
NVIDIA EGM
Collection
Efficient Grounding Models • 4 items • Updated • 8
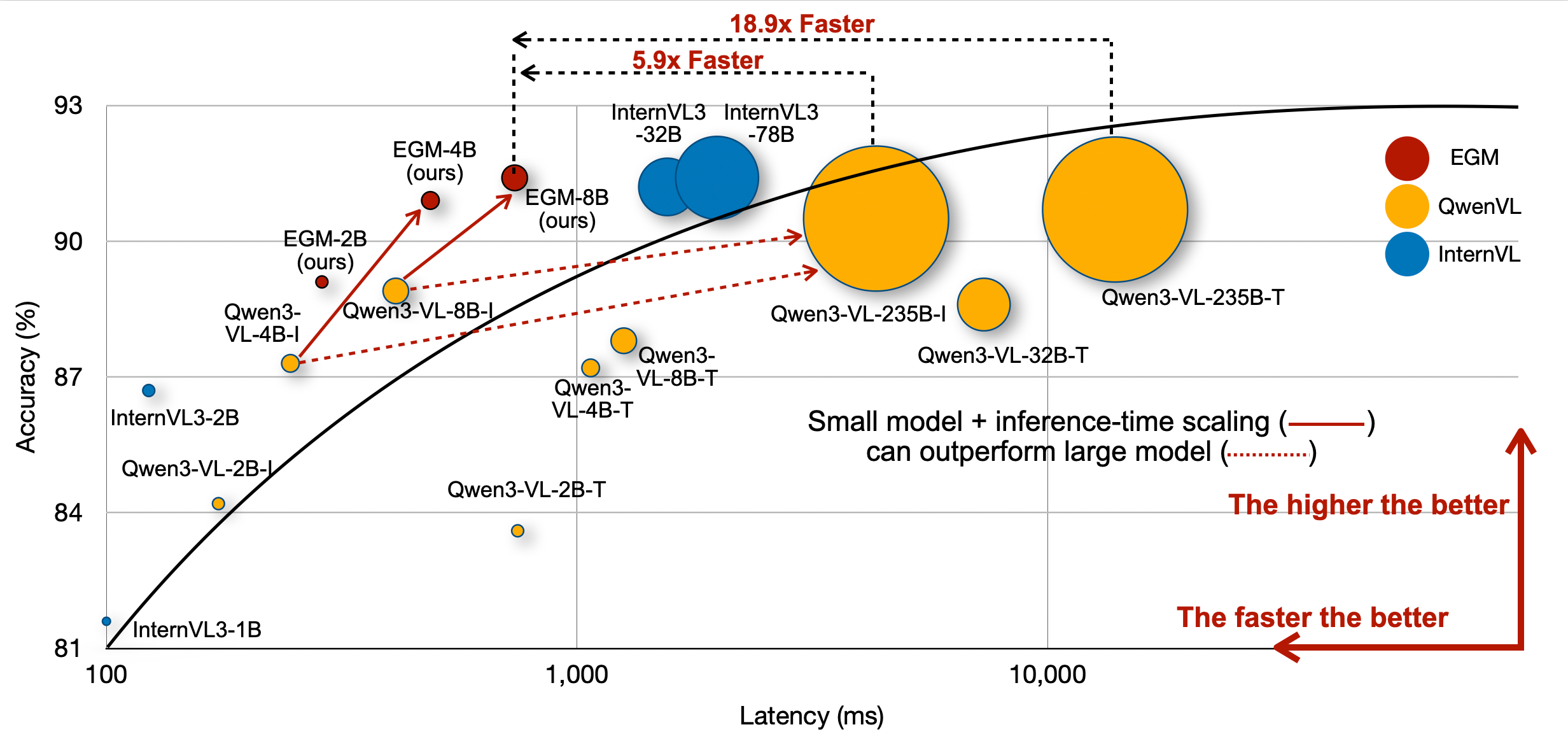
EGM-Qwen3-VL-4B is an efficient visual grounding model from the EGM (Efficient Visual Grounding Language Models) family. It is built on top of Qwen3-VL-4B-Thinking and trained with a two-stage pipeline: supervised fine-tuning (SFT) followed by reinforcement learning (RL) using GRPO (Group Relative Policy Optimization).
EGM demonstrates that by increasing test-time computation, small vision-language models can outperform much larger models in visual grounding tasks while being significantly faster at inference.
| Model | RefCOCO val | RefCOCO test-A | RefCOCO test-B | RefCOCO+ val | RefCOCO+ test-A | RefCOCO+ test-B | RefCOCOg val | RefCOCOg test | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-VL-4B-Thinking | 90.0 | 92.7 | 85.6 | 85.2 | 89.5 | 79.3 | 87.0 | 87.7 | 87.2 |
| EGM-Qwen3-VL-4B | 93.5 | 95.1 | 90.0 | 89.7 | 93.1 | 84.9 | 90.4 | 90.8 | 90.9 |
VLMs of different sizes often share the same visual encoder. Small models fall behind large models primarily due to a gap in text understanding capabilities — 62.8% of small model errors stem from complex prompts with multiple relational descriptions. EGM mitigates this gap by generating many mid-quality tokens (from small models) to match the performance of large VLMs that produce fewer but more expensive tokens.
pip install -U huggingface_hub
huggingface-cli download nvidia/EGM-4B --local-dir ./models/EGM-4B
Launch the server:
pip install "sglang[all]>=0.5.5"
python -m sglang.launch_server \
--model-path nvidia/EGM-4B \
--chat-template=qwen3-vl \
--port 30000
Send a visual grounding request:
import openai
import base64
client = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
# Load a local image as base64
with open("example.jpg", "rb") as f:
image_base64 = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model="nvidia/EGM-4B",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_base64}"}},
{"type": "text", "text": "Please provide the bounding box coordinate of the region this sentence describes: the person on the left."},
],
}
],
temperature=0.6,
top_p=0.95,
max_tokens=8192,
)
print(response.choices[0].message.content)
| Component | Details |
|---|---|
| Architecture | Qwen3VLForConditionalGeneration |
| Text Hidden Size | 2560 |
| Text Layers | 36 |
| Attention Heads | 32 (8 KV heads) |
| Text Intermediate Size | 9728 |
| Vision Hidden Size | 1024 |
| Vision Layers | 24 |
| Patch Size | 16 x 16 |
| Max Position Embeddings | 262,144 |
| Vocabulary Size | 151,936 |
@article{zhan2026EGM,
author = {Zhan, Guanqi and Li, Changye and Liu, Zhijian and Lu, Yao and Wu, Yi and Han, Song and Zhu, Ligeng},
title = {EGM: Efficient Visual Grounding Language Models},
booktitle = {arXiv},
year = {2026}
}
This repository benefits from Qwen3-VL, InternVL, verl and verl-internvl.
Base model
Qwen/Qwen3-VL-4B-Thinking