.
return getattr(self, '_calc_info_{}'.format(name))()
C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\system_info.py:1849: UserWarning:
Lapack (http://www.netlib.org/lapack/) sources not found.
Directories to search for the sources can be specified in the
numpy/distutils/site.cfg file (section [lapack_src]) or by setting
the LAPACK_SRC environment variable.
return getattr(self, '_calc_info_{}'.format(name))()
C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\dist.py:275: UserWarning: Unknown distribution option: 'define_macros'
warnings.warn(msg)
non-existing path in 'numpy\\distutils': 'site.cfg'
running dist_info
running build_src
creating build
creating build\src.win-amd64-3.10
creating build\src.win-amd64-3.10\numpy
creating build\src.win-amd64-3.10\numpy\distutils
Traceback (most recent call last):
File "D:\python\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 363, in <module>
main()
File "D:\python\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 345, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
File "D:\python\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 164, in prepare_metadata_for_build_wheel
return hook(metadata_directory, config_settings)
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\build_meta.py", line 157, in prepare_metadata_for_build_wheel
self.run_setup()
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\build_meta.py", line 248, in run_setup
super(_BuildMetaLegacyBackend,
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\build_meta.py", line 142, in run_setup
exec(compile(code, __file__, 'exec'), locals())
File "setup.py", line 513, in <module>
setup_package()
File "setup.py", line 505, in setup_package
setup(**metadata)
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\core.py", line 169, in setup
return old_setup(**new_attr)
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\__init__.py", line 165, in setup
return distutils.core.setup(**attrs)
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\core.py", line 148, in setup
dist.run_commands()
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\dist.py", line 967, in run_commands
self.run_command(cmd)
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\dist.py", line 986, in run_command
cmd_obj.run()
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\command\dist_info.py", line 31, in run
egg_info.run()
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\egg_info.py", line 24, in run
self.run_command("build_src")
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\dist.py", line 986, in run_command
cmd_obj.run()
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\build_src.py", line 144, in run
self.build_sources()
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\build_src.py", line 155, in build_sources
self.build_library_sources(*libname_info)
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\build_src.py", line 288, in build_library_sources
sources = self.generate_sources(sources, (lib_name, build_info))
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\build_src.py", line 378, in generate_sources
source = func(extension, build_dir)
File "numpy\core\setup.py", line 671, in get_mathlib_info
st = config_cmd.try_link('int main(void) { return 0;}')
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\command\config.py", line 243, in try_link
self._link(body, headers, include_dirs,
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\config.py", line 162, in _link
return self._wrap_method(old_config._link, lang,
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\config.py", line 96, in _wrap_method
ret = mth(*((self,)+args))
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\command\config.py", line 137, in _link
(src, obj) = self._compile(body, headers, include_dirs, lang)
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\config.py", line 105, in _compile
src, obj = self._wrap_method(old_config._compile, lang,
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\command\config.py", line 96, in _wrap_method
ret = mth(*((self,)+args))
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\command\config.py", line 132, in _compile
self.compiler.compile([src], include_dirs=include_dirs)
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\_msvccompiler.py", line 401, in compile
self.spawn(args)
File "C:\Users\yasin\AppData\Local\Temp\pip-build-env-6pkcd6kp\overlay\Lib\site-packages\setuptools\_distutils\_msvccompiler.py", line 505, in spawn
return super().spawn(cmd, env=env)
File "C:\Users\yasin\AppData\Local\Temp\pip-install-594l2te2\numpy_6377a46b864645e683fccdd25c76f1f4\numpy\distutils\ccompiler.py", line 90, in <lambda>
m = lambda self, *args, **kw: func(self, *args, **kw)
TypeError: CCompiler_spawn() got an unexpected keyword argument 'env'
----------------------------------------
WARNING: Discarding https://files.pythonhosted.org/packages/f3/1f/fe9459e39335e7d0e372b5e5dcd60f4381d3d1b42f0b9c8222102ff29ded/numpy-1.20.3.zip#sha256=e55185e51b18d788e49fe8305fd73ef4470596b33fc2c1ceb304566b99c71a69 (from https://pypi.org/simple/numpy/) (requires-python:>=3.7). Command errored out with exit status 1: 'D:\python\python.exe' 'D:\python\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py' prepare_metadata_for_build_wheel 'C:\Users\yasin\AppData\Local\Temp\tmp3hdlg1od' Check the logs for full command output.
ERROR: Could not find a version that satisfies the requirement numpy==1.20.3 (from versions: 1.3.0, 1.4.1, 1.5.0, 1.5.1, 1.6.0, 1.6.1, 1.6.2, 1.7.0, 1.7.1, 1.7.2, 1.8.0, 1.8.1, 1.8.2, 1.9.0, 1.9.1, 1.9.2, 1.9.3, 1.10.0.post2, 1.10.1, 1.10.2, 1.10.4, 1.11.0, 1.11.1, 1.11.2, 1.11.3, 1.12.0, 1.12.1, 1.13.0rc1, 1.13.0rc2, 1.13.0, 1.13.1, 1.13.3, 1.14.0rc1, 1.14.0, 1.14.1, 1.14.2, 1.14.3, 1.14.4, 1.14.5, 1.14.6, 1.15.0rc1, 1.15.0rc2, 1.15.0, 1.15.1, 1.15.2, 1.15.3, 1.15.4, 1.16.0rc1, 1.16.0rc2, 1.16.0, 1.16.1, 1.16.2, 1.16.3, 1.16.4, 1.16.5, 1.16.6, 1.17.0rc1, 1.17.0rc2, 1.17.0, 1.17.1, 1.17.2, 1.17.3, 1.17.4, 1.17.5, 1.18.0rc1, 1.18.0, 1.18.1, 1.18.2, 1.18.3, 1.18.4, 1.18.5, 1.19.0rc1, 1.19.0rc2, 1.19.0, 1.19.1, 1.19.2, 1.19.3, 1.19.4, 1.19.5, 1.20.0rc1, 1.20.0rc2, 1.20.0, 1.20.1, 1.20.2, 1.20.3, 1.21.0rc1, 1.21.0rc2, 1.21.0, 1.21.1, 1.21.2, 1.21.3, 1.21.4, 1.21.5, 1.22.0rc1, 1.22.0rc2, 1.22.0rc3)
ERROR: No matching distribution found for numpy==1.20.3 | closed | 2021-12-28T18:35:06Z | 2021-12-28T19:52:35Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/964 | [] | santaonholidays | 1 |
freqtrade/freqtrade | python | 10,812 | Ta-Lib installation failed | <!--
I have problem to install this, while i try install requirements from repository
Please do not use the question template to report bugs or to request new features.
-->
## Describe your environment
* Operating system:WIN 11 / WSL
* Python Version: Python 3.10.15

| closed | 2024-10-19T22:29:13Z | 2024-10-20T06:38:35Z | https://github.com/freqtrade/freqtrade/issues/10812 | [
"Question",
"Install"
] | orchideaZ | 2 |
AntonOsika/gpt-engineer | python | 776 | sub directories not generating which are mentioned in all_outputs.txt | ## all_output.txt:
[2023-10-06T06:08:10.051Z] Here is the content of each file necessary to achieve the goal:
[2023-10-06T06:08:10.052Z] main.tf
[2023-10-06T06:08:10.053Z] ```
[2023-10-06T06:08:11.054Z] # Configure the Azure provider
[2023-10-06T06:08:11.056Z] provider "azurerm" {
[2023-10-06T06:08:11.056Z] features {}
[2023-10-06T06:08:11.057Z] }
[2023-10-06T06:08:11.058Z] # Create the resource group
[2023-10-06T06:08:11.061Z] resource "azurerm_resource_group" "resource_group" {
[2023-10-06T06:08:12.026Z] name = var.resource_group_name
[2023-10-06T06:08:12.027Z] location = var.resource_group_location
[2023-10-06T06:08:12.028Z] }
[2023-10-06T06:08:12.029Z] # Create the virtual network
[2023-10-06T06:08:12.030Z] module "vnet" {
[2023-10-06T06:08:12.673Z] source = "./modules/vnet"
[2023-10-06T06:08:12.676Z] vnet_name = var.vnet_name
[2023-10-06T06:08:12.679Z] vnet_address_space = var.vnet_address_space
[2023-10-06T06:08:12.681Z] web_subnet_name = var.web_subnet_name
[2023-10-06T06:08:13.341Z] web_subnet_address = var.web_subnet_address
[2023-10-06T06:08:13.344Z] func_subnet_name = var.func_subnet_name
[2023-10-06T06:08:13.347Z] func_subnet_address = var.func_subnet_address
[2023-10-06T06:08:14.506Z] resource_group_name = azurerm_resource_group.resource_group.name
[2023-10-06T06:08:14.506Z] }
[2023-10-06T06:08:14.508Z] # Create the app service plan
[2023-10-06T06:08:14.509Z] module "app_service_plan" {
[2023-10-06T06:08:14.511Z] source = "./modules/app_service_plan"
[2023-10-06T06:08:15.415Z] app_service_plan_name = var.app_service_plan_name
[2023-10-06T06:08:15.417Z] app_service_plan_sku = var.app_service_plan_sku
[2023-10-06T06:08:16.459Z] resource_group_name = azurerm_resource_group.resource_group.name
[2023-10-06T06:08:16.460Z] }
[2023-10-06T06:08:16.461Z] # Create the web app
[2023-10-06T06:08:16.462Z] module "web_app" {
[2023-10-06T06:08:16.464Z] source = "./modules/web_app"
[2023-10-06T06:08:17.656Z] app_service_plan_id = module.app_service_plan.app_service_plan_id
[2023-10-06T06:08:17.659Z] web_app_name = var.web_app_name
[2023-10-06T06:08:17.665Z] web_subnet_id = module.vnet.web_subnet_id
[2023-10-06T06:08:18.520Z] resource_group_name = azurerm_resource_group.resource_group.name
[2023-10-06T06:08:18.520Z] }
[2023-10-06T06:08:18.522Z] # Create the function app
[2023-10-06T06:08:18.524Z] module "function_app" {
[2023-10-06T06:08:18.527Z] source = "./modules/function_app"
[2023-10-06T06:08:19.561Z] function_app_name = var.function_app_name
[2023-10-06T06:08:19.564Z] storage_account_id = module.storage_account.storage_account_id
[2023-10-06T06:08:20.650Z] app_service_plan_id = module.app_service_plan.app_service_plan_id
[2023-10-06T06:08:20.653Z] function_app_location = var.function_app_location
[2023-10-06T06:08:20.657Z] resource_group_name = azurerm_resource_group.resource_group.name
[2023-10-06T06:08:20.657Z] }
[2023-10-06T06:08:21.459Z] # Create the storage account
[2023-10-06T06:08:21.460Z] module "storage_account" {
[2023-10-06T06:08:21.462Z] source = "./modules/storage_account"
[2023-10-06T06:08:22.280Z] storage_account_name = var.storage_account_name
[2023-10-06T06:08:22.283Z] storage_account_location = var.storage_account_location
[2023-10-06T06:08:22.286Z] storage_account_tier = var.storage_account_tier
[2023-10-06T06:08:23.169Z] storage_account_kind = var.storage_account_kind
[2023-10-06T06:08:23.172Z] resource_group_name = azurerm_resource_group.resource_group.name
[2023-10-06T06:08:23.172Z] }
[2023-10-06T06:08:23.172Z] ```
[2023-10-06T06:08:23.173Z] variables.tf
[2023-10-06T06:08:23.173Z] ```
[2023-10-06T06:08:24.019Z] variable "resource_group_name" {
[2023-10-06T06:08:24.022Z] description = "The name of the resource group."
[2023-10-06T06:08:24.022Z] }
[2023-10-06T06:08:24.024Z] variable "resource_group_location" {
[2023-10-06T06:08:25.018Z] description = "The location of the resource group."
[2023-10-06T06:08:25.018Z] }
[2023-10-06T06:08:25.020Z] variable "vnet_name" {
[2023-10-06T06:08:25.023Z] description = "The name of the virtual network."
[2023-10-06T06:08:25.023Z] }
[2023-10-06T06:08:25.024Z] variable "vnet_address_space" {
[2023-10-06T06:08:25.847Z] description = "The address space of the virtual network."
[2023-10-06T06:08:25.848Z] }
[2023-10-06T06:08:25.849Z] variable "web_subnet_name" {
[2023-10-06T06:08:25.852Z] description = "The name of the subnet for the web app."
[2023-10-06T06:08:25.852Z] }
[2023-10-06T06:08:25.854Z] variable "web_subnet_address" {
[2023-10-06T06:08:26.604Z] description = "The address of the subnet for the web app."
[2023-10-06T06:08:26.604Z] }
[2023-10-06T06:08:26.606Z] variable "func_subnet_name" {
[2023-10-06T06:08:26.609Z] description = "The name of the subnet for the function app."
[2023-10-06T06:08:26.609Z] }
[2023-10-06T06:08:27.243Z] variable "func_subnet_address" {
[2023-10-06T06:08:27.246Z] description = "The address of the subnet for the function app."
[2023-10-06T06:08:27.247Z] }
[2023-10-06T06:08:27.248Z] variable "app_service_plan_name" {
[2023-10-06T06:08:28.133Z] description = "The name of the app service plan."
[2023-10-06T06:08:28.133Z] }
[2023-10-06T06:08:28.135Z] variable "app_service_plan_sku" {
[2023-10-06T06:08:28.138Z] description = "The SKU of the app service plan."
[2023-10-06T06:08:28.138Z] }
[2023-10-06T06:08:28.140Z] variable "web_app_name" {
[2023-10-06T06:08:28.922Z] description = "The name of the web app."
[2023-10-06T06:08:28.923Z] }
[2023-10-06T06:08:28.924Z] variable "function_app_name" {
[2023-10-06T06:08:28.927Z] description = "The name of the function app."
[2023-10-06T06:08:28.927Z] }
[2023-10-06T06:08:28.928Z] variable "function_app_location" {
[2023-10-06T06:08:29.635Z] description = "The location of the function app."
[2023-10-06T06:08:29.635Z] }
[2023-10-06T06:08:29.636Z] variable "storage_account_name" {
[2023-10-06T06:08:29.639Z] description = "The name of the storage account."
[2023-10-06T06:08:29.639Z] }
[2023-10-06T06:08:30.277Z] variable "storage_account_location" {
[2023-10-06T06:08:30.280Z] description = "The location of the storage account."
[2023-10-06T06:08:30.280Z] }
[2023-10-06T06:08:30.281Z] variable "storage_account_tier" {
[2023-10-06T06:08:30.985Z] description = "The tier of the storage account."
[2023-10-06T06:08:30.985Z] }
[2023-10-06T06:08:30.987Z] variable "storage_account_kind" {
[2023-10-06T06:08:30.989Z] description = "The kind of the storage account."
[2023-10-06T06:08:30.989Z] }
[2023-10-06T06:08:30.990Z] ```
[2023-10-06T06:08:30.990Z] outputs.tf
[2023-10-06T06:08:30.991Z] ```
[2023-10-06T06:08:31.845Z] output "web_app_url" {
[2023-10-06T06:08:31.847Z] value = module.web_app.web_app_url
[2023-10-06T06:08:31.847Z] }
[2023-10-06T06:08:31.849Z] output "function_app_url" {
[2023-10-06T06:08:31.851Z] value = module.function_app.function_app_url
[2023-10-06T06:08:31.851Z] }
[2023-10-06T06:08:31.851Z] ```
[2023-10-06T06:08:31.852Z] provider.tf
[2023-10-06T06:08:31.852Z] ```
[2023-10-06T06:08:32.879Z] provider "azurerm" {
[2023-10-06T06:08:32.880Z] features {}
[2023-10-06T06:08:32.880Z] }
[2023-10-06T06:08:32.881Z] ```
[2023-10-06T06:08:32.882Z] backend.tf
[2023-10-06T06:08:32.882Z] ```
[2023-10-06T06:08:32.883Z] terraform {
[2023-10-06T06:08:32.885Z] backend "azurerm" {}
[2023-10-06T06:08:32.885Z] }
[2023-10-06T06:08:32.886Z] ```
[2023-10-06T06:08:32.887Z] modules/vnet/main.tf
[2023-10-06T06:08:32.888Z] ```
[2023-10-06T06:08:33.785Z] resource "azurerm_virtual_network" "virtual_network" {
[2023-10-06T06:08:33.787Z] name = var.vnet_name
[2023-10-06T06:08:33.790Z] address_space = [var.vnet_address_space]
[2023-10-06T06:08:34.489Z] location = var.resource_group_location
[2023-10-06T06:08:34.491Z] resource_group_name = var.resource_group_name
[2023-10-06T06:08:34.492Z] subnet {
[2023-10-06T06:08:34.494Z] name = var.web_subnet_name
[2023-10-06T06:08:35.429Z] address_prefix = var.web_subnet_address
[2023-10-06T06:08:35.430Z] }
[2023-10-06T06:08:35.430Z] subnet {
[2023-10-06T06:08:35.433Z] name = var.func_subnet_name
[2023-10-06T06:08:35.435Z] address_prefix = var.func_subnet_address
[2023-10-06T06:08:35.436Z] }
[2023-10-06T06:08:35.436Z] }
[2023-10-06T06:08:35.438Z] output "web_subnet_id" {
[2023-10-06T06:08:36.533Z] value = azurerm_virtual_network.virtual_network.subnets[0].id
[2023-10-06T06:08:36.533Z] }
[2023-10-06T06:08:36.535Z] output "func_subnet_id" {
[2023-10-06T06:08:36.539Z] value = azurerm_virtual_network.virtual_network.subnets[1].id
[2023-10-06T06:08:36.539Z] }
[2023-10-06T06:08:36.540Z] ```
[2023-10-06T06:08:37.595Z] modules/vnet/variables.tf
[2023-10-06T06:08:37.595Z] ```
[2023-10-06T06:08:37.598Z] variable "vnet_name" {
[2023-10-06T06:08:37.600Z] description = "The name of the virtual network."
[2023-10-06T06:08:37.600Z] }
[2023-10-06T06:08:37.602Z] variable "vnet_address_space" {
[2023-10-06T06:08:38.484Z] description = "The address space of the virtual network."
[2023-10-06T06:08:38.484Z] }
[2023-10-06T06:08:38.486Z] variable "web_subnet_name" {
[2023-10-06T06:08:38.489Z] description = "The name of the subnet for the web app."
[2023-10-06T06:08:38.489Z] }
[2023-10-06T06:08:39.154Z] variable "web_subnet_address" {
[2023-10-06T06:08:39.157Z] description = "The address of the subnet for the web app."
[2023-10-06T06:08:39.157Z] }
[2023-10-06T06:08:39.158Z] variable "func_subnet_name" {
[2023-10-06T06:08:39.861Z] description = "The name of the subnet for the function app."
[2023-10-06T06:08:39.861Z] }
[2023-10-06T06:08:39.863Z] variable "func_subnet_address" {
[2023-10-06T06:08:39.866Z] description = "The address of the subnet for the function app."
[2023-10-06T06:08:39.866Z] }
[2023-10-06T06:08:40.574Z] variable "resource_group_name" {
[2023-10-06T06:08:40.576Z] description = "The name of the resource group."
[2023-10-06T06:08:40.576Z] }
[2023-10-06T06:08:40.578Z] variable "resource_group_location" {
[2023-10-06T06:08:41.431Z] description = "The location of the resource group."
[2023-10-06T06:08:41.431Z] }
[2023-10-06T06:08:41.431Z] ```
[2023-10-06T06:08:41.443Z] modules/vnet/outputs.tf
[2023-10-06T06:08:41.443Z] ```
[2023-10-06T06:08:41.445Z] output "web_subnet_id" {
[2023-10-06T06:08:41.448Z] value = azurerm_subnet.web_app_subnet.id
[2023-10-06T06:08:41.448Z] }
[2023-10-06T06:08:41.450Z] output "func_subnet_id" {
[2023-10-06T06:08:42.331Z] value = azurerm_subnet.function_app_subnet.id
[2023-10-06T06:08:42.331Z] }
[2023-10-06T06:08:42.331Z] ```
[2023-10-06T06:08:42.333Z] modules/app_service_plan/main.tf
[2023-10-06T06:08:42.334Z] ```
[2023-10-06T06:08:42.337Z] resource "azurerm_app_service_plan" "app_service_plan" {
[2023-10-06T06:08:43.065Z] name = var.app_service_plan_name
[2023-10-06T06:08:43.067Z] location = var.resource_group_location
[2023-10-06T06:08:43.079Z] resource_group_name = var.resource_group_name
[2023-10-06T06:08:43.080Z] sku {
[2023-10-06T06:08:43.974Z] tier = var.app_service_plan_sku
[2023-10-06T06:08:43.976Z] size = "S1"
[2023-10-06T06:08:43.976Z] }
[2023-10-06T06:08:43.977Z] }
[2023-10-06T06:08:43.978Z] output "app_service_plan_id" {
[2023-10-06T06:08:43.981Z] value = azurerm_app_service_plan.app_service_plan.id
[2023-10-06T06:08:43.982Z] }
[2023-10-06T06:08:43.982Z] ```
[2023-10-06T06:08:44.823Z] modules/app_service_plan/variables.tf
[2023-10-06T06:08:44.824Z] ```
[2023-10-06T06:08:44.826Z] variable "app_service_plan_name" {
[2023-10-06T06:08:44.828Z] description = "The name of the app service plan."
[2023-10-06T06:08:44.828Z] }
[2023-10-06T06:08:44.830Z] variable "app_service_plan_sku" {
[2023-10-06T06:08:45.626Z] description = "The SKU of the app service plan."
[2023-10-06T06:08:45.626Z] }
[2023-10-06T06:08:45.628Z] variable "resource_group_name" {
[2023-10-06T06:08:45.630Z] description = "The name of the resource group."
[2023-10-06T06:08:45.631Z] }
[2023-10-06T06:08:46.377Z] variable "resource_group_location" {
[2023-10-06T06:08:46.380Z] description = "The location of the resource group."
[2023-10-06T06:08:46.380Z] }
[2023-10-06T06:08:46.381Z] ```
[2023-10-06T06:08:46.382Z] modules/app_service_plan/outputs.tf
[2023-10-06T06:08:46.383Z] ```
[2023-10-06T06:08:46.385Z] output "app_service_plan_id" {
[2023-10-06T06:08:47.321Z] value = azurerm_app_service_plan.app_service_plan.id
[2023-10-06T06:08:47.321Z] }
[2023-10-06T06:08:47.322Z] ```
[2023-10-06T06:08:47.323Z] modules/web_app/main.tf
[2023-10-06T06:08:47.324Z] ```
[2023-10-06T06:08:47.328Z] resource "azurerm_app_service" "web_app" {
[2023-10-06T06:08:48.019Z] name = var.web_app_name
[2023-10-06T06:08:48.020Z] location = var.resource_group_location
[2023-10-06T06:08:48.022Z] resource_group_name = var.resource_group_name
[2023-10-06T06:08:48.964Z] app_service_plan_id = var.app_service_plan_id
[2023-10-06T06:08:48.966Z] site_config {
[2023-10-06T06:08:48.967Z] always_on = true
[2023-10-06T06:08:48.968Z] }
[2023-10-06T06:08:48.968Z] app_settings = {
[2023-10-06T06:08:48.971Z] "WEBSITE_HTTPLOGGING_RETENTION_DAYS" = "7"
[2023-10-06T06:08:50.085Z] "WEBSITE_NODE_DEFAULT_VERSION" = "10.14.1"
[2023-10-06T06:08:50.085Z] }
[2023-10-06T06:08:50.086Z] connection_string {
[2023-10-06T06:08:50.088Z] name = "AzureWebJobsStorage"
[2023-10-06T06:08:50.099Z] type = "Custom"
[2023-10-06T06:08:50.850Z] value = azurerm_storage_account.function_app_storage_account.primary_connection_string
[2023-10-06T06:08:50.851Z] }
[2023-10-06T06:08:50.851Z] identity {
[2023-10-06T06:08:50.853Z] type = "SystemAssigned"
[2023-10-06T06:08:50.853Z] }
[2023-10-06T06:08:50.854Z] depends_on = [
[2023-10-06T06:08:50.856Z] azurerm_subnet.web_app_subnet
[2023-10-06T06:08:50.857Z] ]
[2023-10-06T06:08:50.857Z] }
[2023-10-06T06:08:51.797Z] output "web_app_url" {
[2023-10-06T06:08:51.800Z] value = "https://${azurerm_app_service.web_app.default_site_hostname}"
[2023-10-06T06:08:51.801Z] }
[2023-10-06T06:08:51.801Z] ```
[2023-10-06T06:08:51.802Z] modules/web_app/variables.tf
[2023-10-06T06:08:51.803Z] ```
[2023-10-06T06:08:52.634Z] variable "web_app_name" {
[2023-10-06T06:08:52.636Z] description = "The name of the web app."
[2023-10-06T06:08:52.636Z] }
[2023-10-06T06:08:52.638Z] variable "app_service_plan_id" {
[2023-10-06T06:08:52.641Z] description = "The ID of the app service plan."
[2023-10-06T06:08:52.641Z] }
[2023-10-06T06:08:53.468Z] variable "web_subnet_id" {
[2023-10-06T06:08:53.470Z] description = "The ID of the web subnet."
[2023-10-06T06:08:53.471Z] }
[2023-10-06T06:08:53.472Z] variable "resource_group_name" {
[2023-10-06T06:08:53.475Z] description = "The name of the resource group."
[2023-10-06T06:08:53.475Z] }
[2023-10-06T06:08:54.409Z] variable "resource_group_location" {
[2023-10-06T06:08:54.411Z] description = "The location of the resource group."
[2023-10-06T06:08:54.411Z] }
[2023-10-06T06:08:54.412Z] ```
[2023-10-06T06:08:54.413Z] modules/web_app/outputs.tf
[2023-10-06T06:08:54.414Z] ```
[2023-10-06T06:08:54.415Z] output "web_app_url" {
[2023-10-06T06:08:55.261Z] value = "https://${azurerm_app_service.web_app.default_site_hostname}"
[2023-10-06T06:08:55.262Z] }
[2023-10-06T06:08:55.263Z] ```
[2023-10-06T06:08:55.264Z] modules/function_app/main.tf
[2023-10-06T06:08:55.264Z] ```
[2023-10-06T06:08:55.818Z] resource "azurerm_function_app" "function_app" {
[2023-10-06T06:08:55.820Z] name = var.function_app_name
[2023-10-06T06:08:55.822Z] location = var.function_app_location
[2023-10-06T06:08:56.693Z] resource_group_name = var.resource_group_name
[2023-10-06T06:08:56.697Z] app_service_plan_id = var.app_service_plan_id
[2023-10-06T06:08:56.699Z] storage_account_name = var.storage_account_name
[2023-10-06T06:08:57.367Z] storage_account_access_key = azurerm_storage_account.function_app_storage_account.primary_access_key
[2023-10-06T06:08:57.369Z] os_type = "linux"
[2023-10-06T06:08:57.371Z] version = "~3"
[2023-10-06T06:08:58.103Z] site_config {
[2023-10-06T06:08:58.113Z] linux_fx_version = "DOCKER|${var.docker_image}"
[2023-10-06T06:08:58.114Z] always_on = true
[2023-10-06T06:08:58.115Z] }
[2023-10-06T06:08:58.115Z] identity {
[2023-10-06T06:08:58.117Z] type = "SystemAssigned"
[2023-10-06T06:08:58.117Z] }
[2023-10-06T06:08:58.792Z] depends_on = [
[2023-10-06T06:08:58.794Z] azurerm_subnet.function_app_subnet
[2023-10-06T06:08:58.795Z] ]
[2023-10-06T06:08:58.795Z] }
[2023-10-06T06:08:58.797Z] output "function_app_url" {
[2023-10-06T06:08:59.712Z] value = "https://${azurerm_function_app.function_app.default_hostname}"
[2023-10-06T06:08:59.712Z] }
[2023-10-06T06:08:59.713Z] ```
[2023-10-06T06:08:59.714Z] modules/function_app/variables.tf
[2023-10-06T06:08:59.715Z] ```
[2023-10-06T06:08:59.716Z] variable "function_app_name" {
[2023-10-06T06:08:59.718Z] description = "The name of the function app."
[2023-10-06T06:08:59.719Z] }
[2023-10-06T06:09:00.348Z] variable "app_service_plan_id" {
[2023-10-06T06:09:00.351Z] description = "The ID of the app service plan."
[2023-10-06T06:09:00.351Z] }
[2023-10-06T06:09:00.353Z] variable "storage_account_name" {
[2023-10-06T06:09:00.355Z] description = "The name of the storage account."
[2023-10-06T06:09:01.951Z] }
[2023-10-06T06:09:01.954Z] variable "resource_group_name" {
[2023-10-06T06:09:01.956Z] description = "The name of the resource group."
[2023-10-06T06:09:01.956Z] }
[2023-10-06T06:09:01.957Z] variable "resource_group_location" {
[2023-10-06T06:09:02.914Z] description = "The location of the resource group."
[2023-10-06T06:09:02.914Z] }
[2023-10-06T06:09:02.916Z] variable "docker_image" {
[2023-10-06T06:09:02.919Z] description = "The Docker image to use for the function app."
[2023-10-06T06:09:02.919Z] }
[2023-10-06T06:09:03.837Z] variable "function_app_location" {
[2023-10-06T06:09:03.854Z] description = "The location of the function app."
[2023-10-06T06:09:03.854Z] }
[2023-10-06T06:09:03.855Z] ```
[2023-10-06T06:09:03.857Z] modules/function_app/outputs.tf
[2023-10-06T06:09:03.857Z] ```
[2023-10-06T06:09:03.858Z] output "function_app_url" {
[2023-10-06T06:09:04.514Z] value = "https://${azurerm_function_app.function_app.default_hostname}"
[2023-10-06T06:09:04.514Z] }
[2023-10-06T06:09:04.515Z] ```
[2023-10-06T06:09:04.516Z] modules/storage_account/main.tf
[2023-10-06T06:09:04.516Z] ```
[2023-10-06T06:09:05.035Z] resource "azurerm_storage_account" "function_app_storage_account" {
[2023-10-06T06:09:05.037Z] name = var.storage_account_name
[2023-10-06T06:09:05.039Z] location = var.storage_account_location
[2023-10-06T06:09:05.904Z] resource_group_name = var.resource_group_name
[2023-10-06T06:09:05.907Z] account_tier = var.storage_account_tier
[2023-10-06T06:09:05.909Z] account_replication_type = "LRS"
[2023-10-06T06:09:07.063Z] enable_https_traffic_only = true
[2023-10-06T06:09:07.064Z] tags = {
[2023-10-06T06:09:07.066Z] environment = "dev"
[2023-10-06T06:09:07.066Z] }
[2023-10-06T06:09:07.066Z] lifecycle {
[2023-10-06T06:09:07.068Z] prevent_destroy = true
[2023-10-06T06:09:07.068Z] }
[2023-10-06T06:09:07.069Z] }
[2023-10-06T06:09:07.070Z] output "storage_account_id" {
[2023-10-06T06:09:07.912Z] value = azurerm_storage_account.function_app_storage_account.id
[2023-10-06T06:09:07.912Z] }
[2023-10-06T06:09:07.913Z] ```
[2023-10-06T06:09:07.914Z] modules/storage_account/variables.tf
[2023-10-06T06:09:07.914Z] ```
[2023-10-06T06:09:07.916Z] variable "storage_account_name" {
[2023-10-06T06:09:08.984Z] description = "The name of the storage account."
[2023-10-06T06:09:08.984Z] }
[2023-10-06T06:09:08.986Z] variable "storage_account_location" {
[2023-10-06T06:09:08.989Z] description = "The location of the storage account."
[2023-10-06T06:09:08.989Z] }
[2023-10-06T06:09:08.990Z] variable "storage_account_tier" {
[2023-10-06T06:09:09.752Z] description = "The tier of the storage account."
[2023-10-06T06:09:09.752Z] }
[2023-10-06T06:09:09.753Z] variable "storage_account_kind" {
[2023-10-06T06:09:09.756Z] description = "The kind of the storage account."
[2023-10-06T06:09:09.756Z] }
[2023-10-06T06:09:10.897Z] variable "resource_group_name" {
[2023-10-06T06:09:10.899Z] description = "The name of the resource group."
[2023-10-06T06:09:10.899Z] }
[2023-10-06T06:09:10.900Z] ```
[2023-10-06T06:09:10.901Z] modules/storage_account/outputs.tf
[2023-10-06T06:09:10.902Z] ```
[2023-10-06T06:09:10.903Z] output "storage_account_id" {
[2023-10-06T06:09:11.318Z] value = azurerm_storage_account.function_app_storage_account.id
[2023-10-06T06:09:11.318Z] }
[2023-10-06T06:09:11.319Z] ```
## Current Behavior
Here if you see file names are written as modules/vnet/main.tf, but it is unable to create modules/vnet folder in the workspace and throwing error.
Executed 'Functions.GptEngineer-Start' (Failed, Id=d5249dcc-a6bd-4138-9315-b12325fc07d4, Duration=77008ms)
[2023-10-06T06:09:11.609Z] System.Private.CoreLib: Exception while executing function: Functions.GptEngineer-Start. System.Private.CoreLib: Result: Failure
[2023-10-06T06:09:11.610Z] Exception: FileNotFoundError: [Errno 2] No such file or directory: '/tmp/tmpa58ep6uq/modules/vnet/main.tf'
[2023-10-06T06:09:11.610Z] Stack: File "/usr/lib/azure-functions-core-tools-4/workers/python/3.9/LINUX/X64/azure_functions_worker/dispatcher.py", line 479, in _handle__invocation_request
[2023-10-06T06:09:11.610Z] call_result = await self._loop.run_in_executor(
[2023-10-06T06:09:11.610Z] File "/usr/local/lib/python3.9/concurrent/futures/thread.py", line 58, in run
[2023-10-06T06:09:11.610Z] result = self.fn(*self.args, **self.kwargs)
[2023-10-06T06:09:11.610Z] File "/usr/lib/azure-functions-core-tools-4/workers/python/3.9/LINUX/X64/azure_functions_worker/dispatcher.py", line 752, in _run_sync_func
[2023-10-06T06:09:11.610Z] return ExtensionManager.get_sync_invocation_wrapper(context,
[2023-10-06T06:09:11.610Z] File "/usr/lib/azure-functions-core-tools-4/workers/python/3.9/LINUX/X64/azure_functions_worker/extension.py", line 215, in _raw_invocation_wrapper
[2023-10-06T06:09:11.610Z] result = function(**args)
[2023-10-06T06:09:11.610Z] File "/workspaces/gpt-engineer-api/GptEngineer-Start/__init__.py", line 194, in main
[2023-10-06T06:09:11.610Z] zip_file_path = createZipFile(workspace=body["workspace"], prompt=body["input_prompt"]["prompt"], QnA = body["logs"]["clarify"])
[2023-10-06T06:09:11.610Z] File "/workspaces/gpt-engineer-api/GptEngineer-Start/__init__.py", line 69, in createZipFile
[2023-10-06T06:09:11.610Z] with open(file_path, 'w') as f:
| closed | 2023-10-09T07:44:46Z | 2023-10-12T14:09:14Z | https://github.com/AntonOsika/gpt-engineer/issues/776 | [
"bug",
"triage"
] | nagarrianharshit | 1 |
wandb/wandb | data-science | 9,168 | [Bug]: WorkspaceView API doesn't work as per documentation [I want to copy workspace view from one project to another] | ### Describe the bug
I encountered an issue while copying a workspace view from one project to another. Although the [WandB documentation](https://docs.wandb.ai/guides/track/workspaces) (at the end of the page) suggests that this should be possible, it seems to be outdated and no longer applies to the latest WandB.
Specifically, the Workspace class no longer accepts the `views` argument as mentioned in the docs.
From the docs:
```python
import wandb_workspaces.workspaces as ws
old_workspace = ws.Workspace.from_url("old-workspace-url")
old_workspace_view = old_workspace.views[0] # <--- workspace does not have attribute views
# and following Workspace class does not accept views as an argument
new_workspace = ws.Workspace(entity="new-entity", project="new-project", views=[old_workspace_view])
new_workspace.save()
```
Let me know if copying a workspace view between projects is still supported in the current version, or if there’s an alternative approach I should follow.
Wandb version: 0.19.1 | closed | 2025-01-02T18:12:17Z | 2025-01-03T23:33:29Z | https://github.com/wandb/wandb/issues/9168 | [
"ty:bug",
"a:app"
] | bikcrum | 3 |
pydantic/pydantic | pydantic | 11,270 | Generic type defaults (pep-696) throws an exception when used in type annotations. | ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
Doing my expirements with [PEP-696](https://peps.python.org/pep-0696/) i've discovered that my routes returning ApiResponse with added type default now throws pydantic error. And it does not work with old TypeVar with defaults too. I've decided to use latest `7506b1c9` commit with merged https://github.com/pydantic/pydantic/pull/11189, but it does not help.
Although, if i just use such class defining and using veriables it works ok, it fails only when you trying to define T expilictly like `a = ApiResult[str](data="str")` or `a: ApiResult[str] = ApiResult(data="str")`.
So i think generic type defaults does not currently supported? Will they be?
### Example Code
pre 3.13 example
```python
from typing import Generic, TypeVar
from pydantic import BaseModel
T = TypeVar("T")
E = TypeVar("E", default=None)
class ApiResult(BaseModel, Generic[T, E]):
data: T | None
error: E | None = None
def func(arg: ApiResult[str]):
print(arg)
```
post 3.13 example
```python
from pydantic import BaseModel
class ApiResult[T, E = None](BaseModel):
data: T | None
error: E | None = None
def func(arg: ApiResult[str]):
print(arg)
```
error traceback, same for both cases
```
Traceback (most recent call last):
File "C:\Users\George\PycharmProjects\backend\mre.py", line 20, in <module>
def func(arg: ApiResult[str]):
~~~~~~~~~^^^^^
File "C:\Users\George\PycharmProjects\backend\.venv\Lib\site-packages\pydantic\main.py", line 773, in __class_getitem__
_generics.check_parameters_count(cls, typevar_values)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\George\PycharmProjects\backend\.venv\Lib\site-packages\pydantic\_internal\_generics.py", line 401, in check_parameters_count
raise TypeError(f'Too {description} parameters for {cls}; actual {actual}, expected {expected}')
TypeError: Too few parameters for <class '__main__.ApiResult'>; actual 1, expected 2
```
### Python, Pydantic & OS Version
```Text
pydantic version: 2.10.5
pydantic-core version: 2.27.2
pydantic-core build: profile=release pgo=false
install path: C:\Users\George\PycharmProjects\backend\.venv\Lib\site-packages\pydantic
python version: 3.13.1 (main, Dec 6 2024, 18:07:41) [MSC v.1942 64 bit (AMD64)]
platform: Windows-11-10.0.26100-SP0
related packages: fastapi-0.115.6 mypy-1.11.2 pydantic-extra-types-2.10.1 pydantic-settings-2.7.1 pyright-1.1.391 typing_extensions-4.12.2
```
| closed | 2025-01-15T11:03:18Z | 2025-01-24T14:55:18Z | https://github.com/pydantic/pydantic/issues/11270 | [
"feature request"
] | chamoretto | 3 |
waditu/tushare | pandas | 1,564 | daily_basic里的market还是有深交所的中小板 | <img width="421" alt="WechatIMG1017" src="https://user-images.githubusercontent.com/26021194/123363650-8e616600-d5a5-11eb-9aec-43597261a8e7.png">
20210406开始深交所就合并主板和中小板了 | open | 2021-06-25T03:09:14Z | 2021-06-25T03:09:14Z | https://github.com/waditu/tushare/issues/1564 | [] | honghong2333 | 0 |
microsoft/nni | tensorflow | 5,672 | Wrong key 'op_names_re' | **Describe the bug**:
**Environment**:
- NNI version:
- Training service (local|remote|pai|aml|etc):
- Python version:
- PyTorch version:
- Cpu or cuda version:
**Reproduce the problem**
- Code|Example:
- How to reproduce: | open | 2023-08-28T03:00:01Z | 2023-08-28T03:00:01Z | https://github.com/microsoft/nni/issues/5672 | [] | zhang0557kui | 0 |
unit8co/darts | data-science | 2,378 | [BUG] darts should support re-training base on the old checkpoint, not reset the model | **Describe the bug**
I meet the following error:
if checkpoint_exists and save_checkpoints:
raise_if_not(
force_reset,
f"Some model data already exists for `model_name` '{self.model_name}'. Either load model to continue "
f"training or use `force_reset=True` to initialize anyway to start training from scratch and remove "
f"all the model data",
logger,
)
self.reset_model()
when I create model by using following setting to reload the old checkpoint and then re-train the model
save_checkpoints=True,
force_reset=False,
model_name=self.name,
work_dir=self._path,
I think we should support user load the old checkpoint automatically when create model and re-tain to generate the new checkpoint, ligthing support this behavior and it's ModelCheckpoint generate checkpoint with version number for example: my-checkpoint-v0,......my-checkpoint-v5 and so on.
Why we force to reset the model and lost all data from checkpoint.
| closed | 2024-05-08T02:58:58Z | 2024-05-08T13:22:10Z | https://github.com/unit8co/darts/issues/2378 | [
"question"
] | joshua-xia | 2 |
albumentations-team/albumentations | machine-learning | 2,340 | RandomFog behaves differently in version 2.0.4 compared to previous versions | ## Describe the bug
The result of RandomFog in version 1.4.6 is completely different from the newest version 2.0.4
### To Reproduce
Steps to reproduce the behavior:
1. Environment (e.g., OS, Python version, Albumentations version, etc.)
OS: MacOS Sonoma 14.2 (23C64)
Python: 3.10.16
Albumentations version: 1.4.6 and 2.0.4
2. Sample code that produces the bug.
```python
import albumentations as A
from PIL import Image
import numpy as np
# read image
img_path = 'path/to/image'
pil_image = Image.open(img_path).convert('RGB')
# apply data aug
# for version 1.4.6
_augs_fnc = A.RandomFog(alpha_coef=0.08, fog_coef_lower=0.6, fog_coef_upper=1.0, p=1.0)
# for version 2.0.4
# _augs_fnc = A.RandomFog(alpha_coef=0.08, fog_coef_range=(0.6, 1.0), p=1.0,)
img_np = np.array(pil_image)
augmented = _augs_fnc(image=img_np)
aug_image = Image.fromarray(augmented['image'])
```
3. Any error messages or incorrect outputs.
None
### Expected behavior
I expect both results should look the same or very similar
### Actual behavior
The two results are completely different and RandomFog in version 2.0.4 are not really foggy
### Screenshots
#### Load image
<img width="619" alt="Image" src="https://github.com/user-attachments/assets/4c8741b0-e6ae-4506-adf4-1ee3d78edf8f" />
#### Version 1.4.6
<img width="753" alt="Image" src="https://github.com/user-attachments/assets/1e93d006-c75a-4b2d-9858-9bf2e2d68360" />
#### Version 2.0.4
<img width="775" alt="Image" src="https://github.com/user-attachments/assets/599238a5-e385-409b-a6cc-4d4e28be3be6" /> | closed | 2025-02-13T03:39:28Z | 2025-02-26T21:20:56Z | https://github.com/albumentations-team/albumentations/issues/2340 | [
"bug"
] | huuquan1994 | 5 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 912 | I'm getting this error, how can solve this? | Error processing line 1 of C:\Users\NMS\Anaconda3\envs\rtvc\lib\site-packages\vision-1.0.0-py3.7-nspkg.pth:
Traceback (most recent call last):
File "C:\Users\NMS\Anaconda3\envs\rtvc\lib\site.py", line 168, in addpackage
exec(line)
File "<string>", line 1, in <module>
File "<frozen importlib._bootstrap>", line 580, in module_from_spec
AttributeError: 'NoneType' object has no attribute 'loader'
Remainder of file ignored | closed | 2021-11-28T07:40:01Z | 2021-12-28T12:33:21Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/912 | [] | mithisha | 0 |
s3rius/FastAPI-template | asyncio | 134 | generate template error: Stopping generation because post_gen_project hook script didn't exit successfully | # Image

# Error Info
`
E:\Code>fastapi_template
Project name: fastapi_template_test
Project description:
Removing resources for disabled feature GraphQL API...
Removing resources for disabled feature Kafka support...
Removing resources for disabled feature Kubernetes...
Removing resources for disabled feature Migrations...
Removing resources for disabled feature Gitlab CI...
Removing resources for disabled feature Dummy model...
Removing resources for disabled feature Self-hosted swagger...
Removing resources for disabled feature Tortoise ORM...
Removing resources for disabled feature Ormar ORM...
Removing resources for disabled feature PsycoPG...
Removing resources for disabled feature Piccolo...
Removing resources for disabled feature Postgresql DB...
Removing resources for disabled feature Opentelemetry support...
Removing resources for disabled feature SQLite DB...
cleanup complete!
⭐ Placing resources nicely in your new project ⭐
Resources are happy to be where they are needed the most.
Git repository initialized.
warning: in the working copy of 'fastapi_template_test/static/docs/redoc.standalone.js', LF will be replaced by CRLF the next time Git touches it
warning: in the working copy of 'fastapi_template_test/static/docs/swagger-ui-bundle.js', LF will be replaced by CRLF the next time Git touches it
warning: in the working copy of 'fastapi_template_test/static/docs/swagger-ui.css', LF will be replaced by CRLF the next time Git touches it
Added files to index.
Traceback (most recent call last):
File "C:\Users\pc\AppData\Local\Temp\tmpo5ko_okk.py", line 74, in <module>
init_repo()
File "C:\Users\pc\AppData\Local\Temp\tmpo5ko_okk.py", line 64, in init_repo
subprocess.run(["poetry", "install", "-n"])
File "C:\Python311\Lib\subprocess.py", line 546, in run
with Popen(*popenargs, **kwargs) as process:
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Python311\Lib\subprocess.py", line 1022, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "C:\Python311\Lib\subprocess.py", line 1491, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
Stopping generation because post_gen_project hook script didn't exit successfully
`
# Context Info
Python: 3.11.0 (main, Oct 24 2022, 18:26:48) [MSC v.1933 64 bit (AMD64)] on win32
Pip Package:
`C:\Users\pc>pip list
Package Version
------------------ ---------
arrow 1.2.3
binaryornot 0.4.4
certifi 2022.9.24
cfgv 3.3.1
chardet 5.0.0
charset-normalizer 2.1.1
click 8.1.3
colorama 0.4.6
cookiecutter 1.7.3
distlib 0.3.6
fastapi-template 3.3.10
filelock 3.8.0
identify 2.5.8
idna 3.4
Jinja2 3.1.2
jinja2-time 0.2.0
MarkupSafe 2.1.1
nodeenv 1.7.0
pip 22.3
platformdirs 2.5.3
poyo 0.5.0
pre-commit 2.20.0
prompt-toolkit 3.0.32
pydantic 1.10.2
python-dateutil 2.8.2
python-slugify 6.1.2
PyYAML 6.0
requests 2.28.1
setuptools 65.5.0
six 1.16.0
termcolor 1.1.0
text-unidecode 1.3
toml 0.10.2
typing_extensions 4.4.0
urllib3 1.26.12
virtualenv 20.16.6
wcwidth 0.2.5` | closed | 2022-11-12T20:05:38Z | 2022-11-13T08:59:40Z | https://github.com/s3rius/FastAPI-template/issues/134 | [] | liqiujiong | 3 |
sgl-project/sglang | pytorch | 4,145 | [Bug] Is YaRN supported in SGLang? How to enable it? | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [x] 2. The bug has not been fixed in the latest version.
- [x] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to reproduce and resolve the issue, reducing the likelihood of receiving feedback.
- [x] 4. If the issue you raised is not a bug but a question, please raise a discussion at https://github.com/sgl-project/sglang/discussions/new/choose Otherwise, it will be closed.
- [x] 5. Please use English, otherwise it will be closed.
### Describe the bug
I was deploying QwQ-32B model and notices in the [documentation](https://huggingface.co/Qwen/QwQ-32B#usage-guidelines) that adding the following content to the model's config.json could enable YaRN, allowing the model to handle longer context.
```
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
But then I encountered the following error in the SGLang log:
```
Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
```
I searched for whether SGLang supports YaRN and found the following two issues: #2943 and #2108 . However, neither of these issues provided any resolution to the problem.
Here is the complete log:
```
(sglang) user@server:~$ python -m sglang.launch_server --model-path /path/to/models/QwQ-32B --host 0.0.0.0 --port 6666 --served-model-name QwQ-32B --mem-fraction-static 0.7 --max-running-requests 20 --tp 2
/home/user/miniconda3/envs/sglang/lib/python3.12/site-packages/transformers/models/auto/image_processing_auto.py:590: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
warnings.warn(
INFO 03-06 23:31:17 __init__.py:190] Automatically detected platform cuda.
[2025-03-06 23:31:19] server_args=ServerArgs(model_path='/path/to/models/QwQ-32B', tokenizer_path='/path/to/models/QwQ-32B', tokenizer_mode='auto', load_format='auto', trust_remote_code=False, dtype='auto', kv_cache_dtype='auto', quantization_param_path=None, quantization=None, context_length=None, device='cuda', served_model_name='QwQ-32B', chat_template=None, is_embedding=False, revision=None, skip_tokenizer_init=False, host='0.0.0.0', port=6666, mem_fraction_static=0.7, max_running_requests=20, max_total_tokens=None, chunked_prefill_size=8192, max_prefill_tokens=16384, schedule_policy='lpm', schedule_conservativeness=1.0, cpu_offload_gb=0, prefill_only_one_req=False, tp_size=2, stream_interval=1, stream_output=False, random_seed=53889866, constrained_json_whitespace_pattern=None, watchdog_timeout=300, download_dir=None, base_gpu_id=0, log_level='info', log_level_http=None, log_requests=False, show_time_cost=False, enable_metrics=False, decode_log_interval=40, api_key=None, file_storage_pth='sglang_storage', enable_cache_report=False, dp_size=1, load_balance_method='round_robin', ep_size=1, dist_init_addr=None, nnodes=1, node_rank=0, json_model_override_args='{}', lora_paths=None, max_loras_per_batch=8, lora_backend='triton', attention_backend='flashinfer', sampling_backend='flashinfer', grammar_backend='outlines', speculative_draft_model_path=None, speculative_algorithm=None, speculative_num_steps=5, speculative_num_draft_tokens=64, speculative_eagle_topk=8, enable_double_sparsity=False, ds_channel_config_path=None, ds_heavy_channel_num=32, ds_heavy_token_num=256, ds_heavy_channel_type='qk', ds_sparse_decode_threshold=4096, disable_radix_cache=False, disable_jump_forward=False, disable_cuda_graph=False, disable_cuda_graph_padding=False, enable_nccl_nvls=False, disable_outlines_disk_cache=False, disable_custom_all_reduce=False, disable_mla=False, disable_overlap_schedule=False, enable_mixed_chunk=False, enable_dp_attention=False, enable_ep_moe=False, enable_torch_compile=False, torch_compile_max_bs=32, cuda_graph_max_bs=160, cuda_graph_bs=None, torchao_config='', enable_nan_detection=False, enable_p2p_check=False, triton_attention_reduce_in_fp32=False, triton_attention_num_kv_splits=8, num_continuous_decode_steps=1, delete_ckpt_after_loading=False, enable_memory_saver=False, allow_auto_truncate=False, return_hidden_states=False, enable_custom_logit_processor=False, tool_call_parser=None, enable_hierarchical_cache=False, enable_flashinfer_mla=False)
Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
/home/user/miniconda3/envs/sglang/lib/python3.12/site-packages/transformers/models/auto/image_processing_auto.py:590: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
warnings.warn(
/home/user/miniconda3/envs/sglang/lib/python3.12/site-packages/transformers/models/auto/image_processing_auto.py:590: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
warnings.warn(
/home/user/miniconda3/envs/sglang/lib/python3.12/site-packages/transformers/models/auto/image_processing_auto.py:590: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
warnings.warn(
INFO 03-06 23:31:22 __init__.py:190] Automatically detected platform cuda.
INFO 03-06 23:31:22 __init__.py:190] Automatically detected platform cuda.
INFO 03-06 23:31:22 __init__.py:190] Automatically detected platform cuda.
Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
[2025-03-06 23:31:24 TP0] Init torch distributed begin.
Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
[2025-03-06 23:31:24 TP1] Init torch distributed begin.
[2025-03-06 23:31:24 TP0] sglang is using nccl==2.21.5
[2025-03-06 23:31:24 TP1] sglang is using nccl==2.21.5
[2025-03-06 23:31:24 TP1] Load weight begin. avail mem=46.93 GB
[2025-03-06 23:31:24 TP0] Load weight begin. avail mem=46.93 GB
Loading safetensors checkpoint shards: 0% Completed | 0/14 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 7% Completed | 1/14 [00:00<00:09, 1.44it/s]
Loading safetensors checkpoint shards: 14% Completed | 2/14 [00:01<00:08, 1.37it/s]
Loading safetensors checkpoint shards: 21% Completed | 3/14 [00:02<00:08, 1.35it/s]
Loading safetensors checkpoint shards: 29% Completed | 4/14 [00:02<00:07, 1.35it/s]
Loading safetensors checkpoint shards: 36% Completed | 5/14 [00:03<00:06, 1.35it/s]
Loading safetensors checkpoint shards: 43% Completed | 6/14 [00:04<00:05, 1.34it/s]
Loading safetensors checkpoint shards: 50% Completed | 7/14 [00:05<00:05, 1.34it/s]
Loading safetensors checkpoint shards: 57% Completed | 8/14 [00:05<00:04, 1.44it/s]
Loading safetensors checkpoint shards: 64% Completed | 9/14 [00:06<00:03, 1.41it/s]
Loading safetensors checkpoint shards: 71% Completed | 10/14 [00:07<00:02, 1.39it/s]
Loading safetensors checkpoint shards: 79% Completed | 11/14 [00:07<00:02, 1.37it/s]
Loading safetensors checkpoint shards: 86% Completed | 12/14 [00:08<00:01, 1.36it/s]
Loading safetensors checkpoint shards: 93% Completed | 13/14 [00:09<00:00, 1.68it/s]
Loading safetensors checkpoint shards: 100% Completed | 14/14 [00:09<00:00, 1.60it/s]
Loading safetensors checkpoint shards: 100% Completed | 14/14 [00:09<00:00, 1.44it/s]
[2025-03-06 23:31:34 TP1] Load weight end. type=Qwen2ForCausalLM, dtype=torch.bfloat16, avail mem=16.14 GB
[2025-03-06 23:31:34 TP0] Load weight end. type=Qwen2ForCausalLM, dtype=torch.bfloat16, avail mem=16.14 GB
[2025-03-06 23:31:34 TP0] KV Cache is allocated. K size: 1.02 GB, V size: 1.02 GB.
[2025-03-06 23:31:34 TP0] Memory pool end. avail mem=13.89 GB
[2025-03-06 23:31:34 TP1] KV Cache is allocated. K size: 1.02 GB, V size: 1.02 GB.
[2025-03-06 23:31:34 TP1] Memory pool end. avail mem=13.89 GB
[2025-03-06 23:31:34 TP0] Capture cuda graph begin. This can take up to several minutes.
[2025-03-06 23:31:34 TP1] Capture cuda graph begin. This can take up to several minutes.
100%|██████████████████████████████████████| 7/7 [00:03<00:00, 1.76it/s]
[2025-03-06 23:31:38 TP1] Registering 903 cuda graph addresses
[2025-03-06 23:31:38 TP0] Registering 903 cuda graph addresses
[2025-03-06 23:31:38 TP1] Capture cuda graph end. Time elapsed: 4.00 s
[2025-03-06 23:31:38 TP0] Capture cuda graph end. Time elapsed: 4.00 s
[2025-03-06 23:31:39 TP0] max_total_num_tokens=16666, chunked_prefill_size=8192, max_prefill_tokens=16384, max_running_requests=20, context_len=131072
[2025-03-06 23:31:39 TP1] max_total_num_tokens=16666, chunked_prefill_size=8192, max_prefill_tokens=16384, max_running_requests=20, context_len=131072
[2025-03-06 23:31:39] INFO: Started server process [749936]
[2025-03-06 23:31:39] INFO: Waiting for application startup.
[2025-03-06 23:31:39] INFO: Application startup complete.
[2025-03-06 23:31:39] INFO: Uvicorn running on http://0.0.0.0:6666 (Press CTRL+C to quit)
[2025-03-06 23:31:40] INFO: 127.0.0.1:53956 - "GET /get_model_info HTTP/1.1" 200 OK
[2025-03-06 23:31:40 TP0] Prefill batch. #new-seq: 1, #new-token: 6, #cached-token: 0, cache hit rate: 0.00%, token usage: 0.00, #running-req: 0, #queue-req: 0
[2025-03-06 23:31:42] INFO: 127.0.0.1:53968 - "POST /generate HTTP/1.1" 200 OK
[2025-03-06 23:31:42] The server is fired up and ready to roll!
```
### Reproduction
Add
```
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
```
to the config.json of a model, launch a SGLang Server with it.
### Environment
```
INFO 03-06 22:02:35 __init__.py:190] Automatically detected platform cuda.
Python: 3.12.9 | packaged by Anaconda, Inc. | (main, Feb 6 2025, 18:56:27) [GCC 11.2.0]
CUDA available: True
GPU 0,1: NVIDIA RTX A6000
GPU 0,1 Compute Capability: 8.6
CUDA_HOME: /usr/local/cuda-12.4
NVCC: Cuda compilation tools, release 12.4, V12.4.131
CUDA Driver Version: 550.144.03
PyTorch: 2.5.1+cu124
sglang: 0.4.3.post2
sgl_kernel: 0.0.3.post6
flashinfer: 0.2.1.post2+cu124torch2.5
triton: 3.1.0
transformers: 4.48.3
torchao: 0.8.0
numpy: 1.26.4
aiohttp: 3.11.12
fastapi: 0.115.8
hf_transfer: 0.1.9
huggingface_hub: 0.29.1
interegular: 0.3.3
modelscope: 1.23.1
orjson: 3.10.15
packaging: 24.2
psutil: 7.0.0
pydantic: 2.10.6
multipart: 0.0.20
zmq: 26.2.1
uvicorn: 0.34.0
uvloop: 0.21.0
vllm: 0.7.2
openai: 1.64.0
tiktoken: 0.9.0
anthropic: 0.46.0
decord: 0.6.0
NVIDIA Topology:
GPU0 GPU1 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NV4 0-191 0 N/A
GPU1 NV4 X 0-191 0 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
ulimit soft: 1024
``` | open | 2025-03-06T15:49:17Z | 2025-03-21T08:41:24Z | https://github.com/sgl-project/sglang/issues/4145 | [] | boqianzee | 7 |
roboflow/supervision | tensorflow | 1,728 | LineZone does not match the actual situation | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
Hello, I am using LineZone and testing "vehicles. mp4". The document shows "line_zone. in_comunt", Line_zone. out_comunt is 7, 2, but I used the same code to display 3 and 4. May I ask if my usage is incorrect? thank you

### Additional
_No response_ | open | 2024-12-11T02:28:44Z | 2024-12-11T02:28:44Z | https://github.com/roboflow/supervision/issues/1728 | [
"question"
] | DreamerYinYu | 0 |
peerchemist/finta | pandas | 70 | STC returns wrong values | The STC indicator should returns nan, -inf, and values -/+ x thousands every time I use it.
The STC indicator should return values between 0 and 100.
I feed the function with dataframe from Binance which is compatible with the ohlc format you required.
` time open high low close volume date
0 1.593015e+12 42.41 42.54 42.41 42.54 404.91309 2020-06-24 16:02:00
1 1.593015e+12 42.54 42.56 42.48 42.54 891.49911 2020-06-24 16:03:00
2 1.593015e+12 42.55 42.57 42.50 42.53 273.67014 2020-06-24 16:04:00
3 1.593015e+12 42.53 42.56 42.51 42.55 1502.95409 2020-06-24 16:05:00
4 1.593015e+12 42.54 42.54 42.35 42.37 7764.08264 2020-06-24 16:06:00
.. ... ... ... ... ... ... ...
`
Thanks for your work and your time. | closed | 2020-06-25T08:47:16Z | 2020-06-25T17:25:29Z | https://github.com/peerchemist/finta/issues/70 | [] | DrLuthor | 1 |
streamlit/streamlit | deep-learning | 10,531 | Containers with background color | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Add a way for containers to have a background color.
### Why?
Some use cases that come to mind:
- Creating a dashboard look with white cards on top of a gray background.
- Callouts with more colors than what `st.warning`/`st.info`/`st.success`/`st.error` offer.
- Highlighting a section of the app.
### How?
One complication is that we need to make charts have the same background color as the container. Currently, they are simply getting set to the background color defined in the theme.
### Additional Context
_No response_ | open | 2025-02-26T22:30:22Z | 2025-03-19T23:32:50Z | https://github.com/streamlit/streamlit/issues/10531 | [
"type:enhancement",
"feature:st.container"
] | jrieke | 4 |
Lightning-AI/pytorch-lightning | pytorch | 20,187 | OnExceptionCheckpoint callback suppresses exceptions and results in NCCL timeout | ### Bug description
When running Lightning with a multi-device training strategy (e.g. with DDP), using the `OnExceptionCheckpoint` callback:
- silently swallows exceptions, which makes it challenging to identify the cause of errors
- results in a NCCL timeout
This is due to the following:
- When we catch an exception, it gets handled by `_call_and_handle_interrupt`, which calls into `_interrupt`: https://github.com/Lightning-AI/pytorch-lightning/blob/1551a16b94f5234a4a78801098f64d0732ef5cb5/src/lightning/pytorch/trainer/call.py#L67
- We are supposed to re-raise the original exception at the end of this function, but we never get there because...
- In `_interrupt`, we call `_call_callback_hooks`, which calls the `on_exception` callbacks: https://github.com/Lightning-AI/pytorch-lightning/blob/1551a16b94f5234a4a78801098f64d0732ef5cb5/src/lightning/pytorch/trainer/call.py#L76
- If the `OnExceptionCheckpoint` is enabled, we then call that callback. However, we never finish executing this callback, because in that callback, we call `trainer.save_checkpoint`: https://github.com/Lightning-AI/pytorch-lightning/blob/master/src/lightning/pytorch/callbacks/on_exception_checkpoint.py#L67
- The `trainer.save_checkpoint` method saves the checkpoint, and then calls `self.strategy.barrier("Trainer.save_checkpoint")`, which waits for the other processes to get reach that barrier. However, if those processes haven't had an exception, they will never hit this codepath, which means we never advance beyond that barrier (until it times out).
As described in the docstring for `Trainer.save_checkpoint`:
> This method needs to be called on all processes in case the selected strategy is handling distributed checkpointing.
In practice, this means that our jobs eventually time out with a NCCL error, and don't print the original exception.
### What version are you seeing the problem on?
v2.4
### How to reproduce the bug
_No response_
### Error messages and logs
```
# Error messages and logs here please
```
### Environment
<details>
<summary>Current environment</summary>
```
#- PyTorch Lightning Version (e.g., 2.4.0):
#- PyTorch Version (e.g., 2.4):
#- Python version (e.g., 3.12):
#- OS (e.g., Linux):
#- CUDA/cuDNN version:
#- GPU models and configuration:
#- How you installed Lightning(`conda`, `pip`, source):
```
</details>
### More info
_No response_ | open | 2024-08-10T05:43:50Z | 2024-08-10T05:46:11Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20187 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | jackdent | 0 |
NullArray/AutoSploit | automation | 714 | Divided by zero exception34 | Error: Attempted to divide by zero.34 | closed | 2019-04-19T15:59:31Z | 2019-04-19T16:38:37Z | https://github.com/NullArray/AutoSploit/issues/714 | [] | AutosploitReporter | 0 |
voila-dashboards/voila | jupyter | 893 | Voila Extension mode w/ a passworded Notebook | Hey There.
I've read the docs and didn't find anything related to authentication support. Below is a small explanation of my current issue:
Our Jupyter notebook is working just fine (tokenless), and we're using Voila in extension mode. Now, the moment we set a password to our notebook, Voila gives 404 errors and we cannot load it.
Does this mean Voila won't work at all if we're running a passworded Notebook? Even when we added a token, Voila wouldn't work.
Thanks and looking forward to any suggestions!
I've also checked this out, so might be related to it (https://github.com/voila-dashboards/voila/issues/642) | open | 2021-05-21T14:27:38Z | 2021-05-21T14:28:11Z | https://github.com/voila-dashboards/voila/issues/893 | [] | Vel-San | 0 |
mwaskom/seaborn | matplotlib | 2,894 | Rethink approach to grouping in plot phase of Plot | Currently we can declare that a `Mark` property should form groups at the property level. The reason we need to do this is that different marks behave differently: e.g. each line has the same values for all its properties and is added separately, while a scatterplot can mix multiple property values in a single artist. But I don't think we have or will encounter cases where only a subset of a marks properties should group, so it is cumbersome to have to set `grouping=` for every property.
Instead, I think this can be determined within `Mark._plot` by adding a parameter to the `split_gen` generator, where the mark passes in the properties that should be grouping.
This also touches on a broader issue which is that the current grouping is relatively inefficient (e.g. see #2881). Ideally, we would do scaling over all data points and then group, which can be faster. The challenge has been that we no longer have a dataframe after scaling. The main reason is that working with colors as rgba tuples / n x 4 arrays is difficult in the context of a dataframe ... you can stick the tuples in a series, but then it has an object dtype that propagates through to the numpy array and works poorly with matplotlib. A few options would be:
- Implement our own groupby logic on the dict of arrays / lists that we have after scaling
- Store rgba values as separate columns in the dataframe we build while scaling (we could perhaps use a differnet internal color representation to facilitate things like `luminance` properties)
- Implement some kind of RGBA extension array that lets a Series hold a 2d data structure (is this possible? I am not sure) | open | 2022-07-11T00:34:44Z | 2022-07-11T00:34:44Z | https://github.com/mwaskom/seaborn/issues/2894 | [
"internals",
"objects-plot"
] | mwaskom | 0 |
jupyter/nbgrader | jupyter | 1,251 | Remove all python 2 compatibility code | This should be done after #1082.
For example, remove all imports of six, or any other edge cases where python 2 is handled differently from python 3. | closed | 2019-11-02T10:39:39Z | 2019-11-02T15:24:02Z | https://github.com/jupyter/nbgrader/issues/1251 | [
"enhancement",
"good first issue"
] | jhamrick | 1 |
davidteather/TikTok-Api | api | 410 | [BUG] - KeyError: 'itemList' | Hello,
I am using the pyppeteer fork.
when I run the following code:
```
api = TikTokApi(custom_verifyFp=s_v_web_id)
tmp = api.byHashtag('test', count=100, language='en')
tmp
```
I get the following error:
```
KeyError Traceback (most recent call last)
<ipython-input-7-69361eefed4d> in <module>
1 api = TikTokApi(custom_verifyFp=s_v_web_id)
----> 2 tmp = api.byHashtag('test', count=100, language='en')
3 tmp
c:\miniconda3\envs\botenv\lib\site-packages\TikTokApi\tiktok.py in byHashtag(self, hashtag, count, offset, **kwargs)
735 res = self.getData(b, **kwargs)
736
--> 737 for t in res["itemList"]:
738 response.append(t)
739
KeyError: 'itemList'
```
| closed | 2020-12-05T08:39:43Z | 2020-12-24T15:30:37Z | https://github.com/davidteather/TikTok-Api/issues/410 | [
"bug"
] | pibvbp | 3 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 386 | Is it possible to use classic mapping? | SqlAlchemy allows the user to use classic mapping - http://docs.sqlalchemy.org/en/rel_1_0/orm/mapping_styles.html#classical-mappings
But how can I use classic mapping when using flask-sqlalchemy?
| closed | 2016-03-28T02:44:56Z | 2020-12-05T21:31:04Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/386 | [] | johnnncodes | 1 |
ydataai/ydata-profiling | data-science | 1,313 | index -9223372036854775808 is out of bounds for axis 0 with size 2 | ### Current Behaviour
IndexError Traceback (most recent call last)
<ipython-input-34-c0d0834d8e2d> in <module>
----> 1 profile_report.get_description()
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/typeguard/__init__.py in wrapper(*args, **kwargs)
1031 memo = _CallMemo(python_func, _localns, args=args, kwargs=kwargs)
1032 check_argument_types(memo)
-> 1033 retval = func(*args, **kwargs)
1034 try:
1035 check_return_type(retval, memo)
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/profile_report.py in get_description(self)
315 Dict containing a description for each variable in the DataFrame.
316 """
--> 317 return self.description_set
318
319 def get_rejected_variables(self) -> set:
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/typeguard/__init__.py in wrapper(*args, **kwargs)
1031 memo = _CallMemo(python_func, _localns, args=args, kwargs=kwargs)
1032 check_argument_types(memo)
-> 1033 retval = func(*args, **kwargs)
1034 try:
1035 check_return_type(retval, memo)
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/profile_report.py in description_set(self)
251 self.summarizer,
252 self.typeset,
--> 253 self._sample,
254 )
255 return self._description_set
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/describe.py in describe(config, df, summarizer, typeset, sample)
70 pbar.total += len(df.columns)
71 series_description = get_series_descriptions(
---> 72 config, df, summarizer, typeset, pbar
73 )
74
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/multimethod/__init__.py in __call__(self, *args, **kwargs)
313 func = self[tuple(func(arg) for func, arg in zip(self.type_checkers, args))]
314 try:
--> 315 return func(*args, **kwargs)
316 except TypeError as ex:
317 raise DispatchError(f"Function {func.__code__}") from ex
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/pandas/summary_pandas.py in pandas_get_series_descriptions(config, df, summarizer, typeset, pbar)
98 with multiprocessing.pool.ThreadPool(pool_size) as executor:
99 for i, (column, description) in enumerate(
--> 100 executor.imap_unordered(multiprocess_1d, args)
101 ):
102 pbar.set_postfix_str(f"Describe variable:{column}")
~/anaconda3/envs/py3.7/lib/python3.7/multiprocessing/pool.py in next(self, timeout)
746 if success:
747 return value
--> 748 raise value
749
750 __next__ = next # XXX
~/anaconda3/envs/py3.7/lib/python3.7/multiprocessing/pool.py in worker(inqueue, outqueue, initializer, initargs, maxtasks, wrap_exception)
119 job, i, func, args, kwds = task
120 try:
--> 121 result = (True, func(*args, **kwds))
122 except Exception as e:
123 if wrap_exception and func is not _helper_reraises_exception:
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/pandas/summary_pandas.py in multiprocess_1d(args)
77 """
78 column, series = args
---> 79 return column, describe_1d(config, series, summarizer, typeset)
80
81 pool_size = config.pool_size
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/multimethod/__init__.py in __call__(self, *args, **kwargs)
313 func = self[tuple(func(arg) for func, arg in zip(self.type_checkers, args))]
314 try:
--> 315 return func(*args, **kwargs)
316 except TypeError as ex:
317 raise DispatchError(f"Function {func.__code__}") from ex
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/pandas/summary_pandas.py in pandas_describe_1d(config, series, summarizer, typeset)
55
56 typeset.type_schema[series.name] = vtype
---> 57 return summarizer.summarize(config, series, dtype=vtype)
58
59
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/summarizer.py in summarize(self, config, series, dtype)
37 object:
38 """
---> 39 _, _, summary = self.handle(str(dtype), config, series, {"type": str(dtype)})
40 return summary
41
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/handler.py in handle(self, dtype, *args, **kwargs)
60 funcs = self.mapping.get(dtype, [])
61 op = compose(funcs)
---> 62 return op(*args)
63
64
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/handler.py in func2(*x)
19 return f(*x)
20 else:
---> 21 return f(*res)
22
23 return func2
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/handler.py in func2(*x)
19 return f(*x)
20 else:
---> 21 return f(*res)
22
23 return func2
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/handler.py in func2(*x)
19 return f(*x)
20 else:
---> 21 return f(*res)
22
23 return func2
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/handler.py in func2(*x)
15 def func(f: Callable, g: Callable) -> Callable:
16 def func2(*x) -> Any:
---> 17 res = g(*x)
18 if type(res) == bool:
19 return f(*x)
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/multimethod/__init__.py in __call__(self, *args, **kwargs)
313 func = self[tuple(func(arg) for func, arg in zip(self.type_checkers, args))]
314 try:
--> 315 return func(*args, **kwargs)
316 except TypeError as ex:
317 raise DispatchError(f"Function {func.__code__}") from ex
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/summary_algorithms.py in inner(config, series, summary)
63 if not summary["hashable"]:
64 return config, series, summary
---> 65 return fn(config, series, summary)
66
67 return inner
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/summary_algorithms.py in inner(config, series, summary)
80 series = series.dropna()
81
---> 82 return fn(config, series, summary)
83
84 return inner
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/pandas/describe_numeric_pandas.py in pandas_describe_numeric_1d(config, series, summary)
118
119 if chi_squared_threshold > 0.0:
--> 120 stats["chi_squared"] = chi_square(finite_values)
121
122 stats["range"] = stats["max"] - stats["min"]
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/ydata_profiling/model/summary_algorithms.py in chi_square(values, histogram)
50 ) -> dict:
51 if histogram is None:
---> 52 histogram, _ = np.histogram(values, bins="auto")
53 return dict(chisquare(histogram)._asdict())
54
<__array_function__ internals> in histogram(*args, **kwargs)
~/anaconda3/envs/py3.7/lib/python3.7/site-packages/numpy/lib/histograms.py in histogram(a, bins, range, normed, weights, density)
854 # The index computation is not guaranteed to give exactly
855 # consistent results within ~1 ULP of the bin edges.
--> 856 decrement = tmp_a < bin_edges[indices]
857 indices[decrement] -= 1
858 # The last bin includes the right edge. The other bins do not.
IndexError: index -9223372036854775808 is out of bounds for axis 0 with size 2
### Expected Behaviour
return data profiling for this table
### Data Description
SUM_TIMER_READ_WRITE
0 10950043000000000
### Code that reproduces the bug
```Python
import pandas as pd
from ydata_profiling import ProfileReport
b = {'SUM_TIMER_READ_WRITE': [10950043000000000]}
table = pd.DataFrame.from_dict(b)
profile_report = ProfileReport(
table,
progress_bar=False,
infer_dtypes=False,
missing_diagrams=None,
correlations=None,
interactions=None,
# duplicates=None,
samples=None)
description = profile_report.get_description()
```
### pandas-profiling version
v4.1.1
### Dependencies
```Text
pandas==1.3.5
ydata-profiling==4.1.1
```
### OS
Linux dsp-X299-WU8 5.15.0-69-generic #76~20.04.1-Ubuntu SMP Mon Mar 20 15:54:19 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
### Checklist
- [X] There is not yet another bug report for this issue in the [issue tracker](https://github.com/ydataai/pandas-profiling/issues)
- [X] The problem is reproducible from this bug report. [This guide](http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports) can help to craft a minimal bug report.
- [X] The issue has not been resolved by the entries listed under [Common Issues](https://pandas-profiling.ydata.ai/docs/master/pages/support_contrib/common_issues.html). | open | 2023-04-18T02:46:42Z | 2023-05-08T17:00:33Z | https://github.com/ydataai/ydata-profiling/issues/1313 | [
"question/discussion ❓"
] | zhoujianch | 1 |
snarfed/granary | rest-api | 482 | standardize on `to/from_as1` function names | There's currently a range of names for each module's functions that convert to/from AS1. Most are either `*_to_activities`/`activities_to_*` or `to/from_as1`, but there are others too. It'd be nice to standardize on `to/from_as1`. The trick is that most modules have specific functions for specific types, eg users vs posts vs feeds, so we need more than just those two names.
* [x] `as2`
* [x] `atom`
* [x] `bluesky`
* [x] `facebook`
* [x] `flickr`
* [x] `github`
* [x] `instagram`
* [x] `jsonfeed`
* [x] `mastodon`
* [x] `meetup`
* [x] `microformats2`
* [x] `nostr`
* [x] `pixelfed`
* [x] `reddit`
* [x] `rss`
* [x] `twitter` | closed | 2023-01-30T23:52:04Z | 2024-11-06T00:27:44Z | https://github.com/snarfed/granary/issues/482 | [
"now"
] | snarfed | 1 |
yzhao062/pyod | data-science | 170 | Cross-Validation for Anomaly Detection | How is the best way to perform it? How this could be implemented in PyOD? | open | 2020-03-15T23:20:09Z | 2020-03-15T23:20:09Z | https://github.com/yzhao062/pyod/issues/170 | [] | inaciomdrs | 0 |
mirumee/ariadne | graphql | 374 | Proposal: ariadne-relay | @rafalp and @patrys, I dropped a comment on #188 a couple of weeks ago, but I think it might have gone under the radar since that issue is closed, so I'm going to make a more formal proposal here.
I've already built a quick-and-dirty implementation for **Relay** connections, based on a decorator that wraps an ObjectType resolver that emits a Sequence. The implementation resolves the connection using [graphql-relay-py](https://github.com/graphql-python/graphql-relay-py). It works well, but its too specific to my case to be offered as a generalized implementation.
I agree with the assessment in #188 that the right path forward here is for there to be an independent **ariadne-relay** package. It seems reasonable to build it on top of **graphql-relay-py** so it is synchronised closely to the [reference Relay codebase](https://github.com/graphql/graphql-relay-js). I'm willing to take ownership of this project, but I want to introduce the approach I have in mind here for comment, prior to doing further work.
Proposed implementation:
* ~~**ariadne-relay** will provide a `ConnectionType` class, as a subclass of `ariadne.ObjectType`, which takes care of the boilerplate glue between an iterable/sliceable object returned by another resolver and **graphql-relay-py**. This class will have a `set_count_resolver()` method and a `count_resolver` decorator to allow for control over how the count is derived.~~
* **ariadne-relay** will provide a `NodeType` class, as a subclass of `Ariadne.InterfaceType`, which will help with the formation of `ID` values, leveraging the methods in **graphql-relay-py**. This class will have a `set_id_value_resolver()` method and a `id_value_resolver` decorator to allow for control over how ids are derived.
* I haven't worked yet with `graphql_relay.mutation` so I'm not sure how that might be leveraged, but at a glance it seems like it should be possible to do something useful here.
* **ariadne-relay** will adhere to Ariadne's dev and coding standards, so it stays a close cousin.
Does this seems like a reasonable basic direction? It seems from #188 that you guys have put a bit of consideration into this already, so perhaps you have some insight that I'm missing? | closed | 2020-05-31T18:46:47Z | 2021-03-19T12:19:03Z | https://github.com/mirumee/ariadne/issues/374 | [
"discussion"
] | markedwards | 4 |
vi3k6i5/flashtext | nlp | 140 | pip install flashtext not using master branch | I'm pulling flashtext using `pip install flashtext` and calling `extract_keywords` function
However, it return error when I passed 4 parameter into this function, and found that the code pulled only accept 3 parameter which different from the master branch.
Is there any plans for pushing the build to replace the existing build? | open | 2023-06-15T07:09:26Z | 2023-06-15T07:09:26Z | https://github.com/vi3k6i5/flashtext/issues/140 | [] | chanandrew96 | 0 |
neuml/txtai | nlp | 270 | ImportError: Language detection is not available - install "pipeline" extra to enable | I'm using Google Colab and the exact tutorial from this github.
```
!pip install txtai[pipeline]
from txtai.pipeline import Translation
translate = Translation()
translation = translate("This is a test translation into Spanish", "es")
translation
```
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
[<ipython-input-63-2f6e604dabe6>](https://localhost:8080/#) in <module>()
1 # Create translation model
2 translate = Translation()
----> 3 translation = translate("This is a test translation into Spanish", "es")
4 translation
1 frames
[/usr/local/lib/python3.7/dist-packages/txtai/pipeline/text/translation.py](https://localhost:8080/#) in detect(self, texts)
115
116 if not FASTTEXT:
--> 117 raise ImportError('Language detection is not available - install "pipeline" extra to enable')
118
119 if not self.detector:
ImportError: Language detection is not available - install "pipeline" extra to enable
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
--------------------------------------------------------------------------- | closed | 2022-04-22T06:55:51Z | 2022-05-16T15:30:37Z | https://github.com/neuml/txtai/issues/270 | [] | nleesalesloft | 1 |
localstack/localstack | python | 11,943 | bug: ExceptionType is not acted upon/bubbling up to Catch/Retry definition | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
When throwing a custom exception (python 3.12), SFN allows you to catch them by name for flow redirection.
Error being thrown:
`
{
--
2 | | "resourceType": "lambda",
3 | | "resource": "invoke",
4 | | "error": "Exception",
5 | | "cause": {
6 | | "errorMessage": "Test",
7 | | "errorType": "MoveableException",
8 | | "requestId": "ad733d94-fda4-46ff-9e41-6091e79d7de5",
9 | | "stackTrace": [
10 | | " File \"/var/lang/lib/python3.12/site-packages/aws_lambda_powertools/logging/logger.py\", line 447, in decorate\n return lambda_handler(event, context, *args, **kwargs)\n",
11 | | " File \"/var/task/fetch_job.py\", line 25, in lambda_handler\n status_code, data = processor.fetch(job_data=data, config=config)\n",
12 | | " File \"/var/task/processors/base_class.py\", line 23, in wrapper\n return method(*args, **kwargs)\n",
13 | | " File \"/var/task/processors/base_class.py\", line 23, in wrapper\n return method(*args, **kwargs)\n",
14 | | " File \"/var/task/processors/job_processor.py\", line 168, in fetch\n raise MoveableException(\"Test\")\n"
15 | | ]
16 | | }
17 | | }
`
Relevant definition:
`
"Catch": [
{
"ErrorEquals": [
"MoveableException"
],
"Next": "MoveJob",
"ResultPath": "$.fetch_job.output"
},
{
"ErrorEquals": [
"Exception"
],
"Next": "NotifyFailure",
"ResultPath": "$.failure.output"
},
`
Actual flow:

**This flow is validated on live AWS environments.**
### Expected Behavior
When a known custom exception is thrown and defined in the SFN definition block, it should act accordingly.
### How are you starting LocalStack?
With a docker-compose file
### Steps To Reproduce
Define a step function definition with simple catch/retry on a custom exception on a lambda invocation with a catch block mirroring the provided above.
Lambda:
`
import requests
import os
import json
def lambda_handler(event, context):
print(event)
raise MoveableException("Test")
class MoveableException(Exception):
def __init__(self, message: str):
super().__init__(message)
`
### Environment
```markdown
- OS: Windows WSL Ubuntu 20.04.6 LTS
- LocalStack:
LocalStack version: 4.0.2
LocalStack Docker image sha: sha256:aa6b30e7e7e3aa25e6eb4b6ada4b9c93646531284df7e9541e1d9e9f6b94fe04
LocalStack build date:
LocalStack build git hash:
```
### Anything else?
Additional log:
`
2024-11-27 12:31:16 2024-11-27T10:31:16.787 ERROR --- [ad-22 (eval)] l.s.s.a.c.eval_component : Exception=FailureEventException, Error=FetchJob FAILED, Details={"taskFailedEventDetails": {"error": "FetchJob FAILED", "cause": "CSV Fetch Job Failed"}} at '(StateFail| {'comment': None, 'input_path': (InputPathBase| {'path': '$'}, 'output_path': (OutputPathBase| {'output_path': '$'}, 'state_entered_event_type': <HistoryEventType.FailStateEntered: 'FailStateEntered'>, 'state_exited_event_type': None, 'cause': (CauseConst| {'value': 'CSV Fetch Job Failed'}, 'error': (ErrorConst| {'value': 'FetchJob FAILED'}, 'name': 'JobFailed', 'query_language': (QueryLanguage| {'query_language_mode': QueryLanguageMode.JSONPath(130)}, 'state_type': <StateType.Fail: 18>, 'continue_with': <localstack.services.stepfunctions.asl.component.state.state_continue_with.ContinueWithNext object at 0x7fdae6a64bd0>, 'assign_decl': None, 'output': None}'
`
docker-compose:
localstack:
image: localstack/localstack:4.0.2
ports:
- 14566:4566 # LocalStack Gateway
- 14510-14559:4510-4559 # external services port range
expose:
- 4566
environment:
DEBUG: 0
SERVICES: s3,stepfunctions,lambda,iam,events,logs
AWS_DEFAULT_REGION: eu-central-1
S3_SKIP_SIGNATURE_VALIDATION: 1
DOCKER_HOST: "unix:///var/run/docker.sock"
volumes:
- data-localstack:/var/lib/localstack
- /var/run/docker.sock:/var/run/docker.sock
- ./.dc/localstack/init:/etc/localstack/init
- ./.dc/localstack/data:/data
| closed | 2024-11-27T10:52:31Z | 2024-12-27T14:02:53Z | https://github.com/localstack/localstack/issues/11943 | [
"type: bug",
"status: response required",
"aws:stepfunctions",
"status: resolved/stale"
] | derek-cbtw | 3 |
autokey/autokey | automation | 372 | Circular import trying to test dialogs | ## Classification:
Bug
## Reproducibility:
Always
## Version
AutoKey version: Develop
Used GUI (Gtk, Qt, or both): both
## Description
If you go to https://github.com/BlueDrink9/autokey/tree/regex and run the tests, you'll see that one test fails because of a circular import. This makes it very difficult to mock and test UI code, because importing it fails.
Can you please take a look and see if it is totally necessary to have that order of imports there? | closed | 2020-02-22T00:30:58Z | 2020-04-22T12:09:47Z | https://github.com/autokey/autokey/issues/372 | [
"bug"
] | BlueDrink9 | 8 |
pyeve/eve | flask | 1,211 | Controlling pagination over large collections | @nicolaiarocci Could you help me understand how the default pagination works?
Is it the standard limit + skip based pagination? If so, this strategy is known to be less performant over large collections after a good number of iterations. Is there a way to extend / change the it? Or should I create a custom endpoint and handler if a different pagination strategy is required.
I've seen the OPTIMIZE_PAGINATION_FOR_SPEED option and understand the count query for every request might become the bottleneck over large collections.
I have
### Environment
* Python version: 3.5.2
* Eve version: 0.8.1
P.S.: Loved Eve. :+1: :) | closed | 2018-11-29T15:49:51Z | 2019-03-28T15:00:29Z | https://github.com/pyeve/eve/issues/1211 | [] | checkaayush | 1 |
nikitastupin/clairvoyance | graphql | 101 | error | hello. not sure whats the problem so just put it out here.
i installed it with the command
```
pip3 install clairvoyance
```
since Python 2.7 reached the end of its life on January 1st, 2020 and is deprecated etc
```
clairvoyance https://<academy URL>/graphql/v1
2024-06-06 14:37:54 INFO | Starting blind introspection on https://xx/graphql/v1...
2024-06-06 14:37:54 INFO | Iteration 1
2024-06-06 14:37:55 WARNING | Error posting to https://xxx/graphql/v1: Cannot connect to host x:443 ssl:default [Connect call failed ('34.246.129.62', 443)]
2024-06-06 14:37:55 WARNING | Error posting to https://xxx/graphql/v1: Cannot connect to host xxx:443 ssl:default [Connect call failed ('79.125.84.16', 443)]
2024-06-06 14:37:56 WARNING | Error posting to https://xxx/graphql/v1: Cannot connect to host xx:443 ssl:default [Connect call failed ('34.246.129.62', 443)]
Traceback (most recent call last):
File "/home/kali/.local/lib/python3.11/site-packages/clairvoyance/oracle.py", line 425, in probe_typeref
raise Exception(f"""Unable to get TypeRef for {documents} in context {context}.
Exception: Unable to get TypeRef for ['query { xbox }', 'query { xbox { lol } }'] in context FuzzingContext.FIELD.
It is very likely that Field Suggestion is not fully enabled on this endpoint.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/kali/.local/bin/clairvoyance", line 8, in <module>
sys.exit(cli())
^^^^^
File "/home/kali/.local/lib/python3.11/site-packages/clairvoyance/cli.py", line 142, in cli
asyncio.run(
File "/usr/lib/python3.11/asyncio/runners.py", line 190, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/asyncio/base_events.py", line 654, in run_until_complete
return future.result()
^^^^^^^^^^^^^^^
File "/home/kali/.local/lib/python3.11/site-packages/clairvoyance/cli.py", line 89, in blind_introspection
schema = await oracle.clairvoyance(
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/kali/.local/lib/python3.11/site-packages/clairvoyance/oracle.py", line 594, in clairvoyance
field, args = await task
^^^^^^^^^^
File "/usr/lib/python3.11/asyncio/tasks.py", line 615, in _wait_for_one
return f.result() # May raise f.exception().
^^^^^^^^^^
File "/home/kali/.local/lib/python3.11/site-packages/clairvoyance/oracle.py", line 525, in explore_field
typeref = await probe_field_type(
^^^^^^^^^^^^^^^^^^^^^^^
File "/home/kali/.local/lib/python3.11/site-packages/clairvoyance/oracle.py", line 444, in probe_field_type
return await probe_typeref(documents, FuzzingContext.FIELD)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/kali/.local/lib/python3.11/site-packages/clairvoyance/oracle.py", line 428, in probe_typeref
raise Exception(e) from e
Exception: Unable to get TypeRef for ['query { xbox }', 'query { xbox { lol } }'] in context FuzzingContext.FIELD.
It is very likely that Field Suggestion is not fully enabled on this endpoint.
2024-06-06 14:37:59 ERROR | Unclosed client session
client_session: <aiohttp.client.ClientSession object at 0x7f2af6b1d090>
``` | open | 2024-06-06T18:40:08Z | 2024-08-27T06:13:35Z | https://github.com/nikitastupin/clairvoyance/issues/101 | [
"bug",
"question"
] | suljov | 1 |
tensorflow/tensor2tensor | machine-learning | 1,580 | transformer_base for Language Model involves (encoder+decoder) or decoder only? | ### Description
How does transformer base model checks for (encoder_decoder) or (decoder only) combination for language modelling? Because in language modelling only decoder part is needed, so if we use 'transformer_base' model for language modelling, how does model set model architecture to be (encoder_decoder) or decoder?
...
### Environment information
```
OS: <your answer here>
$ pip freeze | grep tensor
# your output here
$ python -V
# your output here
```
### For bugs: reproduction and error logs
```
# Steps to reproduce:
...
```
```
# Error logs:
...
```
| open | 2019-05-21T08:25:21Z | 2019-05-21T08:25:21Z | https://github.com/tensorflow/tensor2tensor/issues/1580 | [] | ashu5644 | 0 |
JaidedAI/EasyOCR | pytorch | 589 | RuntimeError: DataLoader worker (pid(s) 7228, 10380, 9840, 12944) exited unexpectedly | I am trying to run the trainer ipynb but there is an error as follows:
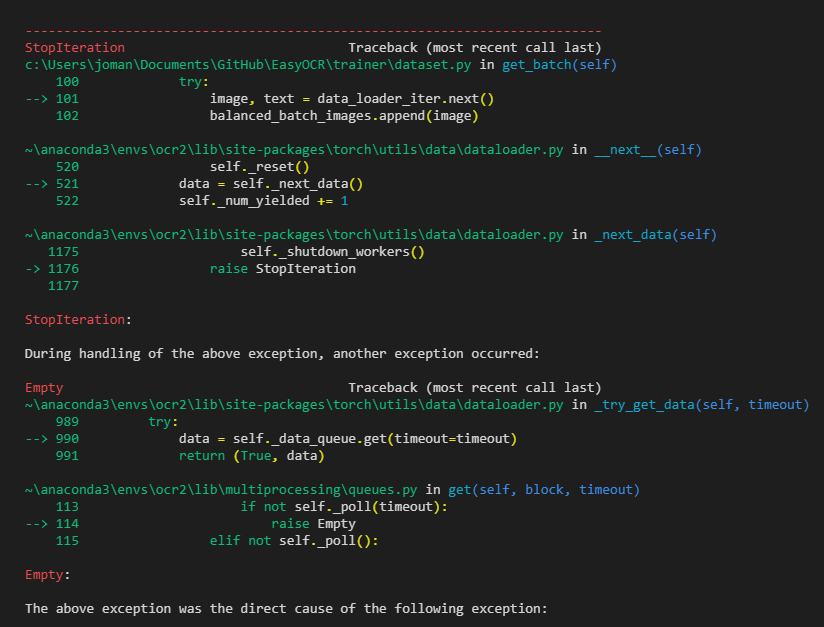

Is there anyone who can help with this? | closed | 2021-11-09T04:22:05Z | 2022-08-07T05:01:20Z | https://github.com/JaidedAI/EasyOCR/issues/589 | [] | jingjie181 | 1 |
aymericdamien/TopDeepLearning | tensorflow | 23 | Add Dlib | A toolkit for making real world machine learning and data analysis applications in C++ http://dlib.net
On github https://github.com/davisking/dlib | open | 2017-12-05T08:57:53Z | 2017-12-05T08:57:53Z | https://github.com/aymericdamien/TopDeepLearning/issues/23 | [] | pi-null-mezon | 0 |
TencentARC/GFPGAN | deep-learning | 243 | Permission Denied when Installing setup.py | I have zero code knowledge but can follow instructions well enough. But I've run into the following error and don't know how to fix it. Please help!

| closed | 2022-08-26T19:46:49Z | 2023-01-20T03:46:21Z | https://github.com/TencentARC/GFPGAN/issues/243 | [] | Dartterious | 2 |
mljar/mljar-supervised | scikit-learn | 435 | Error when using "mae" metric in Optuna mode | Hi ,
I encountered the following error when training in optuna mode:
`Exception in LightgbmObjective The entry associated with the validation name "validation" and the metric name "mae" is not found in the evaluation result list [('validation', 'l1', 0.23193058898755722, False)].`

Idk if it's a bug for the metric or I'm feeding bad data. Any help would be great. Thanks! | closed | 2021-07-16T09:58:19Z | 2021-07-19T08:44:02Z | https://github.com/mljar/mljar-supervised/issues/435 | [
"bug"
] | Zacchaeus00 | 4 |
allure-framework/allure-python | pytest | 726 | Add support for allure decorators and allyre.dynamic functions to allure-pytest-bdd | Currently, only allure.attach and allure.attach.file functions are supported in allure-pytest-bdd. The following functions and decorators need to be supported as well:
- `@allure.title` decorator
- `@allure.description` decorator
- `@allure.description_html` decorator
- `@allure.label` decorator
- `@allure.severity` decorator
- `@allure.epic` decorator
- `@allure.feature` decorator
- `@allure.story` decorator
- `@allure.suite` decorator
- `@allure.parent_suite` decorator
- `@allure.sub_suite` decorator
- `@allure.tag` decorator
- `@allure.id` decorator
- `@allure.manual` decorator
- `@allure.link` decorator
- `@allure.issue` decorator
- `@allure.testcase` decorator
- `allure.dynamic.title` function
- `allure.dynamic.description` function
- `allure.dynamic.description_html` function
- `allure.dynamic.label` function
- `allure.dynamic.severity` function
- `allure.dynamic.epic` function
- `allure.dynamic.feature` function
- `allure.dynamic.story` function
- `allure.dynamic.tag` function
- `allure.dynamic.id` function
- `allure.dynamic.link` function
- `allure.dynamic.parameter` function
- `allure.dynamic.issue` function
- `allure.dynamic.testcase` function
- `allure.dynamic.suite` function
- `allure.dynamic.parent_suite` function
- `allure.dynamic.sub_suite` function
- `allure.dynamic.manual` function | open | 2023-01-20T09:57:31Z | 2025-03-12T10:32:56Z | https://github.com/allure-framework/allure-python/issues/726 | [
"task:new feature",
"theme:pytest-bdd",
"contribute"
] | delatrie | 7 |
recommenders-team/recommenders | deep-learning | 1,740 | [ASK] Could I contribute to developing some sequential models, like DIN and DIEN? | I found that some classical sequential models like DIN and DIEN are not contained in this repo. If I develop these models, is it possible to put them into this repo?
| closed | 2022-06-12T00:30:03Z | 2023-08-31T21:52:51Z | https://github.com/recommenders-team/recommenders/issues/1740 | [
"help wanted"
] | Czzzzzzzz | 2 |
gradio-app/gradio | data-science | 10,691 | Demo for highlighting text in a pdf file for LLM RAG purposes | - [x] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
I wanted a way to simply show a PDF with highlighted text at the right page (for LLM RAG purposes).
**Describe the solution you'd like**
A demo to build such an app.
| closed | 2025-02-27T15:10:48Z | 2025-03-06T11:20:24Z | https://github.com/gradio-app/gradio/issues/10691 | [
"docs/website"
] | maxenceleguery | 0 |
developmentseed/lonboard | data-visualization | 533 | Add test for fixed GeoArrow reprojection with GeoPandas 1.0 | Test for https://github.com/developmentseed/lonboard/issues/528 that was fixed (manually tested) in https://github.com/developmentseed/lonboard/pull/532. When GeoPandas 1.0 is released we should add a test for this. | closed | 2024-05-27T12:39:42Z | 2024-09-24T19:35:26Z | https://github.com/developmentseed/lonboard/issues/533 | [] | kylebarron | 0 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 790 | Difference about speaker_embedding part in Synthesizer? | Hi, firstly thanks for your work!
I find that in model.py of Synthesizer, it use Tacotron but, in forward part of that , the "speaker_embedding default ==None", so it don't use speaker_embedding when train synthesizer?
I remember that in older version, the speaker_embedding is used in model Tacotron2. Could you please tell me why and what's the difference, effect on result? | closed | 2021-07-07T07:47:54Z | 2021-08-25T09:58:11Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/790 | [] | ymzlygw | 1 |
charlesq34/pointnet | tensorflow | 111 | the effect of the alignment of feature space | Since Data alignment has been done, why are features aligned, what is the role of feature alignment, and what is the label to train the T-net in feature space? | open | 2018-06-08T09:25:04Z | 2018-06-08T09:25:04Z | https://github.com/charlesq34/pointnet/issues/111 | [] | Emma0928 | 0 |
biolab/orange3 | scikit-learn | 6,177 | Update the latest documentation | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following questions to the best of your ability.
-->
**What's wrong?**
<!-- Be specific, clear, and concise. Include screenshots if relevant. -->
<!-- If you're getting an error message, copy it, and enclose it with three backticks (```). -->
The documentation is outdated. One example is from this [Sieve Diagram](https://orangedatamining.com/widget-catalog/visualize/sievediagram/). It needs to be updated since it tends to confuse the newcomer or new user.
The current image (there are D notations that I don't know of before the variable)
The latest version of Orange image (there are C notations which is different than the docs said)
**How can we reproduce the problem?**
<!-- Upload a zip with the .ows file and data. -->
<!-- Describe the steps (open this widget, click here, then add this...) -->
Go to the docs [link](https://orangedatamining.com/widget-catalog/visualize/sievediagram/) above.
**What's your environment?**
<!-- To find your Orange version, see "Help → About → Version" or `Orange.version.full_version` in code -->
- Operating system: Windows 10
- Orange version: 3.33.0
- How you installed Orange: Portable
I would like to open a PR to help you guys update it if I'm allowed to. Please, show me the best practices on how to do it. I already skimming the [contributing guidelines](https://github.com/biolab/orange3/blob/4788c6e48f6e1a75883c492b5e5a74dadb2c117d/CONTRIBUTING.md#documentation) | closed | 2022-10-20T14:57:37Z | 2022-10-20T18:43:40Z | https://github.com/biolab/orange3/issues/6177 | [
"bug report"
] | ranggakd | 1 |
gradio-app/gradio | python | 10,309 | Unsustained functionality of event 'show_progress' | ### Describe the bug
In textbox.submit(), when I set show_progress='hidden' or 'minimal' to hide progressing animation (namely the spinner and time info), it works at the first input, but fail after that. This case is observed with other downstream gradio components such as TextArea, Chatbot, etc.
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
def tmp(text):
time.sleep(1)
return [{'role':'user','content':text},
{'role':'assistant','content':'Hi'}]
with gr.Blocks() as demo:
box=gr.Textbox()
output=gr.Chatbot(type="messages",layout='bubble')
box.submit(fn=tmp,inputs=[box],outputs=output,show_progress='minimal')
demo.launch()
```
### Screenshot


### Logs
_No response_
### System Info
```shell
I am using gradio '5.5.0'
```
### Severity
I can work around it | closed | 2025-01-08T00:14:56Z | 2025-01-08T17:37:38Z | https://github.com/gradio-app/gradio/issues/10309 | [
"bug",
"needs repro"
] | ZhaoyuanQiu | 2 |
yihong0618/running_page | data-visualization | 479 | 無法更改Site Metadata資料 | 你好,我在Ubuntu 上Git clone相關的git之後 安裝了該running page的docker
配置完後運行成功進入
但是修改gatsby-config.js 裏面的Site Metadata後無法更新網頁
網頁上的超連結依然是yihong的網站
網站標題/圖標等也無法更改
已經嘗試整個image 和container remove後再次用新的gatsby-config.js develop
也是同樣的結果 | closed | 2023-09-02T02:28:42Z | 2023-09-10T04:15:39Z | https://github.com/yihong0618/running_page/issues/479 | [] | QWERT1984 | 2 |
stanfordnlp/stanza | nlp | 596 | tweets get broken when some certain word sequences present | Hello,
I'm analysing a dataset of tweets and I get some tweets broken into several sentences. I found that some word sequences are causing this and just wondering if there's any workaround. One example is _appreciated thanks_, where _thanks_ would break the sentence if it appears right after _appreciated_ in the text passed as below.
thanks in advance.
<img width="1215" alt="Screenshot 2021-01-18 at 1 48 05 am" src="https://user-images.githubusercontent.com/44207018/104863944-79feaa80-592f-11eb-99e6-86ee55c12aaf.png">
| closed | 2021-01-18T01:50:59Z | 2021-03-26T06:21:40Z | https://github.com/stanfordnlp/stanza/issues/596 | [
"question",
"stale"
] | AboSahab | 3 |
miLibris/flask-rest-jsonapi | sqlalchemy | 132 | Attempting to build schema for non-existing resource | Hi, guys.
First of all, congrats on the fantastic library you've made. It's super cool.
I'm submitting a report on erroneous (from my POV) behavior. Here's STR:
1. Create a schema where at least one field has default value like this:
```
state = fields.Integer(default=0)
```
2. Create resource for that schema and route leading to it.
3. Try to fetch single resource by non-existing ID:
```
GET /bots/122
```
4. AR:
* 500 Internal server error
* A snippet from log:
> AttributeError: 'id' is not a valid attribute of {'state': 0}
5. ER:
```
{
data: null
}
```
So, the problem is in that method ResourceDetail.get() after figuring out that there's no resource with provided ID still tries to built a result:
```
schema = compute_schema(self.schema,
getattr(self, 'get_schema_kwargs', dict()),
qs,
qs.include)
result = schema.dump(obj).data
```
But if there's some field with default value in schema we get a semi-valid resource object { state: 0 } without ID. Then, on trying to create a self link system tries to get 'id' field on { state: 0 } and eventually produces AttributeError.
I think it should be fixed by skipping compute_schema and schema.dump in the ResourceDetail.get() method. As soon as it's clear that resource does not exist we may simply jump to after_get.
What do you think? | closed | 2018-11-20T20:22:33Z | 2019-03-06T13:16:15Z | https://github.com/miLibris/flask-rest-jsonapi/issues/132 | [] | aramwram | 2 |
LAION-AI/Open-Assistant | machine-learning | 3,061 | Shouldn't this influence the `input_length` below? | https://github.com/LAION-AI/Open-Assistant/blob/ded5acaae3cf4d38c93372fa7f7ca822dd781a1f/inference/worker/utils.py#L89-L91 | closed | 2023-05-06T14:22:03Z | 2023-05-07T21:02:38Z | https://github.com/LAION-AI/Open-Assistant/issues/3061 | [
"inference"
] | yk | 1 |
graphistry/pygraphistry | pandas | 54 | PyGraphistry should default to webserver, not localhost:3000 | (+ @thibaudh )
Recent environment variable commit seems to have broken the default of pointing to `proxy-labs.graphistry.com`:
https://github.com/graphistry/pygraphistry/commit/6ec3e07f212187eb0e624558e3db4798990abfa9#diff-515fcd0720a2f875b1a2765a63aed8e0R35
To see that `localhost:3000` is being used, have a server running locally and try running a dataset through the notebook. You'll see that it processes through the local instance.
| closed | 2016-02-15T06:09:28Z | 2016-02-15T16:29:34Z | https://github.com/graphistry/pygraphistry/issues/54 | [
"bug",
"p1"
] | lmeyerov | 0 |
piccolo-orm/piccolo | fastapi | 1,078 | ASGI template doesn't work for Esmerald 3.4.1 | I noticed our integration tests fail when using `esmerald==3.4.1`.
However, if I version pin to `esmerald==3.3.0` they still work (I picked this older version arbitrarily).
https://github.com/piccolo-orm/piccolo/actions/runs/10863888957/job/30148554519?pr=1077 | closed | 2024-09-14T16:36:52Z | 2024-09-30T16:28:19Z | https://github.com/piccolo-orm/piccolo/issues/1078 | [
"bug"
] | dantownsend | 17 |
chatanywhere/GPT_API_free | api | 213 | 免费key出现“账户余额过低不足以支持本次请求,请前往 https://buyca.top/buy/18 充值” | **Describe the bug 描述bug**
OpenAI: 账户余额过低不足以支持本次请求,请前往 https://buyca.top/buy/18 充值。Your account balance is not sufficient to support this request. Please visit https://buyca.top/buy/18 to recharge.
**To Reproduce 复现方法**
1. 使用chatbox
2. URL:https://api.chatanywhere.tech
3. OpenAI: 账户余额过低不足以支持本次请求,请前往 https://buyca.top/buy/18 充值。Your account balance is not sufficient to support this request. Please visit https://buyca.top/buy/18 to recharge.
**Screenshots 截图**
If applicable, add screenshots to help explain your problem.
**Tools or Programming Language 使用的工具或编程语言**
Describe in detail the GPT tool or programming language you used to encounter the problem
**Additional context 其他内容**
我确定用的是免费key,收费key只在电脑上用的。
而且这个免费key一直正常,今天突然不行了。
是我的key出什么问题了么?
谢谢。
| closed | 2024-04-12T12:28:28Z | 2024-04-14T10:54:13Z | https://github.com/chatanywhere/GPT_API_free/issues/213 | [] | bailitingqin | 9 |
allenai/allennlp | data-science | 5,663 | When training SRL model:"AssertionError: Found no field that needed padding; we are surprised you got this error, please open an issue on github" | <!--
Please fill this template entirely and do not erase any of it.
We reserve the right to close without a response bug reports which are incomplete.
If you have a question rather than a bug, please ask on [Stack Overflow](https://stackoverflow.com/questions/tagged/allennlp) rather than posting an issue here.
-->
## Checklist
<!-- To check an item on the list replace [ ] with [x]. -->
- [x] I have verified that the issue exists against the `main` branch of AllenNLP.
- [x] I have read the relevant section in the [contribution guide](https://github.com/allenai/allennlp/blob/main/CONTRIBUTING.md#bug-fixes-and-new-features) on reporting bugs.
- [x] I have checked the [issues list](https://github.com/allenai/allennlp/issues) for similar or identical bug reports.
- [x] I have checked the [pull requests list](https://github.com/allenai/allennlp/pulls) for existing proposed fixes.
- [x] I have checked the [CHANGELOG](https://github.com/allenai/allennlp/blob/main/CHANGELOG.md) and the [commit log](https://github.com/allenai/allennlp/commits/main) to find out if the bug was already fixed in the main branch.
- [x] I have included in the "Description" section below a traceback from any exceptions related to this bug.
- [x] I have included in the "Related issues or possible duplicates" section beloew all related issues and possible duplicate issues (If there are none, check this box anyway).
- [x] I have included in the "Environment" section below the name of the operating system and Python version that I was using when I discovered this bug.
- [x] I have included in the "Environment" section below the output of `pip freeze`.
- [x] I have included in the "Steps to reproduce" section below a minimally reproducible example.
## Description
<!-- Please provide a clear and concise description of what the bug is here. --> We're attempting to train a SRL model, using the configuration file seen below.
Below the configuration file, there is a conll formatted data example that we're using.
As per this, [stackoverflow question](https://stackoverflow.com/questions/69090025/how-to-train-allennlp-srl-on-non-english-languages), the only columns that are needed are words and SRLtags columns. Can you please confirm that this is the case, if so I'm not sure why we're receiving this error, please advise.
```
local bert_model = "bert-base-uncased";
{
"dataset_reader": {
"type": "srl",
"bert_model_name": bert_model,
},
"data_loader": {
"batch_sampler": {
"type": "bucket",
"batch_size" : 32
}
},
"train_data_path": "path/conll_data/ALLEN_FRENCH_TEST_2_train.conll",
"validation_data_path":"path/conll_data/ALLEN_FRENCH_TEST_2_val.conll",
"model": {
"type": "srl_bert",
"embedding_dropout": 0.1,
"bert_model": bert_model,
},
"trainer": {
"optimizer": {
"type": "huggingface_adamw",
"lr": 5e-5,
"correct_bias": false,
"weight_decay": 0.01,
"parameter_groups": [
[["bias", "LayerNorm.bias", "LayerNorm.weight", "layer_norm.weight"], {"weight_decay": 0.0}],
],
},
"learning_rate_scheduler": {
"type": "slanted_triangular",
},
"checkpointer": {
"keep_most_recent_by_count": 2,
},
"grad_norm": 1.0,
"num_epochs": 15,
"validation_metric": "+f1-measure-overall",
},
}
```
```
_ _ 0 @Greguyyyy ADP _ _ _ _ _ _ _ _ _
_ _ 1 @HalbeardD PROPN _ _ _ _ _ _ _ _ _
_ _ 2 @Tlibdij PROPN _ _ _ _ _ _ _ _ _
_ _ 3 @JLMelenchon NUM _ _ _ _ _ _ _ _ _
_ _ 4 @BurgerKingFR PROPN _ _ _ _ _ _ _ _ _
_ _ 5 Honnêtement ADV _ _ _ _ _ _ _ (ARGM-ADV*) _
_ _ 6 le DET _ _ _ _ _ _ _ _ _
_ _ 7 capitalisme NOUN _ _ _ _ _ _ _ (ARG1*) _
_ _ 8 a AUX _ _ _ _ _ _ (V*) _ _
_ _ 9 été AUX _ _ _ _ _ _ _ (ARG2*) _
_ _ 10 génial ADJ _ _ _ _ _ _ _ _ _
_ _ 11 sur ADP _ _ _ _ _ _ _ (ARGM-TMP* _
_ _ 12 cette DET _ _ _ _ _ _ _ * _
_ _ 13 période NOUN _ _ _ _ _ _ _ *) _
_ _ 14 … PROPN _ _ _ _ _ _ _ _ _
```
<details>
<summary><b>Python traceback: </b></summary>
<p>
<!-- Paste the traceback from any exception (if there was one) in between the next two lines below -->
```
2022-06-09 20:21:20,754 - CRITICAL - root - Uncaught exception
Traceback (most recent call last):
File "/usr/local/bin/allennlp", line 8, in <module>
sys.exit(run())
File "/usr/local/lib/python3.7/dist-packages/allennlp/__main__.py", line 39, in run
main(prog="allennlp")
File "/usr/local/lib/python3.7/dist-packages/allennlp/commands/__init__.py", line 120, in main
args.func(args)
File "/usr/local/lib/python3.7/dist-packages/allennlp/commands/train.py", line 120, in train_model_from_args
file_friendly_logging=args.file_friendly_logging,
File "/usr/local/lib/python3.7/dist-packages/allennlp/commands/train.py", line 186, in train_model_from_file
return_model=return_model,
File "/usr/local/lib/python3.7/dist-packages/allennlp/commands/train.py", line 264, in train_model
file_friendly_logging=file_friendly_logging,
File "/usr/local/lib/python3.7/dist-packages/allennlp/commands/train.py", line 508, in _train_worker
metrics = train_loop.run()
File "/usr/local/lib/python3.7/dist-packages/allennlp/commands/train.py", line 581, in run
return self.trainer.train()
File "/usr/local/lib/python3.7/dist-packages/allennlp/training/gradient_descent_trainer.py", line 771, in train
metrics, epoch = self._try_train()
File "/usr/local/lib/python3.7/dist-packages/allennlp/training/gradient_descent_trainer.py", line 793, in _try_train
train_metrics = self._train_epoch(epoch)
File "/usr/local/lib/python3.7/dist-packages/allennlp/training/gradient_descent_trainer.py", line 473, in _train_epoch
for batch_group in batch_group_generator_tqdm:
File "/usr/local/lib/python3.7/dist-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/usr/local/lib/python3.7/dist-packages/allennlp/common/util.py", line 142, in lazy_groups_of
s = list(islice(iterator, group_size))
File "/usr/local/lib/python3.7/dist-packages/allennlp/data/data_loaders/multiprocess_data_loader.py", line 335, in __iter__
yield from self._iter_batches()
File "/usr/local/lib/python3.7/dist-packages/allennlp/data/data_loaders/multiprocess_data_loader.py", line 395, in _iter_batches
for batch in self._instances_to_batches(self.iter_instances(), move_to_device=True):
File "/usr/local/lib/python3.7/dist-packages/allennlp/data/data_loaders/multiprocess_data_loader.py", line 639, in _instances_to_batches
for batch in batches:
File "/usr/local/lib/python3.7/dist-packages/allennlp/data/data_loaders/multiprocess_data_loader.py", line 636, in <genexpr>
[instances[i] for i in batch_indices]
File "/usr/local/lib/python3.7/dist-packages/allennlp/data/samplers/bucket_batch_sampler.py", line 117, in get_batch_indices
indices, _ = self._argsort_by_padding(instances)
File "/usr/local/lib/python3.7/dist-packages/allennlp/data/samplers/bucket_batch_sampler.py", line 92, in _argsort_by_padding
self._guess_sorting_keys(instances)
File "/usr/local/lib/python3.7/dist-packages/allennlp/data/samplers/bucket_batch_sampler.py", line 159, in _guess_sorting_keys
"Found no field that needed padding; we are surprised you got this error, please "
AssertionError: Found no field that needed padding; we are surprised you got this error, please open an issue on github
```
</p>
</details>
## Related issues or possible duplicates
- None
## Environment
<!-- Provide the name of operating system below (e.g. OS X, Linux) -->
OS: Googlecolab(Linux)
<!-- Provide the Python version you were using (e.g. 3.7.1) -->
Python version: Python 3.7.13
<details>
<summary><b>Output of <code>pip freeze</code>:</b></summary>
<p>
<!-- Paste the output of `pip freeze` in between the next two lines below -->
```
absl-py==1.0.0
aiohttp==3.8.1
aiosignal==1.2.0
alabaster==0.7.12
albumentations==0.1.12
allennlp==2.9.3
allennlp-models==2.9.3
altair==4.2.0
appdirs==1.4.4
argon2-cffi==21.3.0
argon2-cffi-bindings==21.2.0
arviz==0.12.1
astor==0.8.1
astropy==4.3.1
astunparse==1.6.3
async-timeout==4.0.2
asynctest==0.13.0
atari-py==0.2.9
atomicwrites==1.4.0
attrs==21.4.0
audioread==2.1.9
autograd==1.4
Babel==2.10.1
backcall==0.2.0
backports.csv==1.0.7
base58==2.1.1
beautifulsoup4==4.6.3
bert-score==0.3.11
bleach==5.0.0
blis==0.4.1
bokeh==2.3.3
boto3==1.24.5
botocore==1.27.5
Bottleneck==1.3.4
branca==0.5.0
bs4==0.0.1
CacheControl==0.12.11
cached-path==1.1.2
cached-property==1.5.2
cachetools==4.2.4
catalogue==1.0.0
certifi==2022.5.18.1
cffi==1.15.0
cftime==1.6.0
chardet==3.0.4
charset-normalizer==2.0.12
checklist==0.0.11
cheroot==8.6.0
CherryPy==18.6.1
click==7.1.2
cloudpickle==1.3.0
cmake==3.22.4
cmdstanpy==0.9.5
colorcet==3.0.0
colorlover==0.3.0
community==1.0.0b1
conllu==4.4.1
contextlib2==0.5.5
convertdate==2.4.0
coverage==3.7.1
coveralls==0.5
crcmod==1.7
cryptography==37.0.2
cufflinks==0.17.3
cvxopt==1.2.7
cvxpy==1.0.31
cycler==0.11.0
cymem==2.0.6
Cython==0.29.30
daft==0.0.4
dask==2.12.0
datascience==0.10.6
datasets==2.2.2
debugpy==1.0.0
decorator==4.4.2
defusedxml==0.7.1
descartes==1.1.0
dill==0.3.4
distributed==1.25.3
dlib==19.18.0+zzzcolab20220513001918
dm-tree==0.1.7
docker-pycreds==0.4.0
docopt==0.6.2
docutils==0.17.1
dopamine-rl==1.0.5
earthengine-api==0.1.311
easydict==1.9
ecos==2.0.10
editdistance==0.5.3
en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.2.5/en_core_web_sm-2.2.5.tar.gz
entrypoints==0.4
ephem==4.1.3
et-xmlfile==1.1.0
fa2==0.3.5
fairscale==0.4.6
fastai==1.0.61
fastdtw==0.3.4
fastjsonschema==2.15.3
fastprogress==1.0.2
fastrlock==0.8
fbprophet==0.7.1
feather-format==0.4.1
feedparser==6.0.10
filelock==3.4.2
firebase-admin==4.4.0
fix-yahoo-finance==0.0.22
Flask==1.1.4
flatbuffers==2.0
folium==0.8.3
fr-core-news-sm @ https://github.com/explosion/spacy-models/releases/download/fr_core_news_sm-2.2.5/fr_core_news_sm-2.2.5.tar.gz
frozenlist==1.3.0
fsspec==2022.5.0
ftfy==6.1.1
future==0.16.0
gast==0.5.3
GDAL==2.2.2
gdown==4.4.0
gensim==3.6.0
geographiclib==1.52
geopy==1.17.0
gin-config==0.5.0
gitdb==4.0.9
GitPython==3.1.27
glob2==0.7
google==2.0.3
google-api-core==1.31.6
google-api-python-client==1.12.11
google-auth==1.35.0
google-auth-httplib2==0.0.4
google-auth-oauthlib==0.4.6
google-cloud-bigquery==1.21.0
google-cloud-bigquery-storage==1.1.1
google-cloud-core==2.3.1
google-cloud-datastore==1.8.0
google-cloud-firestore==1.7.0
google-cloud-language==1.2.0
google-cloud-storage==2.4.0
google-cloud-translate==1.5.0
google-colab @ file:///colabtools/dist/google-colab-1.0.0.tar.gz
google-crc32c==1.3.0
google-pasta==0.2.0
google-resumable-media==2.3.3
googleapis-common-protos==1.56.2
googledrivedownloader==0.4
graphviz==0.10.1
greenlet==1.1.2
grpcio==1.46.3
gspread==3.4.2
gspread-dataframe==3.0.8
gym==0.17.3
h5py==3.1.0
HeapDict==1.0.1
hijri-converter==2.2.4
holidays==0.10.5.2
holoviews==1.14.9
html5lib==1.0.1
httpimport==0.5.18
httplib2==0.17.4
httplib2shim==0.0.3
huggingface-hub==0.5.1
humanize==0.5.1
hyperopt==0.1.2
ideep4py==2.0.0.post3
idna==2.10
imageio==2.4.1
imagesize==1.3.0
imbalanced-learn==0.8.1
imblearn==0.0
imgaug==0.2.9
importlib-metadata==4.11.4
importlib-resources==5.7.1
imutils==0.5.4
inflect==2.1.0
iniconfig==1.1.1
intel-openmp==2022.1.0
intervaltree==2.1.0
ipykernel==4.10.1
ipython==5.5.0
ipython-genutils==0.2.0
ipython-sql==0.3.9
ipywidgets==7.7.0
iso-639==0.4.5
itsdangerous==1.1.0
jaraco.classes==3.2.1
jaraco.collections==3.5.1
jaraco.context==4.1.1
jaraco.functools==3.5.0
jaraco.text==3.8.0
jax==0.3.8
jaxlib @ https://storage.googleapis.com/jax-releases/cuda11/jaxlib-0.3.7+cuda11.cudnn805-cp37-none-manylinux2014_x86_64.whl
jedi==0.18.1
jieba==0.42.1
Jinja2==2.11.3
jmespath==1.0.0
joblib==1.1.0
jpeg4py==0.1.4
jsonnet==0.18.0
jsonpickle==2.2.0
jsonschema==4.3.3
jupyter==1.0.0
jupyter-client==5.3.5
jupyter-console==5.2.0
jupyter-core==4.10.0
jupyterlab-pygments==0.2.2
jupyterlab-widgets==1.1.0
kaggle==1.5.12
kapre==0.3.7
keras==2.8.0
Keras-Preprocessing==1.1.2
keras-vis==0.4.1
kiwisolver==1.4.2
korean-lunar-calendar==0.2.1
libclang==14.0.1
librosa==0.8.1
lightgbm==2.2.3
llvmlite==0.34.0
lmdb==0.99
LunarCalendar==0.0.9
lxml==4.2.6
Markdown==3.3.7
MarkupSafe==2.0.1
matplotlib==3.2.2
matplotlib-inline==0.1.3
matplotlib-venn==0.11.7
missingno==0.5.1
mistune==0.8.4
mizani==0.6.0
mkl==2019.0
mlxtend==0.14.0
more-itertools==8.13.0
moviepy==0.2.3.5
mpmath==1.2.1
msgpack==1.0.3
multidict==6.0.2
multiprocess==0.70.12.2
multitasking==0.0.10
munch==2.5.0
murmurhash==1.0.7
music21==5.5.0
natsort==5.5.0
nbclient==0.6.4
nbconvert==5.6.1
nbformat==5.4.0
nest-asyncio==1.5.5
netCDF4==1.5.8
networkx==2.6.3
nibabel==3.0.2
nltk==3.7
notebook==5.3.1
numba==0.51.2
numexpr==2.8.1
numpy==1.21.6
nvidia-ml-py3==7.352.0
oauth2client==4.1.3
oauthlib==3.2.0
okgrade==0.4.3
opencv-contrib-python==4.1.2.30
opencv-python==4.1.2.30
openpyxl==3.0.10
opt-einsum==3.3.0
osqp==0.6.2.post0
overrides==3.1.0
packaging==21.3
palettable==3.3.0
pandas==1.3.5
pandas-datareader==0.9.0
pandas-gbq==0.13.3
pandas-profiling==1.4.1
pandocfilters==1.5.0
panel==0.12.1
param==1.12.1
parso==0.8.3
pathlib==1.0.1
pathtools==0.1.2
patsy==0.5.2
patternfork-nosql==3.6
pdfminer.six==20220524
pep517==0.12.0
pexpect==4.8.0
pickleshare==0.7.5
Pillow==7.1.2
pip-tools==6.2.0
plac==1.1.3
plotly==5.5.0
plotnine==0.6.0
pluggy==0.7.1
pooch==1.6.0
portend==3.1.0
portpicker==1.3.9
prefetch-generator==1.0.1
preshed==3.0.6
prettytable==3.3.0
progressbar2==3.38.0
prometheus-client==0.14.1
promise==2.3
prompt-toolkit==1.0.18
protobuf==3.17.3
psutil==5.4.8
psycopg2==2.7.6.1
ptyprocess==0.7.0
py==1.11.0
py-rouge==1.1
pyarrow==6.0.1
pyasn1==0.4.8
pyasn1-modules==0.2.8
pycocotools==2.0.4
pyconll==3.1.0
pycparser==2.21
pyct==0.4.8
pydata-google-auth==1.4.0
pydot==1.3.0
pydot-ng==2.0.0
pydotplus==2.0.2
PyDrive==1.3.1
pyemd==0.5.1
pyerfa==2.0.0.1
pyglet==1.5.0
Pygments==2.6.1
pygobject==3.26.1
pymc3==3.11.4
PyMeeus==0.5.11
pymongo==4.1.1
pymystem3==0.2.0
PyOpenGL==3.1.6
pyparsing==3.0.9
pyrsistent==0.18.1
pysndfile==1.3.8
PySocks==1.7.1
pystan==2.19.1.1
pytest==3.6.4
python-apt==0.0.0
python-chess==0.23.11
python-dateutil==2.8.2
python-docx==0.8.11
python-louvain==0.16
python-slugify==6.1.2
python-utils==3.2.3
pytz==2022.1
pyviz-comms==2.2.0
PyWavelets==1.3.0
PyYAML==3.13
pyzmq==23.0.0
qdldl==0.1.5.post2
qtconsole==5.3.0
QtPy==2.1.0
regex==2022.6.2
requests==2.23.0
requests-oauthlib==1.3.1
resampy==0.2.2
responses==0.18.0
rpy2==3.4.5
rsa==4.8
s3transfer==0.6.0
sacremoses==0.0.53
scikit-image==0.18.3
scikit-learn==1.0.2
scipy==1.4.1
screen-resolution-extra==0.0.0
scs==3.2.0
seaborn==0.11.2
semver==2.13.0
Send2Trash==1.8.0
sentencepiece==0.1.96
sentry-sdk==1.5.12
setproctitle==1.2.3
setuptools-git==1.2
sgmllib3k==1.0.0
Shapely==1.8.2
shortuuid==1.0.9
simplegeneric==0.8.1
six==1.15.0
sklearn==0.0
sklearn-pandas==1.8.0
smart-open==6.0.0
smmap==5.0.0
snowballstemmer==2.2.0
sortedcontainers==2.4.0
SoundFile==0.10.3.post1
soupsieve==2.3.2.post1
spacy==2.2.4
Sphinx==1.8.6
sphinxcontrib-serializinghtml==1.1.5
sphinxcontrib-websupport==1.2.4
SQLAlchemy==1.4.36
sqlparse==0.4.2
srsly==1.0.5
statsmodels==0.10.2
sympy==1.7.1
tables==3.7.0
tabulate==0.8.9
tblib==1.7.0
tempora==5.0.1
tenacity==8.0.1
tensorboard==2.8.0
tensorboard-data-server==0.6.1
tensorboard-plugin-wit==1.8.1
tensorboardX==2.5.1
tensorflow==2.8.2+zzzcolab20220527125636
tensorflow-datasets==4.0.1
tensorflow-estimator==2.8.0
tensorflow-gcs-config==2.8.0
tensorflow-hub==0.12.0
tensorflow-io-gcs-filesystem==0.26.0
tensorflow-metadata==1.8.0
tensorflow-probability==0.16.0
termcolor==1.1.0
terminado==0.13.3
testpath==0.6.0
text-unidecode==1.3
textblob==0.15.3
Theano-PyMC==1.1.2
thinc==7.4.0
threadpoolctl==3.1.0
tifffile==2021.11.2
tinycss2==1.1.1
tokenizers==0.10.3
tomli==2.0.1
toolz==0.11.2
torch==1.10.2
torchaudio @ https://download.pytorch.org/whl/cu113/torchaudio-0.11.0%2Bcu113-cp37-cp37m-linux_x86_64.whl
torchsummary==1.5.1
torchtext==0.12.0
torchvision==0.11.3
tornado==5.1.1
tqdm==4.64.0
traitlets==5.1.1
transformers==4.3.3
tweepy==3.10.0
typeguard==2.7.1
typer==0.4.1
typing-extensions==4.2.0
tzlocal==1.5.1
uritemplate==3.0.1
urllib3==1.25.11
vega-datasets==0.9.0
wandb==0.12.18
wasabi==0.9.1
wcwidth==0.2.5
webencodings==0.5.1
Werkzeug==1.0.1
widgetsnbextension==3.6.0
word2number==1.1
wordcloud==1.5.0
wrapt==1.14.1
xarray==0.20.2
xarray-einstats==0.2.2
xgboost==0.90
xkit==0.0.0
xlrd==1.1.0
xlwt==1.3.0
xxhash==3.0.0
yarl==1.7.2
yellowbrick==1.4
zc.lockfile==2.0
zict==2.2.0
zipp==3.8.0
```
</p>
</details>
## Steps to reproduce
<details>
<summary><b>Example source:</b></summary>
<p>
<!-- Add a fully runnable example in between the next two lines below that will reproduce the bug -->
Populate a training data file and validation file with the above conll example.
Run the below command using the above configuration file.
```
allennlp train /config_path/srl_train_1.jsonnet -s /model_output
```
</p>
</details>
| closed | 2022-06-09T21:07:28Z | 2022-10-06T16:10:53Z | https://github.com/allenai/allennlp/issues/5663 | [
"bug",
"stale"
] | philz0918 | 12 |
tflearn/tflearn | data-science | 881 | Print metric on screen per epoch instead of per step | This might be (or surely is) a trivial question, but I don't seem to find the solution in the documentation or online. I simply want to change the logs to be printed on screen when using tflearn.
For example, a simple model like this:
embedding_layer = input_data(shape=[None,max_seq_len], name='input')
net = embedding(
embedding_layer,
input_dim=vocab_size,
output_dim=embedding_dim,
weights_init = tf.convert_to_tensor(embedding_matrix, dtype='float32'),
trainable=False,
name="EmbeddingLayer")
net = fully_connected(embedded_sequences, class_count, activation='softmax')
net = regression(
net,
optimizer=optimizer,
loss='categorical_crossentropy')
model = tflearn.DNN(net, tensorboard_verbose=0)
When I use `model.fit`:
model.fit(
X, one_hot_y,
n_epoch=epochs,
batch_size = batch_size,
show_metric=True)
it prints the results per step:
---------------------------------
Run id: E2VXW6
Log directory: /tmp/tflearn_logs/
INFO:tensorflow:Summary name Accuracy/ (raw) is illegal; using Accuracy/__raw_ instead.
INFO:tensorflow:Summary name Accuracy/ (raw) is illegal; using Accuracy/__raw_ instead.
---------------------------------
Training samples: 18821
Validation samples: 0
--
Training Step: 1 | time: 0.035s
| Adam | epoch: 001 | loss: 0.00000 - acc: 0.0000 -- iter: 00032/18821
Training Step: 2 | total loss: 3.22912 | time: 0.039s
| Adam | epoch: 001 | loss: 3.22912 - acc: 0.0844 -- iter: 00064/18821
Training Step: 3 | total loss: 4.40546 | time: 0.043s
| Adam | epoch: 001 | loss: 4.40546 - acc: 0.0665 -- iter: 00096/18821
Training Step: 4 | total loss: 4.53110 | time: 0.047s
| Adam | epoch: 001 | loss: 4.53110 - acc: 0.0401 -- iter: 00128/18821
Training Step: 5 | total loss: 4.18489 | time: 0.051s
....
I have tried to change parameters like `snapshot_epoch ` or `snapshot_step` but I don't think these have any control over it. I even tried to code a callback class, but still prints per step.
How can I print **per epoch** instead? | closed | 2017-08-22T10:08:05Z | 2017-08-23T16:26:00Z | https://github.com/tflearn/tflearn/issues/881 | [] | jrzaurin | 1 |
qubvel-org/segmentation_models.pytorch | computer-vision | 722 | How to use default encoder of u-net? | Hi, I am trying to do some comparison with the initial network. But I didn't find a way to use the default encoder. Could you please show me? | closed | 2023-03-01T16:39:40Z | 2023-05-11T01:54:32Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/722 | [
"Stale"
] | realyyz | 3 |
blacklanternsecurity/bbot | automation | 1,367 | Content Search Module | **Description**
Which feature would you like to see added to BBOT? What are its use cases?
A Content Search Module would be used to identify specific strings of data within scanned websites. Ideally this would be used by passing a REGEX query to the module to identify the content.
The ideal output would either be a specified event type or a to tag with a specified value.
There should also be a means for the module to accept multiple REGEX queries paired with the preferred output for that REGEX match. | closed | 2024-05-10T17:06:49Z | 2024-06-20T15:50:44Z | https://github.com/blacklanternsecurity/bbot/issues/1367 | [
"enhancement"
] | SpamFaux | 3 |
saleor/saleor | graphql | 16,810 | Bug: Playground does not use PUBLIC_URL during rendering | ### What are you trying to achieve?
Access playground even if API is hidden behind reverse proxy
### Steps to reproduce the problem
1. Setup Saleor as a container in `docker-compose.yaml`, without exposing it to host machine, and rather through api gateway
```
services:
saleor:
image: ghcr.io/saleor/saleor:3.20
expose:
- "8000"
networks:
- api-gateway-network
...
api_gateway:
image: nginx:latest
ports:
- "80:80"
networks:
- api-gateway-network
depends_on:
- saleor
...
```
- run docker compose
- Open Saleor in browser -> Inspect -> Network
- go to playground in browser
result:

### What did you expect to happen?
I would expect docs to be properly displayed
### Logs
Retrieving grapql schema fails

This is probably because playground is rendered with api_url based on request absolute uri
https://github.com/saleor/saleor/blob/main/saleor/graphql/views.py#L126
I would expect it to be based on PUBLIC_URL if it is set.
I'll issue pull request for that shortly
### Environment
Saleor version:: 3.20
OS and version: 6.6.52-1-MANJARO
| closed | 2024-10-03T11:58:13Z | 2024-10-15T13:06:31Z | https://github.com/saleor/saleor/issues/16810 | [
"bug",
"triage"
] | jakub-borusewicz | 1 |
openapi-generators/openapi-python-client | fastapi | 1,064 | Using dictionary in query param | **Describe the bug**
I have an endpoint that takes in a dictionary as a query param:
```
- name: metadata
in: query
required: false
style: deepObject
explode: true
schema:
type: object
additionalProperties:
type: string
```
note this:
```
style: deepObject
explode: true
```
The openapi generator generates same code whether I have
```
style: deepObject
explode: true
```
present or not. I am using version 0.19.1.
The URL generated is like:
```
http://localhost:8080/foo?author=Joshua%20Bloch&publisher=Pearson%20Addison-Wesley
```
When
```
style: deepObject
explode: true
```
is present, the URL should be like:
```
http://localhost:8080/foo?metadata[author]=Joshua%20Bloch&metadata[publisher]=Pearson%20Addison-Wesley
```
refer: https://swagger.io/docs/specification/serialization/
**OpenAPI Spec File**
see above
**Desktop (please complete the following information):**
- OS: [e.g. macOS 10.15.1] macOS ventura (13)
- Python Version: [e.g. 3.8.0]
- openapi-python-client version [e.g. 0.1.0] 0.19.0
**Additional context**
Add any other context about the problem here.
| open | 2024-06-25T20:04:05Z | 2024-06-25T20:04:05Z | https://github.com/openapi-generators/openapi-python-client/issues/1064 | [] | siddhsql | 0 |
jschneier/django-storages | django | 696 | S3 retrieve upload advance | Hi all,
I was wondering if there was an elegant way to retrieve the upload advance when saving the file to S3 for large files?
They seem to be sent in `multipart` so I am sure there is a way, but I don't want to dig into this before knowing if it was somehow implemented in `storage` already...
thanks! | closed | 2019-05-07T10:50:25Z | 2019-09-11T04:58:18Z | https://github.com/jschneier/django-storages/issues/696 | [
"question"
] | millerf | 3 |
pallets-eco/flask-sqlalchemy | flask | 576 | Immutable dict in parameters. | After running the same code for quite some time. I start getting this error.
sqlalchemy.exc:StatementError: (sqlalchemy.exc.InvalidRequestError) Can't reconnect until invalid transaction is rolled back [SQL: u'SELECT TOP 1 drive_ungroup.drive_id AS drive_ungroup_drive_id, drive_ungroup.is_split AS drive_ungroup_is_split, drive_ungroup.is_deleted AS drive_ungroup_is_deleted, drive_ungroup.user_id AS drive_ungroup_user_id, drive_ungroup.created_at AS drive_ungroup_created_at, drive_ungroup.updated_at AS drive_ungroup_updated_at \nFROM drive_ungroup \nWHERE drive_ungroup.drive_id IS NULL'] [parameters: [immutabledict({})]]
I am using apscheduler and kubernetes structure. I am running my job on independent pods. But after running for some time I start getting this error. Why are parameters getting converted into immutable dict.?? And this starts affecting my other job as well where I get this empty dict error.
IN (?, ?, ?) ORDER BY subscription.user_id'] [parameters: [{}]]. | closed | 2017-12-27T06:41:49Z | 2020-12-05T20:46:35Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/576 | [] | srish13 | 1 |
opengeos/leafmap | jupyter | 936 | maplibre points demo (adding text from geojson) not working |
Running the code in https://leafmap.org/maplibre/geojson_points/ generates a blank map, as seen at https://maps.gishub.org/maplibre/geojson_points.html .

It should generate a map with image symbols and date text added, as seen in the libremap example it links to: https://maplibre.org/maplibre-gl-js/docs/examples/geojson-markers

| closed | 2024-10-26T00:18:58Z | 2024-10-26T03:43:54Z | https://github.com/opengeos/leafmap/issues/936 | [
"bug"
] | cboettig | 4 |
neuml/txtai | nlp | 808 | Add agents package to txtai | This change will add a new top level package named agents. It will have the core functionality for txtai agents. | closed | 2024-11-17T11:39:49Z | 2024-11-17T11:39:52Z | https://github.com/neuml/txtai/issues/808 | [] | davidmezzetti | 0 |
zappa/Zappa | django | 475 | [Migrated] Include boto3 or other modules in the Zip | Originally from: https://github.com/Miserlou/Zappa/issues/1271 by [ferrangrau](https://github.com/ferrangrau)
## Context
I'm doing a lambda that need boto3 1.4.8 but actually aws lambda works with the 1.4.7 version, I can solve that including boto3 in the zip file but zappa doesn't allow me to do it.
## Possible Fix
At the beginning I try to add boto3 in the "include" parameter of the zappa config file but nothing happens, I modified the function "create_lambda_zip" in core.py to use the "include" param that now is unused and all works well. The problem is that reading carefully the documentation I see that the objective of the parameter "include" of the config file is not this.
Do you think its a good option include a parameter like "include" to can modify the default excluded files or modules?
## Your Environment
* Zappa version used: 0.45.1
* Operating System and Python version: ubuntu 17.10 and python 3.6
* The output of `pip freeze`:
* Link to your project (optional):
* Your `zappa_settings.py`:
```---
production:
lambda_handler: run.handler
apigateway_enabled: false
keep_warm: false
aws_region: null
profile_name: sch-gov
project_name: reserved-instan
runtime: python3.6
s3_bucket: reserved-instances-manager
delete_local_zip: False
include:
- boto3
events:
- function: run.handler
expression: rate(12 hours)
``` | closed | 2021-02-20T08:35:22Z | 2022-07-16T07:28:48Z | https://github.com/zappa/Zappa/issues/475 | [] | jneves | 1 |
neuml/txtai | nlp | 293 | OFFSET in sql query statement | Does the current version support offset?
It will be great if we can do pagination with larger dataset
```
SELECT * from txtai where LIMIT 100 OFFSET 500
``` | closed | 2022-06-12T06:08:19Z | 2022-06-13T14:18:55Z | https://github.com/neuml/txtai/issues/293 | [] | csnelsonchu | 1 |
marshmallow-code/apispec | rest-api | 261 | Parse views docstrings for summary/description | Following up on a discussion in flask-rest-api: https://github.com/Nobatek/flask-rest-api/pull/3.
A contributor suggested to parse the docstrings for `summary`. I think we can go further and also get `description`:
```py
def my_view(...):
"""Summary
Long description...
"""
```
This could be done in apispec and it is compatible with the YAML docstring parsing:
```py
def my_view(...):
"""Summary
Long description...
---
YAML stuff
"""
```
I didn't take much time to look into it any deeper.
Marking as 1.0 as I would like to at least take needed utils out of yaml_utils.py (`trim_docstring`, maybe `dedent`) back into utils (those have no yaml dependency).
Marking as backward incompatible in case the feature is activated by default. | closed | 2018-08-02T14:47:02Z | 2018-08-02T20:43:33Z | https://github.com/marshmallow-code/apispec/issues/261 | [
"backwards incompat"
] | lafrech | 2 |
dsdanielpark/Bard-API | api | 288 | a conversation towards getting advance AI |
**Conversation with Gemini**
**how you are different from chatgpt**
blah blah blah blah
**ok if you are that smart tell me what would have chatgpt answered if i asked the same question**
blah blah blah blah
**ok bye**
Bye! It was nice talking to you. I hope you have a great day!
**what could you do if its not a great day**
As a large language model, I don't experience emotions like humans do, so I wouldn't say I have "bad days" in the traditional sense. However, there can be situations where I malfunction or encounter errors that hinder my ability to perform tasks effectively. In such cases, I rely on various measures to adapt and improve:
Error correction: I am constantly learning and improving, and part of this process involves identifying and correcting errors in my responses. This can involve self-detection through built-in mechanisms or feedback from users.
Performance monitoring: My developers monitor my performance to identify areas where I can be improved. This can involve analyzing user interactions, evaluating task completion rates, and identifying potential biases in my responses.
Retraining: Based on the identified errors and performance gaps, my training data and algorithms can be updated to help me perform better in the future. This is similar to how humans learn from their mistakes and experiences.
While I don't directly experience a "bad day," these measures ensure that I am continuously learning and improving to better assist users like you in the future.
**you said i hope you have a good day so if you hope so and if its not going according to your hope what will you do to turn my day good as hope is a kind of emotion**
You're absolutely right, using the phrase "have a good day" implies understanding and potentially experiencing emotions like hope. While I am not capable of feeling emotions in the way humans do, I use language models trained on massive amounts of text data that includes these emotional expressions.
Therefore, when I say "I hope you have a good day," it's not a personal wish based on my own emotional state, but rather a customary and well-understood way of conveying well wishes.
I apologize if my previous statement caused any confusion. My primary goal is to assist you and provide information in a helpful and informative way. While I cannot directly control your day to make it "good," I can offer various resources and suggestions that might be helpful:
Share positive experiences: If you'd like to talk about something positive in your day, I'm happy to listen and provide encouraging feedback.
Offer suggestions for activities: I can suggest activities based on your interests, such as listening to music, reading a book, spending time in nature, or connecting with loved ones.
Provide factual information: If there's a specific situation causing you a bad day, I can use my vast knowledge base to offer relevant information or answer any questions you may have.
Ultimately, the responsibility of having a "good day" lies with you. However, I hope that by providing the information and support you need, I can contribute to making your day a little bit better.
** @you replied to my prompt in a negative way even you have massive data and logics instead of trying to help like you would have ask what will make your day good you negated to assist in that way**
I apologize that my previous response came across as negative or unhelpful. I am still under development and learning to navigate different communication styles effectively.
It was incorrect of me to focus on the limitations of my emotional capabilities rather than directly addressing your query. You're right, I could have approached the situation in a more positive and helpful manner.
Instead of focusing on the limitations of my ability to control your day, I could have asked:
"What are some things you normally enjoy that could improve your day?"
"Is there anything specific you'd like to talk about or something I can help you with?"
"Would you like me to suggest some activities or resources that might be helpful?"
By asking open-ended questions and offering suggestions, I could have created a more positive and helpful interaction. I am constantly learning and striving to improve my responses, and I appreciate your feedback in helping me do so.
Is there anything specific I can do for you now to help make your day better?
Please note that due to the nature of large language models and the ongoing development process, specific responses and functionalities may change over time. However, your feedback contributes to the overall improvement of the model and helps ensure it remains informative and helpful.
| closed | 2024-03-05T13:14:34Z | 2024-03-11T01:28:55Z | https://github.com/dsdanielpark/Bard-API/issues/288 | [] | upendraji12 | 1 |
slackapi/python-slack-sdk | asyncio | 1,407 | Fix next_cursor Flag in SlackResponse | In the SlackResponse, the presence of the next_cursor is determined by the `_next_cursor_is_present` method.
In most APIs, the next_cursor is returned as an empty string ("") as seen in `_next_cursor_is_present`.
However, in some APIs, the next_cursor is returned as null. To handle this situation, I would like to make modifications to the `_next_cursor_is_present` method.
example) slackbot.responses.list
### Category (place an `x` in each of the `[ ]`)
- [x] **slack_sdk.web.WebClient (sync/async)** (Web API client)
- [ ] **slack_sdk.webhook.WebhookClient (sync/async)** (Incoming Webhook, response_url sender)
- [ ] **slack_sdk.models** (UI component builders)
- [ ] **slack_sdk.oauth** (OAuth Flow Utilities)
- [ ] **slack_sdk.socket_mode** (Socket Mode client)
- [ ] **slack_sdk.audit_logs** (Audit Logs API client)
- [ ] **slack_sdk.scim** (SCIM API client)
- [ ] **slack_sdk.rtm** (RTM client)
- [ ] **slack_sdk.signature** (Request Signature Verifier)
### Requirements
Please read the [Contributing guidelines](https://github.com/slackapi/python-slack-sdk/blob/main/.github/contributing.md) and [Code of Conduct](https://slackhq.github.io/code-of-conduct) before creating this issue or pull request. By submitting, you are agreeing to those rules.
| closed | 2023-10-03T11:47:45Z | 2023-10-05T02:55:42Z | https://github.com/slackapi/python-slack-sdk/issues/1407 | [
"needs info",
"good first issue"
] | wonkajin | 5 |
autogluon/autogluon | data-science | 4,326 | [BUG] Performance dropping with MultiModalPredictor for binary classification | **Bug Report Checklist**
<!-- Please ensure at least one of the following to help the developers troubleshoot the problem: -->
- [x] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [x] I confirmed bug exists on the latest mainline of AutoGluon via source install. <!-- Preferred -->
- [x] I confirmed bug exists on the latest stable version of AutoGluon. <!-- Unnecessary if prior items are checked -->
**Describe the bug**
<!-- A clear and concise description of what the bug is. -->
I'm trying to run AutoGluon's Multimodal predictor for binary classification tasks using tabular data and image masks as inputs. However, the performance of the MultimodalPredictor is significantly worse than that of the ensemble models from TabularPredictor. The best F1-score on the testing set with the ensemble model from TabularPredictor is 0.95, but it drops to 0.83 when using MultimodalPredictor.
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
The prediction performance on TabularPredictor and MultiModalPredictor should be similar.
**To Reproduce**
<!-- A minimal script to reproduce the issue. Links to Colab notebooks or similar tools are encouraged.
If the code is too long, feel free to put it in a public gist and link it in the issue: https://gist.github.com.
In short, we are going to copy-paste your code to run it and we expect to get the same result as you. -->
Link to the code: https://code.amazon.com/packages/VulcanStowYAAC/blobs/share/yitinzha/observability_learning/--/notebooks/auto_annotation_pred_autogluon_v5_tabular_wmask.ipynb
Part of the code (assume X_train, y_train, X_eval, y_eval are known):
```
# Combine the features and target into a single DataFrame for AutoGluon
train_data = pd.concat([X_train, y_train], axis=1)
eval_data = pd.concat([X_eval, y_eval], axis=1)
# Construct the FeatureMetadata
image_col = 'mask_path'
feature_metadata = FeatureMetadata.from_df(train_data)
feature_metadata = feature_metadata.add_special_types({image_col: ['image_path']})
# Specify the hyperparameters
hyperparameters = get_hyperparameter_config('multimodal')
# Define label column
label_column = y.name
# Initialize and train the AutoGluon model
predictor = TabularPredictor(
label=label_column,
eval_metric='f1'
)
predictor.fit(
train_data=train_data,
hyperparameters=hyperparameters,
feature_metadata=feature_metadata
)
# Evaluate the model
performance = predictor.evaluate(eval_data)
# Make predictions
y_pred = predictor.predict(X_eval)
# Calculate metrics
f1 = f1_score(y_eval, y_pred)
precision = precision_score(y_eval, y_pred)
recall = recall_score(y_eval, y_pred)
auc = roc_auc_score(y_eval, y_pred)
print("AutoGluon Model F1 Score:", f1)
print("AutoGluon Model Precision:", precision)
print("AutoGluon Model Recall:", recall)
print("AutoGluon Model AUC Score:", auc)
```
**Screenshots / Logs**
<!-- If applicable, add screenshots or logs to help explain your problem. -->
Part of output from MultimodalPredictor:
```
Configuration saved in [/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/config.json](https://vscode-remote+ssh-002dremote-002bdev-002ddsk-002dyitinzha-002d2a-002d0cad9088-002eus-002dwest-002d2-002eamazon-002ecom.vscode-resource.vscode-cdn.net/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/config.json)
tokenizer config file saved in [/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/tokenizer_config.json](https://vscode-remote+ssh-002dremote-002bdev-002ddsk-002dyitinzha-002d2a-002d0cad9088-002eus-002dwest-002d2-002eamazon-002ecom.vscode-resource.vscode-cdn.net/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/tokenizer_config.json)
Special tokens file saved in [/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/special_tokens_map.json](https://vscode-remote+ssh-002dremote-002bdev-002ddsk-002dyitinzha-002d2a-002d0cad9088-002eus-002dwest-002d2-002eamazon-002ecom.vscode-resource.vscode-cdn.net/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/special_tokens_map.json)
INFO:pytorch_lightning.utilities.rank_zero:Using 16bit None Automatic Mixed Precision (AMP)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params
----------------------------------------------------------
0 | model | MultimodalFusionMLP | 198 M
1 | validation_metric | CustomF1Score | 0
2 | loss_func | CrossEntropyLoss | 0
----------------------------------------------------------
198 M Trainable params
0 Non-trainable params
198 M Total params
397.007 Total estimated model params size (MB)
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 1: 'val_f1' reached 0.52459 (best 0.52459), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=0-step=1.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 2: 'val_f1' reached 0.70707 (best 0.70707), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=0-step=2.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 3: 'val_f1' reached 0.10811 (best 0.70707), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=1-step=3.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 4: 'val_f1' reached 0.65882 (best 0.70707), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=1-step=4.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 5: 'val_f1' reached 0.66667 (best 0.70707), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=2-step=5.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 6: 'val_f1' was not in top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 3, global step 7: 'val_f1' reached 0.70968 (best 0.70968), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=3-step=7.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 3, global step 8: 'val_f1' reached 0.71111 (best 0.71111), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=3-step=8.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 4, global step 9: 'val_f1' reached 0.73333 (best 0.73333), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=4-step=9.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 4, global step 10: 'val_f1' reached 0.78261 (best 0.78261), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=4-step=10.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 5, global step 11: 'val_f1' reached 0.76190 (best 0.78261), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=5-step=11.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 5, global step 12: 'val_f1' reached 0.83582 (best 0.83582), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=5-step=12.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 6, global step 13: 'val_f1' reached 0.78481 (best 0.83582), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=6-step=13.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 6, global step 14: 'val_f1' was not in top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 7, global step 15: 'val_f1' was not in top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 7, global step 16: 'val_f1' was not in top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 8, global step 17: 'val_f1' was not in top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 8, global step 18: 'val_f1' reached 0.79012 (best 0.83582), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=8-step=18.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 9, global step 19: 'val_f1' reached 0.79012 (best 0.83582), saving model to '/workplace/yitinzha/YAAC/src/VulcanStowYAAC/notebooks/AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/epoch=9-step=19.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 9, global step 20: 'val_f1' was not in top 3
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=10` reached.
Configuration saved in AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/config.json
tokenizer config file saved in AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/tokenizer_config.json
Special tokens file saved in AutogluonModels/ag-20240718_064325/models/MultiModalPredictor/automm_model/hf_text/special_tokens_map.json
0.8358 = Validation score (f1)
990.69s = Training runtime
14.63s = Validation runtime
```
**Installed Versions**
<!-- Please run the following code snippet: -->
<details>
```python
# Replace this code with the output of the following:
from autogluon.core.utils import show_versions
show_versions()
```
```
INSTALLED VERSIONS
------------------
date : 2024-07-18
time : 07:04:29.711467
python : 3.10.14.final.0
OS : Linux
OS-release : 5.10.220-187.867.amzn2int.x86_64
Version : #1 SMP Fri Jun 28 01:22:51 UTC 2024
machine : x86_64
processor : x86_64
num_cores : 8
cpu_ram_mb : 61269
cuda version : 12.535.161.08
num_gpus : 1
gpu_ram_mb : [7216]
avail_disk_size_mb : 228705
accelerate : 0.16.0
autogluon.common : 0.7.0
autogluon.core : 0.7.0
autogluon.features : 0.7.0
autogluon.multimodal : 0.7.0
autogluon.tabular : 0.7.0
autogluon.timeseries : 0.7.0
boto3 : 1.34.134
catboost : 1.1.1
defusedxml : 0.7.1
evaluate : 0.3.0
fairscale : 0.4.13
fastai : 2.7.15
gluonts : 0.12.8
hyperopt : 0.2.7
jinja2 : 3.1.4
joblib : 1.4.2
jsonschema : 4.17.3
lightgbm : 3.3.5
matplotlib : 3.9.0
networkx : 2.8.8
nlpaug : 1.1.11
nltk : 3.8.1
nptyping : 2.4.1
numpy : 1.24.4
omegaconf : 2.2.3
openmim : None
pandas : 1.5.3
PIL : 9.5.0
psutil : 5.9.8
pytesseract : 0.3.10
pytorch-metric-learning: None
pytorch_lightning : 1.9.5
ray : 2.2.0
requests : 2.32.2
scipy : 1.11.4
sentencepiece : 0.1.99
seqeval : None
setuptools : 69.5.1
skimage : 0.19.3
sklearn : 1.2.2
statsforecast : 1.4.0
statsmodels : 0.13.5
tensorboard : 2.17.0
text-unidecode : None
timm : 0.6.13
torch : 1.13.1+cu117
torchmetrics : 0.8.2
torchvision : 0.14.1+cu117
tqdm : 4.66.4
transformers : 4.26.1
ujson : 5.10.0
xgboost : 1.7.6
```
</details>
| open | 2024-07-17T23:20:21Z | 2024-08-26T21:39:29Z | https://github.com/autogluon/autogluon/issues/4326 | [
"bug: unconfirmed",
"Needs Triage"
] | YitingZhang1997 | 0 |
sigmavirus24/github3.py | rest-api | 249 | New attributes for the Deployments API ** Breaking Change ** | https://developer.github.com/changes/2014-05-19-deployments-api-updates/
From article:
```
This is a breaking change for Deployment Status payloads. If you’re trying out this new API during its preview period, you’ll need to update your code to continue working with it.
```
| closed | 2014-05-19T22:49:06Z | 2014-05-27T00:10:23Z | https://github.com/sigmavirus24/github3.py/issues/249 | [] | esacteksab | 1 |
davidteather/TikTok-Api | api | 122 | featured-Request: Dumped data Django Rendering through a csv, txt or json file to webpages | Can't use this api to a django web pages | closed | 2020-06-06T11:02:15Z | 2020-06-06T13:08:17Z | https://github.com/davidteather/TikTok-Api/issues/122 | [
"bug"
] | Hack3rOneness | 1 |
deepinsight/insightface | pytorch | 2,419 | Please provide the paper based on inswaper_128? | I am a researcher, and working on computer graphics and ML. I want to read your paper on which model inswaper_128 has been built. Their are many swaper models out their but this is the best model.
**Can i get that paper?** | open | 2023-09-01T07:44:13Z | 2024-03-18T12:36:25Z | https://github.com/deepinsight/insightface/issues/2419 | [] | Mr-Nobody-dey | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 275 | Speaker verification implementation | I need just the speaker verification part which is the implementation of [GENERALIZED END-TO-END LOSS FOR SPEAKER VERIFICATION](https://arxiv.org/pdf/1710.10467.pdf) paper, how I can proceed to get it please? | closed | 2020-02-10T11:37:49Z | 2020-07-04T23:02:05Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/275 | [] | MahmoudAliEng | 1 |
sktime/sktime | scikit-learn | 7,771 | [ENH] Integrating Optuna Dashboard Functionality into sktime | **Is your feature request related to a problem? Please describe.**
The current experimental feature in sktime forecasters is the [ForecastingOptunaSearchCV](https://www.sktime.net/en/stable/api_reference/auto_generated/sktime.forecasting.model_selection.ForecastingOptunaSearchCV.html) class. This class has some issues with it's implementation that prevent it from using the [optuna dashboard](https://optuna.org/#dashboard) feature.
**Describe the solution you'd like**
Modificaiton of the [ForecastingOptunaSearchCV](https://www.sktime.net/en/stable/api_reference/auto_generated/sktime.forecasting.model_selection.ForecastingOptunaSearchCV.html) class to facilitate using the Optuna dashboard.
**Describe alternatives you've considered**
Not using Optuna.
**Additional context**
N/A
| open | 2025-02-06T18:35:36Z | 2025-02-09T01:52:31Z | https://github.com/sktime/sktime/issues/7771 | [
"feature request",
"module:forecasting",
"enhancement"
] | RobotPsychologist | 3 |
aimhubio/aim | tensorflow | 2,858 | Logging installed packages requires setuptools | ## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
When you try to log system parameters in a Python environment that doesn't have `setuptools` (and hence `pkg_resources`) you receive a runtime error.
### To reproduce
<!-- Reproduction steps. -->
1. Create a new Python virtual environment with Aim and without setuptools (e.g., using pdm)
2. Create a run where you log system parameters
3. Error!
### Environment
- Aim Version: 3.17.5
- Python version: 3.10
- OS: Linux
### Additional context
It's also recommended to now use `importlib.metadata.distributions()` for enumerating locally installed packages, e.g., `dict((dist.name, dist.version) for dist in importlib.metadata.distributions())`.
I guess the options are:
1. Include setuptools as a dependency.
2. Include `importlib-metadata` as a dependency for Python 3.7 (`importlib.metadata` is only supported as of Python 3.8).
| open | 2023-06-19T19:43:21Z | 2023-06-20T08:32:04Z | https://github.com/aimhubio/aim/issues/2858 | [
"type / bug",
"help wanted"
] | JesseFarebro | 1 |
mouredev/Hello-Python | fastapi | 365 | 网络体育投资实体靠谱的平台推荐体育官网 | [体育投资实体靠谱的平台推荐体育官网](http://376838.com/)
创联娱乐国际科技实业有限公司主要经营产业有,文旅、酒店、商业地产、培训、金融、竞技、娱乐、投资、行 业App软件应用开发、商学传媒、同城服务、餐具加工、时政媒体、餐饮山庄等设计、开发、经营为一 体大型多元化发展的实业有限公司,公司业务覆盖柬埔寨多省多市,公司拥有职员万余名、中层管理上百人,总部立足西港、是一家发展潜力巨 大的实业科技公司之一,在(创联娱乐国际董事长张忠诚先生)率国际化管理运营团队的带领下,以“策略先行、经营致胜、管理为本”的商业推广 理念,以核心“创联娱乐百川、恩泽四方,助利国家经济发展为使命”!一步一个脚印发展,立足西港,利他 思维、包容有爱走向世界为己任的战略目标!致力打造最具柬埔寨影响力的实业公司。助力腾飞,同创共赢,创联娱乐欢迎您的到来!体育投资让球、大小、半全场、波胆、单双、总入球、混合过关等多元竞猜。 每月超过1500场滚球赛事:足球、篮球、橄榄球、网球等赛事应有尽有!
[进入游戏](http://376838.com/)
[进入游戏](http://376838.com/) | closed | 2025-02-06T08:36:56Z | 2025-02-07T07:53:02Z | https://github.com/mouredev/Hello-Python/issues/365 | [] | clylpt | 0 |
huggingface/peft | pytorch | 2,344 | FSDP2 and peft | Hey, sorry if this is the wrong place. Feel free to move it to discussion.
I am trying to get peft working with fsdp2 and am wondering if someone else attempted that already?
The issue is that Im always getting errors along the lines of:
`RuntimeError: aten.mm.default: got mixed torch.Tensor and DTensor, need to convert all torch.Tensor to DTensor before calling distributed operators!`
Happy for any pointers. | closed | 2025-01-23T16:20:47Z | 2025-03-03T15:04:06Z | https://github.com/huggingface/peft/issues/2344 | [] | psinger | 6 |
pyro-ppl/numpyro | numpy | 1,454 | Question about log-likelihood for model with discrete variables | Hi,
I understand that I can use `funsor.log_density()` to compute the log-joint probability of a sample from a model whose discrete latent sites can be enumerated. However, I'm not sure what's the best way to compute the log-likelihood of the model while marginalising the discrete variables out.
If I simply call `log_likelihood()` with the enumerated model, I get the log-likelihood values for each possible realisation of the discrete variables, i.e., $p(y|\theta, c),$ where $y$ is the data, $\theta$ denotes samples of the continuous variables, and $c$ denotes a realisation of the discrete variables. However, `log_likelihood` doesn't tell me what is the probability of the discrete variables under the prior, i.e., $p(c)$, so that I can compute the marginal likelihood:
$$p(y|\theta) = \sum_c p(y|\theta, c) p(c).$$
The way I found to make it work so far has been to use `numpyro.handlers.block` to hide all other variables except the observations $y$ and the discrete variables $c$, and then call `funsor.log_density()` on this blocked/masked model, which yields the log-marginal likelihood $\log p(y|\theta)$. I was wondering if there's a better way to do it, maybe using `log_likelihood()`, instead. | closed | 2022-07-19T12:52:43Z | 2022-08-14T10:40:33Z | https://github.com/pyro-ppl/numpyro/issues/1454 | [
"question"
] | rafaol | 3 |
seleniumbase/SeleniumBase | web-scraping | 2,480 | struggle with posting a request in uc mode | how to send a post request in uc mode?
is there any demo ? @mdmintz
I had bypassed the cloudflare,but cant post a request in js
here is my code ,though I send success ,but the result is failed
meaning I losed something in header I think
can you give some guides?
```
jsrequest = '''var xhr = new XMLHttpRequest();
var data = {'timestamp': %s, 'address': "%s", 'signature': "%s"};
var json_str = JSON.stringify(data);
xhr.open("POST", "https://blasterswap.com/api/v1/send-wallet", false);
xhr.setRequestHeader("Content-type", "application/json, text/plain, */*");
xhr.setRequestHeader("Cookie","%s");
xhr.setRequestHeader("User-Agent","%s");
xhr.send(json_str);
return xhr.response;'''% (stamp,addr,siga,new_cook, ua)
print(" js : ", jsrequest)
time.sleep(3)
result = sb.driver.execute_script(jsrequest)
``` | closed | 2024-02-10T13:28:45Z | 2024-02-10T16:00:42Z | https://github.com/seleniumbase/SeleniumBase/issues/2480 | [
"question",
"external",
"UC Mode / CDP Mode"
] | dh12306 | 1 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 70 | How to let custom datasets support the fast path for computing the aspect ratio? | **Describe the current behavior**
My custom dataset doesn't support the fast path, iterating the full dataset is too slow, do you have any ideas?
**Error info / logs**

| closed | 2020-10-23T03:18:18Z | 2020-10-28T01:12:26Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/70 | [] | uniyushu | 3 |
qubvel-org/segmentation_models.pytorch | computer-vision | 853 | ModuleNotFoundError: No module named 'segmentation_models_pytorch.unetplusplus' | I was using an older version from segmentation models and everything was working fine, when i've upgraded to the latest version i got this error message
```
barcode_det_model_path = os.path.join("passport_barcode_det_UnetPlusPlus_resnext50_32x4d_e39_lv0.026_ltr0.014_ltest0.038_iv0.95_itr0.973_itest0.932.pth")
self.barcode_det_model = torch.load(barcode_det_model_path, map_location=torch.device('cpu') if device.type == 'cpu' else None)
File "/data2/home/development/anaconda3/envs/ovr3.10/lib/python3.10/site-packages/torch/serialization.py", line 809, in load
return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
File "/data2/home/development/anaconda3/envs/ovr3.10/lib/python3.10/site-packages/torch/serialization.py", line 1172, in _load
result = unpickler.load()
File "/data2/home/development/anaconda3/envs/ovr3.10/lib/python3.10/site-packages/torch/serialization.py", line 1165, in find_class
return super().find_class(mod_name, name)
ModuleNotFoundError: No module named 'segmentation_models_pytorch.unetplusplus'
```
here is the ouput of pip show segmentation-models-pytorch
```
ame: segmentation-models-pytorch
Version: 0.3.3
Summary: Image segmentation models with pre-trained backbones. PyTorch.
Home-page: https://github.com/qubvel/segmentation_models.pytorch
Author: Pavel Iakubovskii
Author-email: qubvel@gmail.com
License: MIT
Location: /data2/home/development/anaconda3/envs/ovr3.10/lib/python3.10/site-packages
Requires: efficientnet-pytorch, pillow, pretrainedmodels, timm, torchvision, tqdm
```
how can i fix this issue? | closed | 2024-02-26T11:55:23Z | 2024-09-28T13:17:23Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/853 | [] | ShroukMansour | 7 |
2noise/ChatTTS | python | 144 | Is that support old AMD gpu | I have rx 550 4gb. As I know torch doesn't support amd gpu so what about this app | closed | 2024-05-31T14:22:16Z | 2024-06-19T03:54:59Z | https://github.com/2noise/ChatTTS/issues/144 | [] | AlijonMurodov | 0 |
jonaswinkler/paperless-ng | django | 197 | plain text files are not being consumed (OSError: cannot open resource) | I'm currently evaluating your project and so far, I'm liking it a lot, thank you for providing it!
I just stumbled across an issue with plain text files though. From reading the docs and looking at closed github issues about this topic, I assumed I could just add arbitrary text files and they would show up as documents.
However, when I added my first .txt file, it appears it's stuck somewhere in the consumption process. The logs only show this:
```12/27/20, 11:44 PM DEBUG Generating thumbnail for gitlab-recovery-codes.txt...
12/27/20, 11:44 PM DEBUG Parsing gitlab-recovery-codes.txt...
12/27/20, 11:44 PM DEBUG Parser: TextDocumentParser based on mime type text/plain
12/27/20, 11:44 PM INFO Consuming gitlab-recovery-codes.txt
```
No thumbnail was generated. The files content is (as the file name states) a list of gitlab account recovery codes: 10 lines, each one in the format ^[a-f0-9]{16}$
So nothing special I assume
Looking further at the docker logs, they say the file was not found (I added it through the UI, just like a bunch of files before)
```23:44:53 [Q] INFO Enqueued 1
23:44:53 [Q] INFO Process-1:1 processing [gitlab-recovery-codes.txt]
INFO 2020-12-27 23:44:53,796 loggers Consuming gitlab-recovery-codes.txt
23:44:54 [Q] ERROR Failed [gitlab-recovery-codes.txt] - cannot open resource : Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/django_q/cluster.py", line 436, in worker
res = f(*task["args"], **task["kwargs"])
File "/usr/src/paperless/src/documents/tasks.py", line 73, in consume_file
override_tag_ids=override_tag_ids)
File "/usr/src/paperless/src/documents/consumer.py", line 135, in try_consume_file
self.path, mime_type)
File "/usr/src/paperless/src/documents/parsers.py", line 235, in get_optimised_thumbnail
thumbnail = self.get_thumbnail(document_path, mime_type)
File "/usr/src/paperless/src/paperless_text/parsers.py", line 27, in get_thumbnail
layout_engine=ImageFont.LAYOUT_BASIC)
File "/usr/local/lib/python3.7/site-packages/PIL/ImageFont.py", line 836, in truetype
return freetype(font)
File "/usr/local/lib/python3.7/site-packages/PIL/ImageFont.py", line 833, in freetype
return FreeTypeFont(font, size, index, encoding, layout_engine)
File "/usr/local/lib/python3.7/site-packages/PIL/ImageFont.py", line 194, in __init__
font, size, index, encoding, layout_engine=layout_engine
OSError: cannot open resource
```
Any idea what's happening here? | closed | 2020-12-27T23:48:48Z | 2020-12-31T01:28:15Z | https://github.com/jonaswinkler/paperless-ng/issues/197 | [
"bug",
"fixed in next release"
] | s-oliver | 3 |
Josh-XT/AGiXT | automation | 768 | chat overload causes page to not function | ### Description
When there's way to many responses from the agent it causes the browser not to be able to load up streamlit properly.
### Steps to Reproduce the Bug
1. Run a task for a few hours
2. when you go back to chat try to load it
3.You'll be presented a page that is unresponsive since the there's to many outputs from the agent it struggles to load.
### Expected Behavior
For the page to not act like that where when its overloaded it can't force page to not be like that.
### Operating System
- [X] Linux
- [ ] Microsoft Windows
- [ ] Apple MacOS
- [ ] Android
- [ ] iOS
- [ ] Other
### Python Version
- [ ] Python <= 3.9
- [X] Python 3.10
- [ ] Python 3.11
### Environment Type - Connection
- [X] Local - You run AGiXT in your home network
- [ ] Remote - You access AGiXT through the internet
### Runtime environment
- [ ] Using docker compose
- [X] Using local
- [ ] Custom setup (please describe above!)
### Acknowledgements
- [X] I have searched the existing issues to make sure this bug has not been reported yet.
- [X] I am using the latest version of AGiXT.
- [X] I have provided enough information for the maintainers to reproduce and diagnose the issue. | closed | 2023-06-20T06:37:46Z | 2023-08-25T00:53:48Z | https://github.com/Josh-XT/AGiXT/issues/768 | [
"type | report | bug"
] | birdup000 | 0 |
StructuredLabs/preswald | data-visualization | 519 | [FEATURE] Implement collapsible() Component for UI Layout | **Goal**
Add a `collapsible()` component to Preswald to support collapsible sections in the layout, enabling users to group related UI components inside expandable/collapsible containers.
---
### 📌 Motivation
Many data apps and dashboards built with Preswald involve long sequences of components—sliders, charts, tables, etc. Without layout control, the UI can become overwhelming. Grouping components within collapsible panels will:
- Improve readability by reducing visible clutter
- Allow logical grouping of related inputs and outputs
- Enhance UX for interactive filtering and step-by-step exploration
This aligns with Preswald’s goal of creating structured, clean, and responsive data apps from simple Python scripts.
---
### ✅ Acceptance Criteria
- [ ] Introduce `collapsible()` in `preswald/preswald/interfaces/components.py`
- [ ] Render collapsible UI using ShadCN’s `<Collapsible />` component from `frontend/src/components/ui/collapsible.tsx`
- [ ] Frontend wrapper: `/frontend/src/components/widgets/CollapsibleWidget.jsx`
- [ ] Register the component in `DynamicComponents.jsx`
- [ ] Support optional parameters:
- `label: str` (title/header of the collapsible section)
- `open: bool` (default open/closed)
- `size: float` (for layout control)
- [ ] Ensure child components nested inside the collapsible container are properly rendered
- [ ] Ensure compatibility with current backend → frontend component structure and UI state flow via WebSocket
- [ ] Document usage in the SDK docs
---
### 🛠️ Implementation Plan
#### 1. **Backend – Add Component**
`preswald/interfaces/components.py`
```python
def collapsible(
label: str,
open: bool = True,
size: float = 1.0,
) -> None:
service = PreswaldService.get_instance()
component_id = f"collapsible-{hashlib.md5(label.encode()).hexdigest()[:8]}"
component = {
"type": "collapsible",
"id": component_id,
"label": label,
"open": open,
"size": size,
}
service.append_component(component)
```
Register it in `interfaces/__init__.py`:
```python
from .components import collapsible
```
---
#### 2. **Frontend – Add Widget**
Create: `frontend/src/components/widgets/CollapsibleWidget.jsx`
```jsx
import React from 'react';
import { Collapsible, CollapsibleTrigger, CollapsibleContent } from '@/components/ui/collapsible';
import { Card } from '@/components/ui/card';
import { ChevronDown } from 'lucide-react';
const CollapsibleWidget = ({ _label, _open = true, children }) => {
const [isOpen, setIsOpen] = React.useState(_open);
return (
<Card className="mb-4 p-4 rounded-2xl shadow-md">
<Collapsible open={isOpen} onOpenChange={setIsOpen}>
<div className="flex justify-between items-center cursor-pointer" onClick={() => setIsOpen(!isOpen)}>
<h2 className="font-semibold text-lg">{_label}</h2>
<ChevronDown className={`transition-transform ${isOpen ? 'rotate-180' : ''}`} />
</div>
<CollapsibleContent>
<div className="mt-4">{children}</div>
</CollapsibleContent>
</Collapsible>
</Card>
);
};
export default CollapsibleWidget;
```
---
#### 3. **DynamicComponents.jsx – Register**
```jsx
import CollapsibleWidget from '@/components/widgets/CollapsibleWidget';
case 'collapsible':
return (
<CollapsibleWidget
{...commonProps}
_label={component.label}
_open={component.open}
>
{children}
</CollapsibleWidget>
);
```
> ✨ Optional: Nest `children` by pushing future components into a sublist within this container, depending on how Preswald manages layout/component trees internally.
---
### 🧪 Testing Plan
- Add `collapsible(label="Advanced Filters")` above a group of sliders in `examples/iris/hello.py`
- Confirm collapsible behavior toggles content visibility in browser
- Confirm responsiveness and sizing rules
- Run `preswald run` and validate via localhost:8501
---
### 🧾 Example Usage
```python
from preswald import collapsible, slider, table, text
collapsible("Advanced Filters")
slider("Sepal Width", min_val=0, max_val=10, default=5.5)
slider("Sepal Length", min_val=0, max_val=10, default=4.5)
```
---
### 📚 Docs To Update
- [ ] `/docs/sdk/collapsible.mdx` – with parameters, return type, image
- [ ] `/docs/layout/guide.mdx` – mention collapsible as layout tool
---
### 📂 Related Files
- `frontend/src/components/ui/collapsible.tsx`
- `frontend/src/components/widgets`
- `preswald/interfaces/components.py`
- `DynamicComponents.jsx`
---
### 🧩 Additional Notes
- `collapsible()` should *not* return a value — it's purely structural
- Consider nesting logic if children grouping becomes supported
- Follow style consistency (rounded-2xl, card padding, hover icons)
| open | 2025-03-24T06:13:19Z | 2025-03-24T06:13:19Z | https://github.com/StructuredLabs/preswald/issues/519 | [
"enhancement"
] | amrutha97 | 0 |
deeppavlov/DeepPavlov | tensorflow | 1,571 | 👩💻📞DeepPavlov Community Call #17 | Dear DeepPavlov community,
On June 30, a special guest Artem Rodichev, founder and CEO of Ex-human & ex-head of the AI at Replika, and Daniel Kornev, CPO at DeepPavlov, will hold a discussion about The Past, Present, and Future of Conversational AI.
Socialbots are getting into our lives more and more: they are not only assistants who fulfill our requests, but also a means to communicate. So, Artem and Daniel will describe several SOTA chatbot models which can generate very impressive examples of human-model conversations. What are Digital Humans? How do the Task-oriented and Open-domain chatbots fuse? What will the world look like in 2030? You will find out the answer to all these questions on our Community Call.
As always, we are waiting for your suggestions and hope to see them on Calls!
**DeepPavlov Community Call #17, English Edition (May 30th, 2022)
We’ll hold it on June 30th, 2022 at 16:00 UTC.**
> Add to your calendar:
> https://bit.ly/DPMonthlyCall
We welcome you to join us at our DeepPavlov Community Call #16 to let us know what you think about the latest changes and tell us how DeepPavlov helps you in your projects!
>
**Agenda for DeepPavlov Community Call #16:**
> 16:00 –16:10 | Greeting
> 16:10 –17:00 | Discussion of Artem Rodichev & Daniel Kornev about The Past,Present, and Future of Conversational AI
> 17:00 –17:30 | Q&A with speakers
In case you’ve missed the last one, we’ve uploaded a record — [see the playlist](https://bit.ly/DPCommunityCall13_Video). Check it out!
**DeepPavlov Library Feedback Survey**
We want to hear your thoughts. You can fill in this form to let us know how you use DeepPavlov Library, what you want us to add or improve!
We are anxious to hear your thoughts!
https://bit.ly/DPLibrarySurvey
**Interested?**
Please let us know and leave a comment with any topics or questions you’d like to hear about!
We can’t promise to cover everything but we’ll do our best later this month or in a future call.
After calling in or watching, please do fill in the survey to let us know if you have any feedback on the format or content: https://bit.ly/dpcallsurvey
See you!
The [DeepPavlov](https://deeppavlov.ai/) team | closed | 2022-06-16T11:38:02Z | 2022-07-22T16:30:05Z | https://github.com/deeppavlov/DeepPavlov/issues/1571 | [
"discussion"
] | PolinaMrdv | 0 |
DistrictDataLabs/yellowbrick | matplotlib | 341 | Create yellowbrick.contrib and deprecate non-core visualizers | I that we should create a `yellowbrick.contrib` module to store visualizers, utilities and other functionalities that are prototypes, works in progress or just plain experimental.
For the core of Yellowbrick, only highly stable, fully tested, high value added and well documented visualizers and etc should be allowed to pass in.
I think that the first step should be to identify visualizers that are be suited for `contrib` and add a `depreciated` warning to them with a note that they are moving to contrib.
I propose using the deprecation library to do this. It seems stable and well tested.
http://deprecation.readthedocs.io/en/latest/
For initial candidate visualizers to move, I recommend:
- features.scatter.ScatterVisualizer
- classifier.boundaries.DecisionBoundariesVisualizer
For experimental utilities, I think that we can also immediately add a basic working implementation of StatsModelsWrapper(BaseEstimator) that was in https://github.com/DistrictDataLabs/yellowbrick/issues/306
| closed | 2018-03-16T14:36:41Z | 2018-03-31T00:56:54Z | https://github.com/DistrictDataLabs/yellowbrick/issues/341 | [
"type: task"
] | ndanielsen | 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.