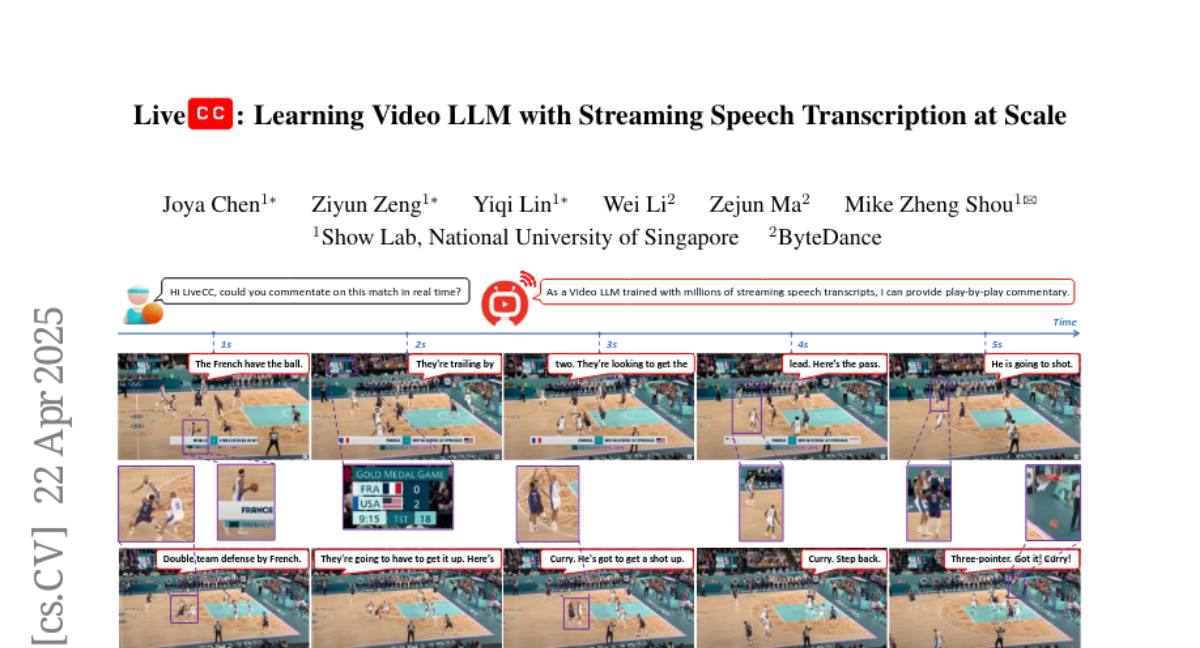
Learning Video LLM with Streaming Speech Transcription at Scale (CVPR 2025)

Joya Chen
chenjoya
AI & ML interests
Video LLM
Recent Activity
upvoted a paper 18 days ago
Parallelized Autoregressive Decoding for Omni-Modal Dense Video Captioning upvoted a paper 23 days ago
Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity upvoted a paper about 1 month ago
Data Journalist Agent: Transforming Data into Verifiable Multimodal StoriesOrganizations